
This blog shows how to get started with microservices using Dropwizard. It guides the reader through building a simple task-list service.
Introduction
The year 2015 was definitely a ‘Year of Microservices’ in Java. It seems that microservices and technologies such as Docker and Dropwizard permanently changed how Java development is done. Developers familiar with Java application servers are facing a dilemma- if they already know how to do something in Tomcat, JBoss, or other application server, why would they spend time learning a new technology? Why chose something different than what is already well understood? As you will see in this example, not only the time investment of learning Dropwizard is small (compared to alternatives) it is also a rapid and lightweight framework for getting a web service up and running. There are numerous other advantages when deciding for Dropwizard over other options (and some disadvantages), but now it is not the time for that. What follows is Dropwizard in Anger, and Java microservice in just over 200 lines (counting the .pom) of code!
Project Idea - the TaskList service
The idea is to implement some non-trivial utility as a Java microservice. Checking what processes are running on a machine via a web service seems challenging and interesting enough. We want to be able to filter possible results (containing the word ‘Java’ for example) and limit the length of the process data exposed. This will help showcase some of the Dropwizard framework features. This example will show how a Java microservice can communicate with an arbitrary part of a system and expose it as an API. We know what we want to code, so it is time to get started. If you don’t like typing, feel free to clone/fork the github repository created for this project.
Project Settings - the POM file
We are going to use Maven for building this project. This is pretty much the standard in the Java world and since we will be writing these services from scratch- I assume that most readers will be free to use it. There are two key things to put in your POM. One is the Dropwizard dependency and the other is the build plugin, that will let us run this application as a single jar file. Executing a jar is the way Java microservices are supposed to be run. The code for the project follows:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>bjedrzejewski</groupId>
<artifactId>tasklist-service</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<dropwizard.version>0.9.1</dropwizard.version>
</properties>
<dependencies>
<dependency>
<groupId>io.dropwizard</groupId>
<artifactId>dropwizard-core</artifactId>
<version>${dropwizard.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.bjedrzejewski.tasklistservice.TaskListServiceApplication</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<appendAssemblyId>false</appendAssemblyId>
</configuration>
<executions>
<execution>
<id>make-assembly</id> <!-- this is used for inheritance merges -->
<phase>package</phase> <!-- bind to the packaging phase -->
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>Application Configuration
One thing that is familiar to anyone who had to work with Java application servers is the huge and hard to understand
configurations file or files. Here Dropwizard helps again. It defines plenty of sensible defaults
that we don’t have to worry about in this example and lets us decide exactly how the configuration will look like. For developers it may
not be scary to go through large XML’s, but for most users- this can make a difference between something they can change
themselves or asking for help. The language chosen for Dropwizard configuration file is YAML.
It is a very simple human-readable data serialization format. As you will see, to use it in the configuration file, you don’t
have to know much about it. We will call the configuration file tasklist-service.yml and let’s define the only variable
that we want users to set- maxLength for the query. The whole file reads:
maxLength: 100Now it is time to write the first Java code in this project. It is the TaskListServiceConfiguration class that is responsible
for reading the maxLength property and storing it’s value:
package com.bjedrzejewski.tasklistservice;
import io.dropwizard.Configuration;
import com.fasterxml.jackson.annotation.JsonProperty;
import org.hibernate.validator.constraints.NotEmpty;
public class TaskListServiceConfiguration extends Configuration {
private int maxLength;
@JsonProperty
public int getMaxLength() {
return maxLength;
}
@JsonProperty
public void setMaxLength(int maxLength) {
this.maxLength = maxLength;
}
}It is easy to see how one can extend this configuration class to take more parameters. It is using Jackson so if you are familiar with it, you already have a head start.
Data Model
Having a data model that can live both as JSON and Java object is very beneficial, as it lets the developers make full use
of the strong typing found in Java. The only item we will use in this API is a Task and it’s definition will be very simple.
It is also making use of Jackson:
package com.bjedrzejewski.tasklistservice;
import com.fasterxml.jackson.annotation.JsonProperty;
/**
* Created by bartoszjedrzejewski on 03/01/2016.
*/
public class Task {
private long id;
private String content;
public Task() {
// Jackson deserialization
}
public Task(long id, String content) {
this.id = id;
this.content = content;
}
@JsonProperty
public long getId() {
return id;
}
@JsonProperty
public String getContent() {
return content;
}
}Application Logic
Having dealt with the configuration (in less than 30 lines) and completing our simple data model, now is the time to write
the application logic. For Dropwizard, the resources are where most of the logic lives. These provide the endpoints (Web Services)
that will grant the access for the outside. Our task is to gather the processes that run on the system. Assuming that the
environment in which the project will be run is Unix / Linux based (or git-bash in Windows) you can get the active processes from
terminal with ps -e. If you are using Windows, feel free to customise the code.
This method combined with the server configuration and customisable user query will provide the
running tasks. The following code takes care of that while using SLF4J
and Google Guava libraries provided with Dropwizard:
package com.bjedrzejewski.tasklistservice;
import com.google.common.base.Optional;
import com.codahale.metrics.annotation.Timed;
import com.google.common.io.CharStreams;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.QueryParam;
import javax.ws.rs.core.MediaType;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicLong;
/**
* Created by bartoszjedrzejewski on 03/01/2016.
*/
@Path("/task-list")
@Produces(MediaType.APPLICATION_JSON)
public class TaskListResource {
private final int maxLength;
private final AtomicLong counter;
//SLF4J is provided with dropwizard. Logback is also provided
Logger log = LoggerFactory.getLogger(TaskListResource.class);
public TaskListResource(int maxLength) {
this.maxLength = maxLength;
this.counter = new AtomicLong();
}
@GET
@Timed
public List<Task> listTasks(@QueryParam("contains") Optional<String> contains) {
List<Task> tasks = new ArrayList<Task>();
String query = contains.or("");
try {
//Get processes from the terminal
Process p = Runtime.getRuntime().exec("ps -e");
BufferedReader input =
new BufferedReader(new InputStreamReader(p.getInputStream()));
//Dropwizard comes with google guava
List<String> lines = CharStreams.readLines(input);
//First line contains no data so it is omitted
for(int i = 1; i < lines.size(); i++) {
String line = lines.get(i);
//filter the processes depending on the ?contains= from the url
if(line.contains(query)) {
//trim the processes according to the maxLength
tasks.add(new Task(counter.getAndIncrement(), line.substring(0, Math.min(line.length(), maxLength))));
}
}
input.close();
} catch (Exception e) {
log.error("Exception in listTasks method.", e);
}
return tasks;
}
}The application is nearly complete. The only things left are to register the TaskListResource in the main class, build and test.
The main class will be called TaskListServiceApplication and doesn’t do much more than registering this resource:
package com.bjedrzejewski.tasklistservice;
import io.dropwizard.Application;
import io.dropwizard.setup.Bootstrap;
import io.dropwizard.setup.Environment;
public class TaskListServiceApplication extends Application<TaskListServiceConfiguration> {
public static void main(String[] args) throws Exception {
new TaskListServiceApplication().run(args);
}
@Override
public String getName() {
return "task-list-service";
}
@Override
public void initialize(Bootstrap<TaskListServiceConfiguration> bootstrap) {
// nothing to do yet
}
@Override
public void run(TaskListServiceConfiguration configuration,
Environment environment) {
// register resource now
final TaskListResource resource = new TaskListResource(
configuration.getMaxLength()
);
environment.jersey().register(resource);
}
}Building and running the application
With the application written (or cloned from github) all that is left
is to build it with mvn install. It is that simple, there is no extra step required. If you named everything the same
as I did, this will create: target/tasklist-service-1.0-SNAPSHOT.jar which you can execute as a standard jar file.
To run the application type in the main directory:
java -jar target/tasklist-service-1.0-SNAPSHOT.jar server tasklist-service.yml
And your first micro-service is running.
You can check it on: http://localhost:8080/task-list
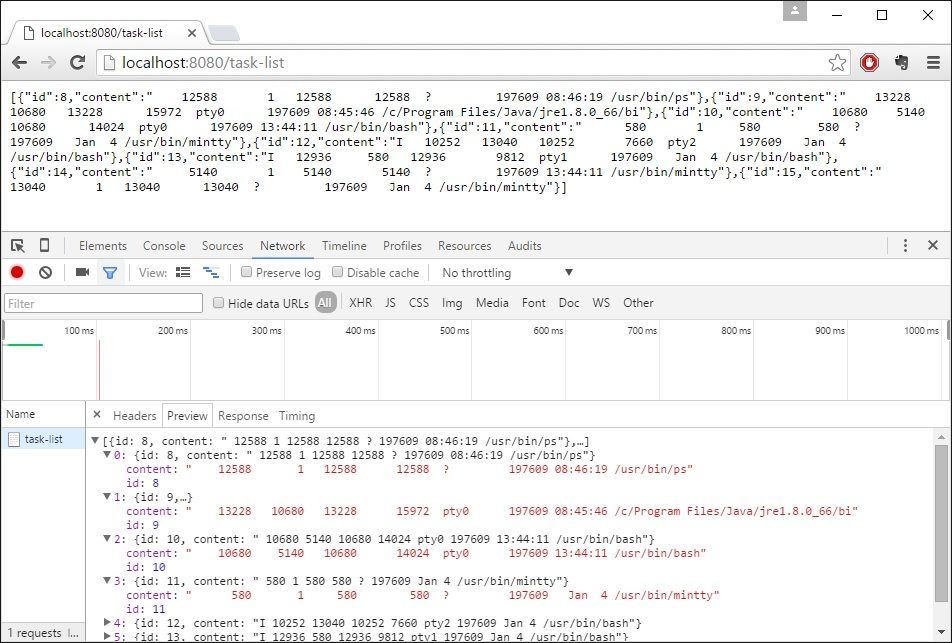
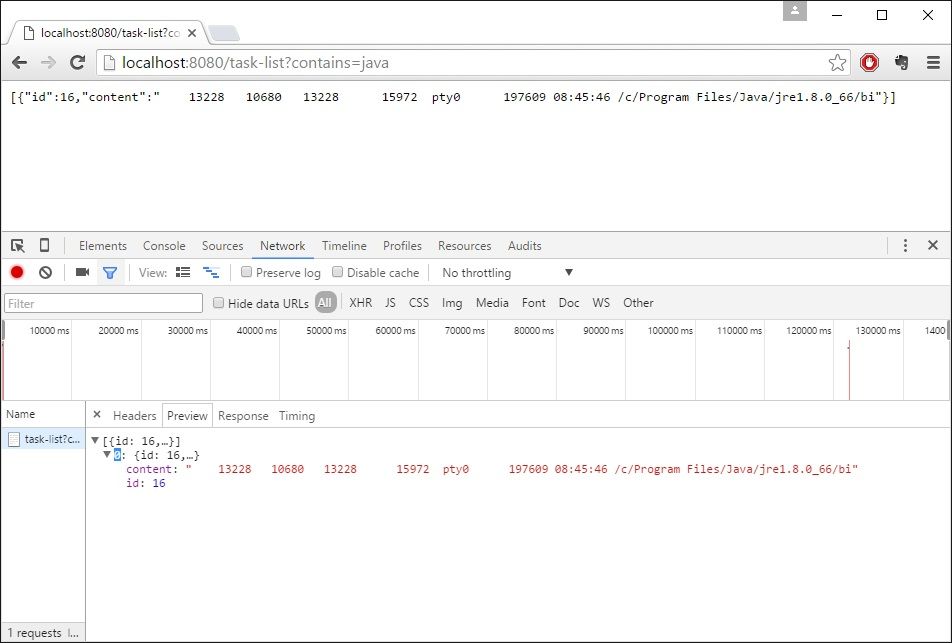
You can also filter only the process that contain ‘Java’ keyword: http://localhost:8080/task-list?contains=java
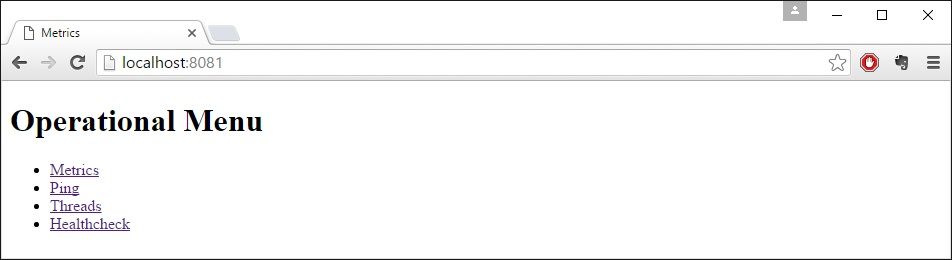
Or even see some server diagnostics on: http://localhost:8081/
Afterword
Congratulations on building your Dropwizard microservice! With this knowledge it should be easy to dive deeper, by reading the official documentation, hacking on your own or checking some of the popular books on the subject. I strongly believe that microservices are here to stay and hope that this introduction proved fun and useful.
