
In Scott Logic we have an active group of big data enthusiasts. We also have a good number of passionate chess players. Thanks to these colleague I was made aware of the existence of the lichess games database. It is a (at the time of writing) a collection of more than 202,000,000 chess games available to anyone for free! The data from 2017 alone, after unpacking was over 100GB. Apache Spark is a perfect technology for making this immense data set easier to explore. In this blog post I will show how this data set can be reduced to the size that makes it explorable with Excel and show some interesting chess statistic that can be mined from it. If you are really impatient, you can checkout the code and download the Excel spreadsheet right now!
First look at Lichess data set
Lichess is an open source website where people of all skills can play chess together. As mentioned earlier, they also make all their games data accessible for everyone. This data comes in the PGN (Portable Game Notation) format and contains information about the players, the game conditions (time, event etc.) and the game moves. It looks like that:
[Event "Rated Bullet game"]
[Site "https://lichess.org/1xb3os63"]
[White "nichiren1967"]
[Black "Naitero_Nagasaki"]
[Result "0-1"]
[UTCDate "2012.12.31"]
[UTCTime "23:02:37"]
[WhiteElo "1765"]
[BlackElo "1815"]
[WhiteRatingDiff "-9"]
[BlackRatingDiff "+9"]
[ECO "C00"]
[Opening "French Defense: La Bourdonnais Variation"]
[TimeControl "60+1"]
[Termination "Normal"]
1. e4 e6 2. f4 d5 3. e5 c5 4. Nf3 Qb6 5. c3 Nc6 6. d3 Bd7 7. Be2 Nh6 8. O-O Nf5 9. g4 Nh6 10. Kg2 Nxg4 11. h3 Nh6 12. Ng5 Nf5 13. Bg4 Nce7 14. Nd2 Ne3+ 15. Kf3 Nxd1 16. Rxd1 h6 17. Nxf7 Kxf7 18. Rf1 h5 19. Bxe6+ Bxe6 20. Kg3 Nf5+ 21. Kg2 Ne3+ 22. Kf2 Nxf1 23. Kxf1 Bxh3+ 0-1
[Event "Rated Blitz game"]
[Site "https://lichess.org/6x5nq6qd"]
[White "sport"]
[Black "shamirbj"]
[Result "1-0"]
[UTCDate "2012.12.31"]
[UTCTime "23:09:21"]
[WhiteElo "1477"]
[BlackElo "1487"]
[WhiteRatingDiff "+12"]
[BlackRatingDiff "-11"]
[ECO "B00"]
[Opening "Owen Defense"]
[TimeControl "300+3"]
[Termination "Time forfeit"]
1. e4 b6 2. Bc4 Bb7 3. d3 Nh6 4. Bxh6 gxh6 5. Qf3 e6 6. Nh3 Bg7 7. c3 Nc6 8. Qg3 Rg8 9. Qf3 Ne5 10. Qe3 Nxc4 11. dxc4 Qe7 12. O-O Qc5 13. Qxc5 b5 14. Qxb5 Bxe4 15. Nd2 Bc6 16. Qb3 Bxc3 17. g3 Bxd2 18. Rad1 Bg5 19. Nxg5 hxg5 20. Qd3 h6 21. b4 Ba4 22. Rd2 Rb8 23. b5 d6 24. Qa3 Bxb5 25. cxb5 Rxb5 26. Qxa7 Rc5 27. Qa8+ Ke7 28. Qxg8 e5 29. Qh8 d5 30. Qxe5+ Kd7 31. Rxd5+ Rxd5 32. Qxd5+ 1-0
You can see vast amount of information here, but no easy way of querying it or filtering.
First look at Apache Spark
![]()
Apache Spark is technology targeted at quick processing of large amounts of data. When faced with more than 100GB this is exactly what is needed. You can find details of the installation on their website. Since I am Mac user with Homebrew all I had to do to install it is to run:
brew install apache-spark
after that I can run Spark shell with simple:
spark-shell
Installation was simple enough, the next step is actually being able to parse one of the data sets. I started by making a small Java program, where all that was needed in the maven file was:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>
The first attempted analysis was just counting the white wins, black wins and draws:
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.SparkSession;
public class ChessSparkMiner {
public static void main(String[] args) {
String pngFile = "/Users/bartoszjedrzejewski/github/chesssparkminer/lichess_db_standard_rated_2013-01.pgn"; // Should be some file on your system
SparkSession spark = SparkSession.builder()
.appName("Chess Spark Miner")
.config(new SparkConf().setMaster("local[2]")) //need to connect to localy running Spark
.getOrCreate();
Dataset<String> logData = spark.read().textFile(pngFile).cache();
long whiteWin = logData.filter(s -> s.contains("1-0")).count();
long blackWin = logData.filter(s -> s.contains("0-1")).count();
long draw = logData.filter(s -> s.contains("1/2-1/2")).count();
System.out.println("White wins: " + whiteWin);
System.out.println("Black wins: " + blackWin);
System.out.println("Draw: " + draw);
spark.stop();
}
}
This does not work very well, as the actual result appears at the end of the game, in the metadata and can
appear in other places (for example usernames). The main issue here is that Spark by default splits by line. This is
not what we want and it can be easily fixed by splitting on some other distinct part of the file. I chose the "[Event"
which starts the metadata. Code for doing that smarter split is as follows:
SparkConf conf = new SparkConf()
.setAppName("Chess Spark Miner")
.setMaster("local[2]");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("INFO");
sc.hadoopConfiguration().set("textinputformat.record.delimiter", "[Event");
JavaRDD<String> pgnData = sc.textFile(filePath);
With this out of the way, we are ready to start looking at this dataset seriously!
Processing Lichess Dataset with Apache Spark
My first approach was to try to get the interesting data from that dataset directly with Spark. This resulted in some complicated code that would take some minutes to run on a massive dataset producing results that I could not do much more with. Example of that is trying to rank chess opening by their performance at different level of play. You can see the code written for that in this commit What I am doing there essentially is splitting the dataset:
JavaRDD<String> ultraBullet = pgnData.filter(a -> getSpeedMode(a).equals("UltraBullet"));
JavaRDD<String> bullet = pgnData.filter(a -> getSpeedMode(a).equals("Bullet"));
JavaRDD<String> blitz = pgnData.filter(a -> getSpeedMode(a).equals("Blitz"));
JavaRDD<String> classical = pgnData.filter(a -> getSpeedMode(a).equals("Classical"));
followed by:
JavaPairRDD<String, ScoreCount> openingToGameScore = pgnData //take some of the already filtered data
.mapToPair(game -> new Tuple2<>(getOpening(game), new ScoreCount(getScore(game), 1))) //map each game to opening and extracted score
.reduceByKey((score1, score2) -> score1.add(score2)); //reduce the dataset by merging scores
This worked ok, but was inflexible. However, it gave me idea on how to work successfully with a dataset like this. I was interested in specific categories here (namely the speed of play in the games), but there were other categories that I would like to mix and match. If I could reduce the data to about 200,000 rows/categories then I could do the rest of the investigation from Excel. This idea is partially inspired by OLAP cube and my great admiration for Excel Pivot Table functionality.
The approach I took was to create a GameKey out of every game that would contain:
private final String opening; //the opening being played
private final String eco; //the eco code of the opening
private final String tempo; //speed of the game - blitz, bullet, standard
private final String avgEloClass; //average level of players as a category
private final String ratingDiffClass; //difference between white and black player as a category
Using that key I have with 365,009 categories- a number that you can deal with in Excel Pivot table. Each of these
categories is being described by a ScoreCount object that contains:
private final double score; //total amount of points from this category (for white)
private final double count; //total number of games
private final double drawCount; //number of draws
private final double whiteWinCount; //number of white wins
private final double blackWinCount; //number of white wins
private final double sumWhiteElo; //sum of white player rankings (can get average by dividing by count)
private final double sumBlackElo; //sum of black player rankings (can get average by dividing by count)
This gives the first few rows of the data as follows:
opening|eco|tempo|avgEloClass|ratingDiffClass|averageScore|score|count|drawCount|whiteWinCount|blackWinCount|averageWhiteElo|averageBlackElo|sumWhiteElo|sumBlackElo
?|A02|Bullet|1600-1799|White+200|0.0|0.0|1.0|0.0|0.0|1.0|1763.0|1660.0|1763.0|1660.0
King's Pawn Opening: 2.b3|C20|Blitz|1400-1599|Black+200|0.2915287888815354|440.5|1511.0|41.0|420.0|1050.0|1418.5949702183984|1590.5771012574453|2143497.0|2403362.0
Gruenfeld Defense: Exchange Variation, Spassky Variation|D87|Classical|2400+|White=Black|0.5|0.5|1.0|1.0|0.0|0.0|2465.0|2435.0|2465.0|2435.0
Sicilian Defense: Boleslavsky Variation|B58|Bullet|1600-1799|White+200|0.6|3.0|5.0|0.0|3.0|2.0|1756.0|1602.4|8780.0|8012.0
Format that can be read as a delimited file by Excel and analysed in depth!
Final words on Spark
Using spark to process the data and prepare the resulting dataset was very interesting experience. Once you get familiar with the map-reduce style of Spark it feels very natural. I think it is a suitable tool to transform your data and make it ready for analysis by less efficient, but more user friendly tools. I was surprised by the speed and performance of the Spark itself. I never really had to worry that I am dealing with tens of gigabytes of data- it just worked flawlessly. The final code that I used to prepare that dataset can be downloaded from my github repository. I used the ‘processPGNFile’ method to process the raw data and ‘consolidateOpeningFiles’ to connect the multiple outputs and turn it into one master spreadsheet.
Chess Insights
This part is especially for fellow chess players who are interested in the actual data and findings. I am not aware of a similar scale analysis of online blitz data, so hopefully you will find something new and interesting for yourself here!
How reliable is the rating system?
The first question I was interested in investigating was if the rating system works equally well for low and high rated players? In principle 1400 vs 1200 should score just as well as 2200 vs 2000, but I was always unsure if this was indeed the case. To find out answer to that question I have plotted results from different uneven encounters against overall rating average of both players:
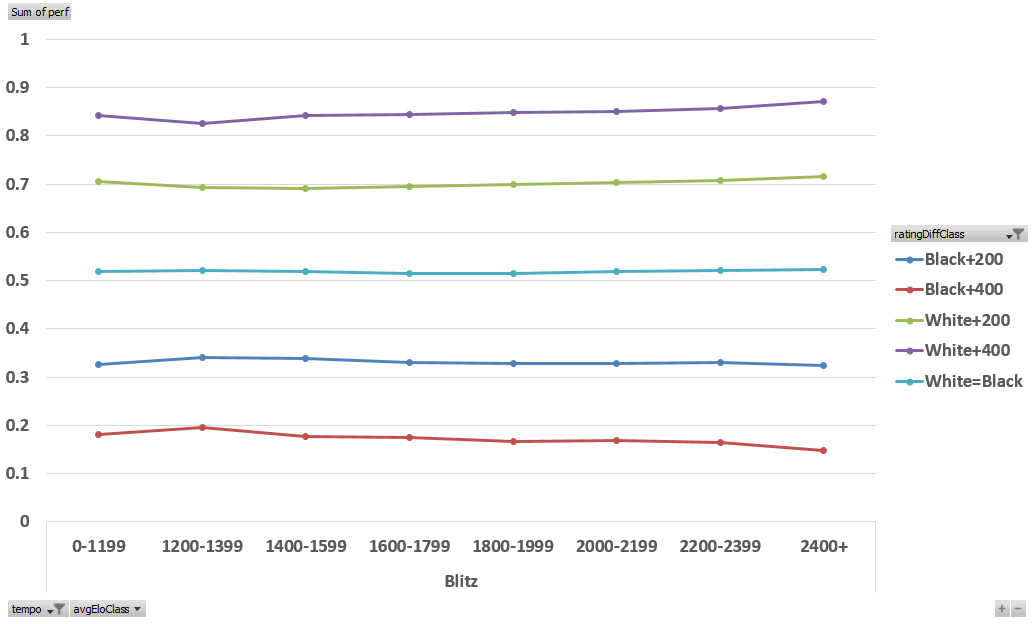
Based on 36,000,000+ games used for this analysis- it works very well!
Which openings are the most popular?
The other obvious question is- what are the popular openings out there? Are players rated ~1400 play the same systems as the 2400+ rated crowd? Obviously not. The analysis here will be about the most popular variation, not really opening as a whole (Sicilian Defense is not counted as one, but as many different separate Sicilian Defense variants). Looking at analysis with regards to specific groups of opening would be another interesting way to look at this data.
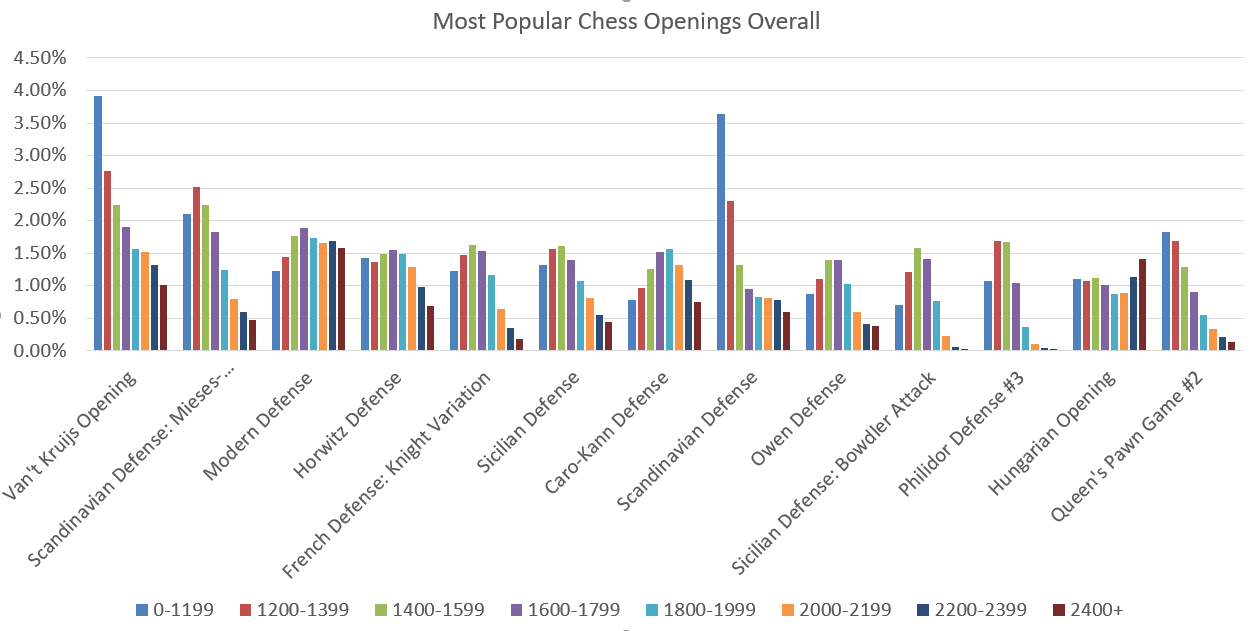
Looking at this data it is quickly obvious that Scandinavian Defense is not as popular on higher level of plays as it is among amateur players. Most of these openings lose popularity as ratings increase. Let’s have a look at what the really strong players are choosing:
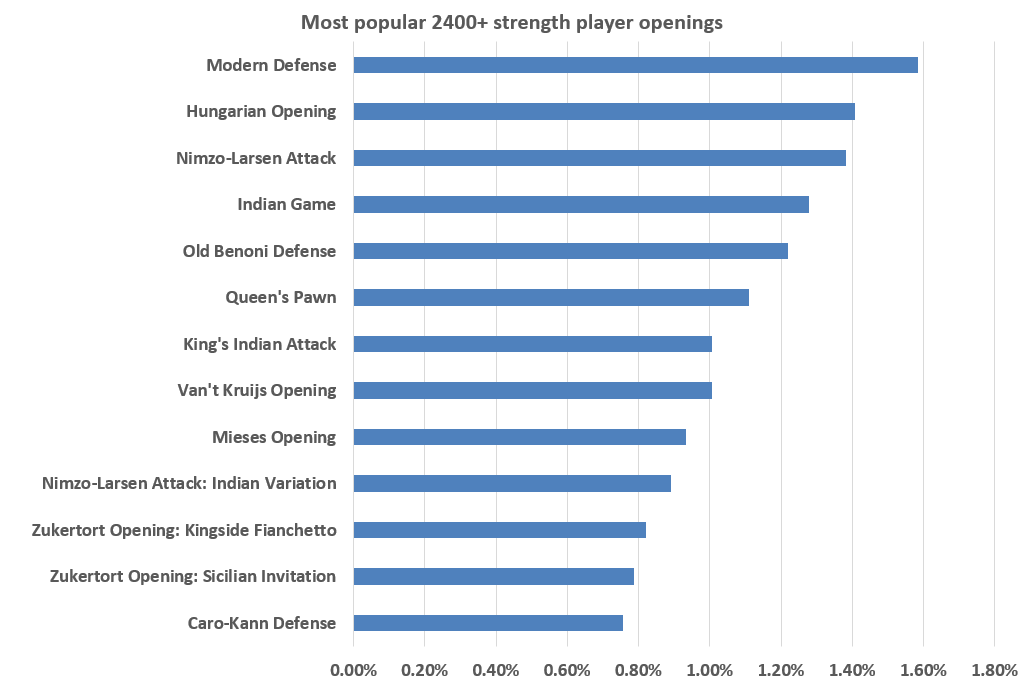
Here Modern Defense and Hungarian Opening are dominating the table. It seems that on the higher end of the blitz levels people prefer less theoretical openings. If we filter for only slower games:
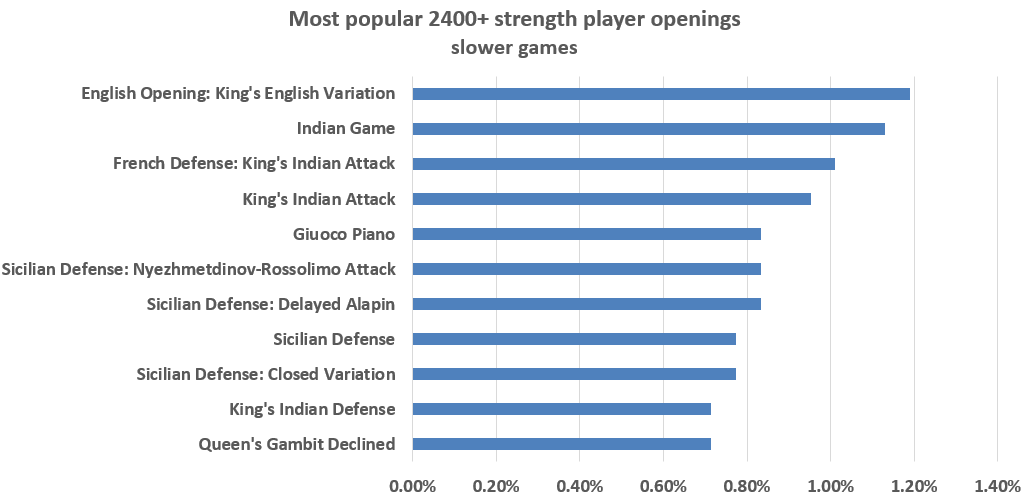
We can see more familiar and theoretical openings at the top of the 2400+ players preferences.
Look at openings performance
One thing that excites many chess players are debates- which openings are the best, what should be played etc. Here I want to investigate performance for responses against e4 different than e5. The openings I chose to look at are:
- Alekhine Defense
- French Defense
- Sicilian Defense
- Caro Kann
- Modern Defense
As I am a Sicilian Defense player, I know which opening I am rooting for! I will compare these results to what is expected on average from black. I created two separate charts- one for blitz and one for classical, as there are significant differences with how these opening fare at different speeds. I also did not have enough (100’s not 1000’s) of 2400+ classical games in the data set to make the analysis good enough:
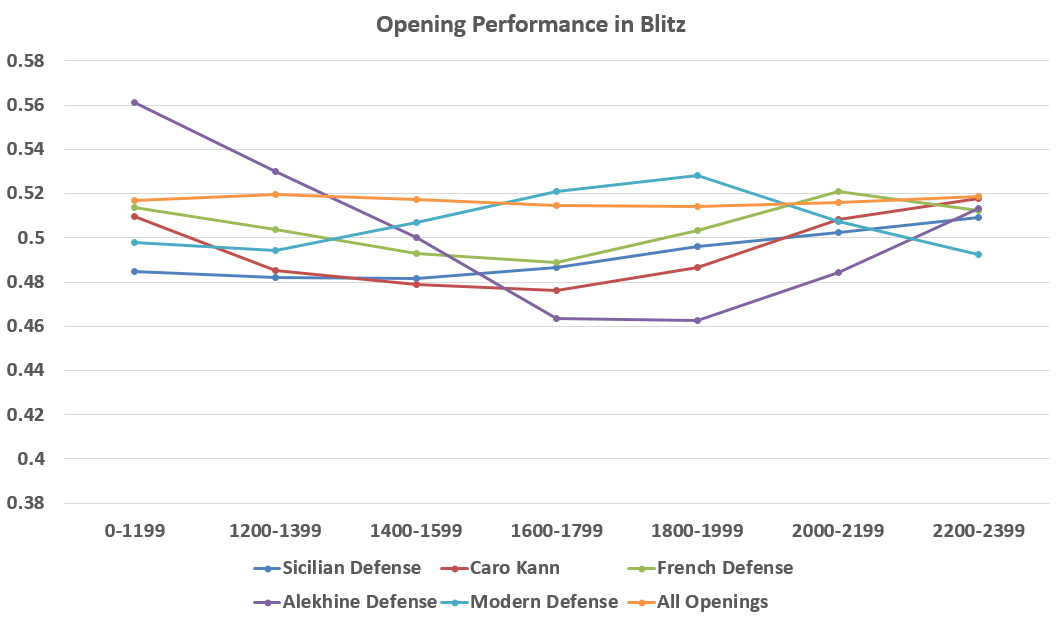
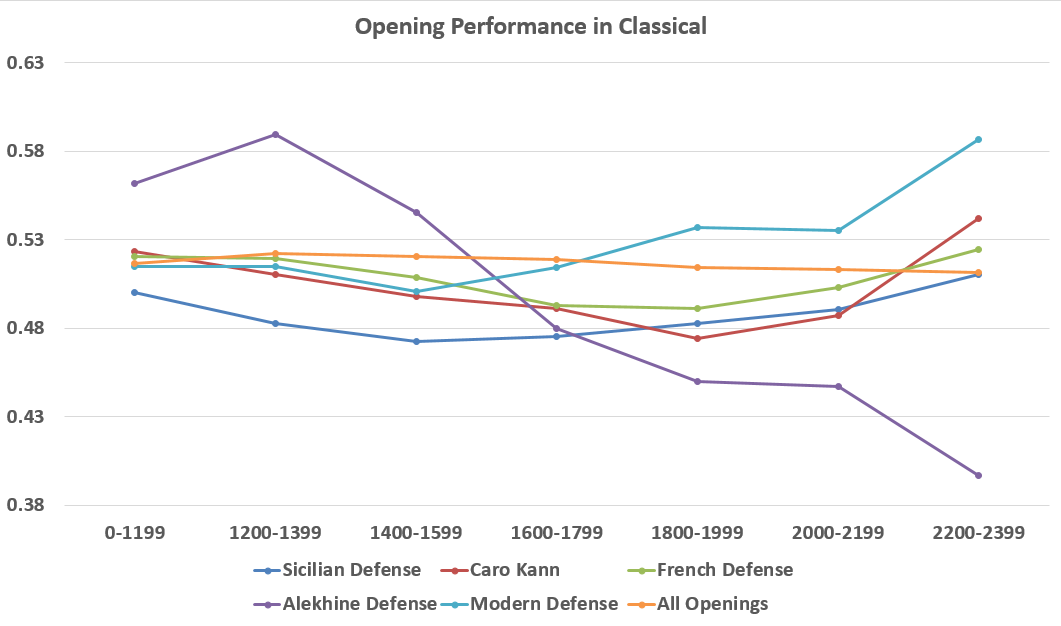
The lower on the chart, the stronger the better the opening does for black… And it seems that Alekhine Defense is an excellent choice, especially in classical games! As somewhat expected, Sicilian Defense does very well being the most popular of these choices among all chess players.
And since I work in Scott Logic and King’s Gambit is an ever popular opening among many players here I have to provide some statistics on that as well!
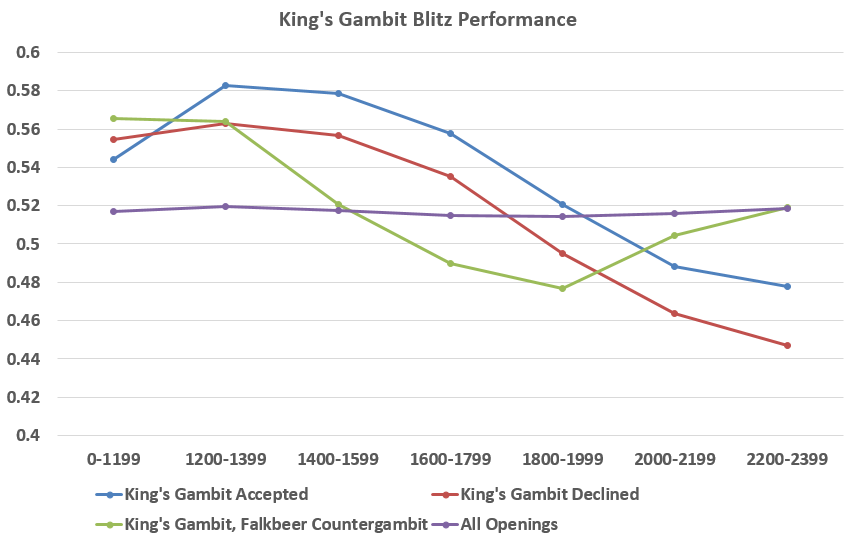
It is a solid opening up to 2000 level, with not enough data above 2400 to make a decent analysis. It is definitely a joy to play!
Conclusion and what is next
I really enjoyed using Apache Spark and working with the amazing lichess dataset. I feel that I have only scratched the surface of what exciting facts can be mined from that dataset. I encourage you to download the spreadsheet yourself and share your insights and findings!
On the purely technical side- I have only focused on the metadata and did not make use of over 2,000,000 games in that dataset with computer analysis attached, or even more games with the move time information. Which are the slowest openings to play? Which ones produce most blunders? A colleague of mine started looking into most common blunders in King’s Gambit to search for possible traps! If you have an idea what else can be mined from this data set, or even better- you did some research, please share with us in the comments, or let me know on twitter! Good luck in your Data Engineering and Chess!

