
HTTP is the backbone of the web, but with the increasing demands of today’s ubiquitous usage, the protocol is starting to show its age. However, all is not lost as the IETF’s HTTPbis Working Group having been working on an update to the protocol, formally called HTTP/2, which is due to be published in early 2015.
Below, I’ll briefly cover what I consider to be some of the major points of interest in HTTP/2.
HTTP/2
One of the primary themes of the HTTP/2 specification is to reduce “perceived latency”: basically to reduce the amount of time the user sees between making a page request and it being rendered. This is achieved by fundamentally changing how the client and server communicate over the wire, which will enable features such as header compression, request multiplexing/interleaving and the ability for the server to push content.
The original HTTP/2 draft was based on SPDY, a protocol previously developed by Google. If you are already familiar with SPDY, you will see many similarities in the HTTP/2 specification. SPDY will continue to exist along-side HTTP/2, and in a reversal, the latest version is actually based on HTTP/2.
What’s wrong with HTTP/1?
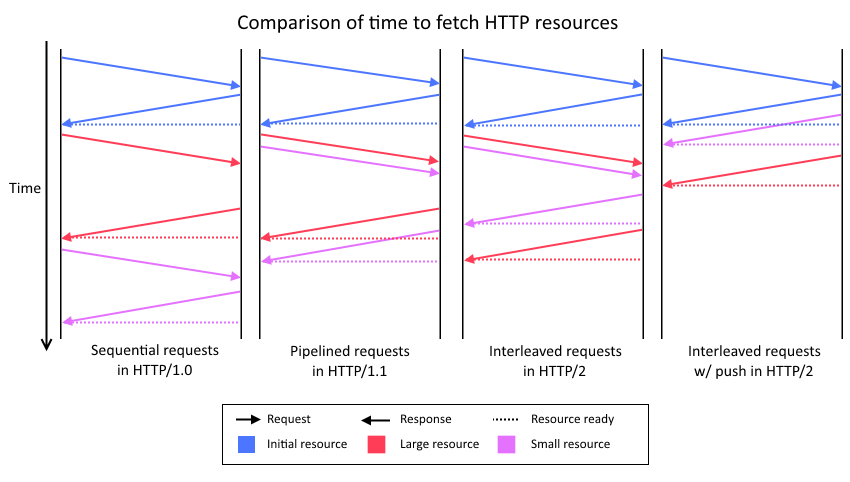
HTTP 1.0 was notoriously sensitive to high latency connections, as each request had to be made sequentially. If you wanted to make two requests, you had to wait until the first was completed before making the second.
HTTP 1.1 improved this, by enabling pipelining. Now if the user wanted to make two requests, they could send off both requests and then receive the responses back in order. However this suffered from head-of-line blocking, which mean trivial requests would get blocked until an earlier, potentially intensive or slow request completed.
Most browsers these days work around the above issues by opening multiple connections to a server. But this can lead to other problems, notably increased load, especially on the server.
HTTP/2 aims to address these issues by changing how the client and server communicate over the wire. To do this it introduces two new concepts: frames and streams.
Frames
Frames are the new basic unit of communication in HTTP/2 and replace the familiar header & body format of current HTTP requests/responses. Instead, each piece of communication between the client and server is packed up into a binary “frame” before it is sent over the connection. (The specification defines many “types” of frames - header frame, data frame, etc. You can read the full list and details of their usage in the HTTP/2 spec.)
So as an example, a client requesting a resource would send a headers frame to the server requesting the resource, the server will reply with a headers frame telling the client details about the resource, and finally the server will then send one or more subsequent data frames that can be used to construct the file.
One major advantage of this approach is that because the headers are now packaged into frames and treated equally to data, it allows for them to be compressed. Header compression has been a long requested feature, and should not only help reduce bandwidth usage, but should also reduce initial load times by a surprising amount because of TCP’s Slow Start mechanism.
Streams
Streams are another new concept in HTTP/2, and can be thought of as a logical single request/response communication. In reality, a stream is just a bi-directional sequence of frames that share a common identifier (a stream id). This enables interleaving of frames from multiple streams together, which allows for true multiplexed communication over a single connection - a big new feature.
Note that each logical request is given a stream id unique to that session, and to avoid collisions, any request initiated by the client uses odd number and even numbers for the server.
This fixes the “Head of Line” blocking that has plagued HTTP/1, as it means requests made on the same connection can now be responded to out of order. This not only lets the server make Quality of Service decision about what to return first, but it also means the client can now happily use a single TCP connection to make all their requests. As a result, the reduced memory, network and CPU load should be a big win for both the client and the server.
Server Push
Since a single connection is now kept open and used for all (bi-directional) communication, it also enables the server to push content to the client. This is achieved by the server sending a push promise frame to the client (on a new stream), which as the names suggest is a notification it is about to be sent a resource without requesting it.
Primarily, the push feature is intended for the server to send resources it know the client will need/is about to request, for example, images or scripts. This should be a substantial boost for people on high latency connections, as it effectively could remove multiple round trips to the server.
This may also lead to additional optimizations, as the server has the best information about which resources are the most important, even more so than the client.
Rest Stream
While the new server push feature is great, it may be less desirable for users in bandwidth limited situations, such as on mobile networks. To prevent servers from bombarding a client with data, the client can send a “rest stream” frame, which informs the server to stop sending anything over that stream (i.e. refuse a push promise). If the server continues to bombard the client with more pushes promises, the client can send a “go away” frame to stop the server creating any more streams.
The rest stream frame also has another great use, as it means if the user navigates to a new page on the same host, the existing connection can be re-used. The client simply needs to send a “rest stream” on all outstanding streams to avoid wasting bandwidth, and then send the new set of requests (over new streams). In HTTP/1, the only way to stop receiving already requested data was to drop the connection, which would cause additional latency while the connection was re-established.
Upgrading
If a client is connecting to a server and does not have prior knowledge that it supports HTTP/2, it can connect via HTTP/1 and request upgrading the connection to HTTP/2 if available.
This can happen in one of two ways:
If connecting over HTTP, the client should make a normal HTTP/1 request but additionally set some headers that inform the server it wishes to upgrade to HTTP/2 if available. If the server supports HTTP/2 (without encryption), it will respond with a 101 response (Switching protocols) and then start communicating over the connection in HTTP/2. If it does not support HTTP/2, the server effectively ignores the additional headers and processes the HTTP/1 request as normal.
If connecting over HTTPS, the protocol negotiation is handled by the TLS-ALPN extension, which causes the protocol to be decided during the TLS handshake.
Encryption
An interesting point, is that HTTP/2 was originally designed as an encryption only protocol. However, an outcry caused later revisions to support an optional plain-text version in addition to the encrypted form. But despite the removal of the encryption-only requirement, some browser vendors have said they will only implement the encrypted version of the protocol. At the time of writing, Firefox, Chrome and Internet Explorer all only have support for HTTP/2 when over TLS.
One side effect of the potential increase in encryption usage on the internet, is that it will make it impossible for ISPs to cache large common files more locally to users. Not only would this cause increased global network usage, but it could also cause increased load times for users, something the protocol was trying to reduce.
To combat this, a new concept called ‘Explicit Trusted Proxy’ was proposed, which is essentially a node along the connection which is allowed to decrypt and re-encrypt your traffic, for caching purposes. This has obviously caused a further outcry over privacy concerns, and while it currently does not have a resolution it looks unlikely the proposal will be adopted in its current state.
A Binary protocol
With all data sent over the connection being packed into frames, HTTP/2 has become a binary protocol. While this should be a big boost for machine processing, it will make it harder to debug requests over the wire. Tools like Telnet, just won’t cut it anymore.
While this may sound like a disadvantage of the protocol, increasing machine readability should not only help increase processing performance, but also will also help improve security. The text-based nature of HTTP/1 has been blamed for a few security issues in the past, ranging from Response Splitting to simply the complexity of knowing when a message ends.
Some tools have already announced support for the new HTTP/2 protocol, such as wireshark, and others are likely to follow. In reality, disruption for web developers will be likely be minimal.
Final thoughts
While HTTP/2 will provide some great new features that should help speed up the web, it doesn’t seem it will be quite as simple as dropping it in and expecting some of the promised speed ups.
It’s going to take some time to learn how to optimize sites correctly under the new protocol. For example, should we be moving all content onto a single server to take advantage of server push? Should we still try to bundle all script files up into a single file?
However, some benefits will be available immediately. The single TCP per client will reduce load on servers, but take this with a pinch of salt. This will also amplify things such as packet loss on the connection.
But overall, what’s clear is that because HTTP/2 can plug in silently beside HTTP/1, we’re going to see a slow and undramatic adoption over the next few years, possibly decades. The web will continue to do what it does: evolve.

