
What is ‘Big’ Data?
Big data is one of those buzz phrases that gets thrown round a lot, companies love saying they work with ‘Big’ data, but what is ‘Big’ data? When does data get so big that it can be called Big data? One Gigabyte? How about a Terabyte, or even a Petabyte? There’s no exact number as to when data becomes big, so I think of big data like this; Any amount of data that is too large or requires too much processing for a single machine. When the data gets this big, you have no option but to turn to distributed computing on a cluster of machines, and that’s where Hadoop and MapReduce come in.
Hadoop and HDFS
Hadoop is a project by Apache for storing and processing big data. Whilst there are several components to Hadoop, the key ones are the Hadoop Distributed File System (HDFS) and an API for creating MapReduce applications.
First, let’s explain what HDFS is and how it works. As you can guess by the name, HDFS is a distributed file system used by Hadoop. Files are split into blocks, which are then stored across multiple machines. HDFS has been designed for resilience and has many features that allow the system to keep running even when a machine fails.
A HDFS system has two types of nodes running in a master-slave system. These are the Namenode (master) and one or more Datanodes (slave). The Namenode manages the entire filesystem, it stores metadata about each file in memory, and it knows how the files have been split into blocks, and which blocks each datanode holds. Without the namenode, the filesystem is lost as there is no way of knowing how to reconstruct the data. The datanodes are where the work actually happens, they store the data and carry out the processing on it. They also periodically report back to the namenode with liveness checks and outputs from processed data. Losing a datanode does not cause the system to fail as each block is replicated on multiple datanodes, if connection is lost to a particular datanode, the namenode will assign the work to another datanode.
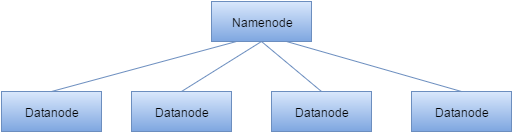
But wait, surely the namenode is a single point of failure!
You’ve probably noticed that if the namenode goes down, the whole system stops working, and we can’t recover the data from the datanodes. The Hadoop developers thought of this and created a third type of node called a secondary namenode, which despite its name, is not a backup namenode. The secondary namenode’s role is to merge the filesystem image with the edit log, this prevents the edit log becoming too large . The edit log is a log of all modifications to the filesystem since it was created. If the primary namenode fails, some data loss is very likely, but having the secondary node can help limit how much is lost. So we now have a way to store our data on a distributed filesystem with built-in redundancy, now we need a way to process this data, and that’s where MapReduce comes in.
MapReduce
The second key part of Hadoop is the MapReduce API and the tools for running and managing MapReduce tasks. The API was initially written in Java, but now there are libraries for C++, Python, Ruby and more. Each MapReduce application has two main functions; map and reduce. Each stage has a key-value input/output pair which is determined by the programmer. You can think of the map phase as filtering or parsing the data. The output of this is sorted by the key, and then passed to the reduce method. Each machine will run the same application, but on different blocks of data. Below is a diagram outlining the process. The lines show the flow of data, with the red lines representing data being transferred to another machine.

Once the map and sort stage is complete, the namenode determines how to distribute the work load for reduce. At this point the map output may be transferred to a different machine for processing, how the data is distributed is dependent on the size of the data and the number of machines in the cluster.
Enough theory, time for code
I’m going to walk through a very simple MapReduce application and how to setup Hadoop. By far the easiest way to setup Hadoop is to download a copy of Cloudera’s Hadoop quickstart VM. This is free, open source and contains everything you need to run a MapReduce application set up for you. Once that’s all up and running, we’re going to need some data to work on. Thanks to the internet, we’re spoilt for choice when it comes to large datasets, I’ve chosen the list of amazon movie reviews from the Stanford network analysis project. The Stanford page has lots of different examples if you want to play around with them. The code we’re going to write would work fine on the list of all amazon product reviews, providing you have the bandwidth, storage and patience for the program to run on so much data.
Code
Without further ado, let’s jump into some code.
Mapper class
Here’s our mapper class
public class ReviewsMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
public void map(final LongWritable key, final Text value, final Context context) throws IOException, InterruptedException {
final Pattern productIdPattern = Pattern.compile("product/productId: (.*)\n");
final Matcher productIdMatcher = productIdPattern.matcher(value.toString());
if(productIdMatcher.find()) {
final String productId = productIdMatcher.group(1);
final Pattern reviewPattern = Pattern.compile(".*review/text: (.*)");
final Matcher reviewMatcher = reviewPattern.matcher(value.toString());
if(reviewMatcher.find()) {
context.write(new Text(productId), new Text(reviewMatcher.group(1)));
}
}
}
}Our mapper class extends Hadoop’s generic mapper class with four parameters; input key class, input value class, output key class, output value class. The LongWritable and Text classes are Hadoop wrapper classes that are optimized for network serialisation, they wrap the Long and String class respectively.
Our map class is passed a key and a value. The key is the offset position in the file we read from, which we don’t use in this example. The text will be one product entry, we extract the product id and the review itself using regular expressions. The context.write() call outputs a key value pair where the key is the product id, and the value is the review text. This will be the input key/value pair for our reducer class.
Reducer class
Here’s our reducer class
public class ReviewsReducer extends Reducer<Text, Text, Text, IntWritable> {
/** Map containing the lengths of all the reviews. */
final Map<Text, List<Integer>> reviewsLengths = new HashMap<Text, List<Integer>>();
@Override
public void reduce(final Text key, final Iterable<Text> values, final Context context) throws IOException, InterruptedException {
List<Integer> reviewLengths = reviewsLengths.get(key);
if(reviewLengths == null) {
reviewLengths = new ArrayList<Integer>();
reviewsLengths.put(key, reviewLengths);
}
for(final Text review : values) {
reviewLengths.add(review.toString().length());
}
context.write(key, new IntWritable(getAverage(reviewLengths)));
}
private Integer getAverage(final List<Integer> values) {
Integer totalValue = 0;
for(final Integer value : values) {
totalValue += value;
}
return Math.round(totalValue/values.size());
}
}Our reducer class extends the Hadoop Reducer class which once again takes in four parameters representing the input and output key and value classes. For our program to work, our mapper’s key/value output class must match our reducers input key/value class.
You’ll notice one key difference between the map and reduce method parameters. The reduce method is given an Iterable<Text> value, as opposed to a single Text value. So for every product id we have one or more review, and each call to the reduce method will process the reviews for one product (the reviews for one product called be handled by multiple reduce calls if the size of the reviews was greater than the blocksize).
Once the map stage is complete, the output is sorted by the output key. This sorted output is then split and distributed to the reduce method throughout the cluster. Our map class is quite simple; it keeps a map that has stores the lengths of each review, once it has gone through all the reviews, it calculates the average and outputs that using the context.write call.
Main method
Finally, here is our main method to put it all together.
public class ReviewsAnalyser {
public static void main(final String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if(args.length != 2) {
System.err.println("Need to set input and output path");
System.exit(-1);
}
final Job job = createJob();
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
private static Job createJob() throws IOException {
final Configuration configuration = new Configuration(true);
configuration.set("textinputformat.record.delimiter", "\n\n");
final Job job = new Job(configuration);
job.setJarByClass(ReviewsAnalyser.class);
job.setJobName("Reviews Analyser");
job.setMapperClass(ReviewsMapper.class);
job.setReducerClass(ReviewsReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
return job;
}
}As you can see, the main bulk of this class is creating a Job, it’s here where we point to our Mapper and Reducer class, set the Job name and the class containing the main method.
At the top of the method we create a configuration and we set a property called “textinputformat.record.delimiter”. This tells our Hadoop program that every value entry is delimited with a double newline character. We have to do this as each review entry is multiple lines, with each one separated by a two newlines between them. If each review entry was on a single line, then there would be no need to create our own configuration here as the default delimiter is a single newline.
Running the example
The code and its maven file can be found on github. Checkout the code (or type it out yourself) and run the following to build the program:
mvn clean install
Now that we have some code you probably want to run the example, but there’s just one more thing we need to do first. We have the file containing the reviews on our machine, but we need this file to be on the Hadoop distributed filesystem. We can do this with the following command:
hadoop fs -put [path-to-movies.txt]
Finally, we’re ready to run the example with the following command:
hadoop jar ReviewsAnalyser-0.0.1-SNAPSHOT.jar com.scottlogic.reviewsanalyser.ReviewsAnalyser movies.txt output
Very important
The output directory will be created on the HFDS, not on your local filesystem. The output directory must not already exist, hadoop will not run if this is the case. The developers added this in on purpose to prevent accidental data loss. Now our program has run, we can view the output directory with the following command
hadoop fs -ls output
There should be two files there; _SUCCESS and part-r-00000. The first one is an empty file that lets you know that the program ran successfully. The second contains the programs output, for this example it should be a list of product ids with a number representing the average review length. We can view the output with the following command:
hadoop fs -cat output/part-r-00000
Or if we want to sort by review length then we can run the following
hadoop fs -cat output/part-r-00000 | sort -nk 2
For those unfamiliar with linux, the ‘|’ symbol is called a pipe. The output from the first command to the left of the pipe is passed into the second command. So here we use the ‘cat’ command to read the file, and we ‘pipe’ it to the sort command. The -nk 2 part is telling sort to sort on the second item (the review length).
When we run this we can see that the movie with the longest review is product id B001DDY604. You can search on amazon if you really want to know which film that is.
Summary
As you can see, with the Hadoop framework in place, we can create scalable, parallel, reliable applications with just a small amount of code. At no point did we have to code for parallel programming concepts such as threads or processes. With Hadoop in place, we can focus solely on the logic of the program and not have to worry about complicated implementation details. In the next tutorial we’ll be going over some of the higher level Hadoop tools such as hive and pig. With these we can work on data from traditional relational databases and query the data without having to write any code.

