
When using MongoDB as a data persistence layer, there comes a point when increasing the specifications of a single machine no longer yields the return in performance that is needed. MongoDB seeks to mitigate this issue, by splitting the persistence layer across multiple machines, and offers a sharded cluster feature to facilitate this.
In this post, we will explore three factors that should be considered before making the transition:
- Sharded clusters introduce additional deployment and maintainability costs, so you need to evaluate whether it will be beneficial.
- The performance of a sharded cluster is primarily based upon how the data is split between machines, therefore you need to understand the typical usage patterns of your applications.
- When machines or large batches of data are added to an existing cluster, background loads are introduced to split and distribute data.
Introduction to Sharded Clusters
MongoDB contains a database server component that is responsible for persisting data and carrying out queries on that data. With this component on a single machine there are operational concerns as this introduces a single point of failure. MongoDB’s replica set feature comes to the rescue, and allows ‘secondary’ machines to replicate the data on the ‘primary’ and be ready to take over on a failure.
Whilst a replica set can alleviate some operational risks, and are typically found in all MongoDB production environments, they do not aim to split data or the workload across the machines. This is where sharded clusters feature come in, as this feature enables a replica set (or a single database instance) to become a shard.
Each shard in a sharded cluster exclusively holds onto a set of chunks. These chunks describe a subset of the data stored and can be migrated from one shard to another, either to maintain an even distribution of data or to handle shards being added or removed from the cluster. It is this distribution that provides you with the performance benefits, as data interactions can be routed to a single shard, reducing the load on other shards.
Consider: Will the benefits outweigh the costs?
If you are not currently using a sharded cluster in MongoDB, you are forced to increase the specifications of your replica set machines to cope with additional load. For some systems this approach works well, but there does come a point for some where this does not become worthwhile.
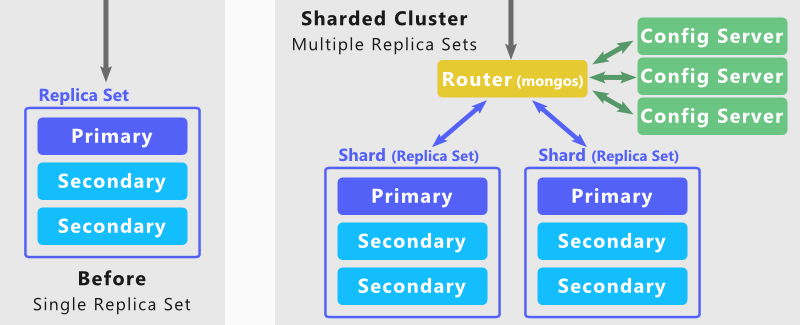
Before you can bring a production MongoDB system over to using a sharded cluster, there are additional costs that you need to bear. Not only do you need to duplicate your existing replica set, but you need to set up the following:
-
A configuration server is essential for mapping data chunks to shards. A sharded cluster cannot function without this, so you should set up three of these servers in production and have a data backup strategy.
-
A router server routes actions triggered by your applications to the correct shard. In a production environment it may be necessary to have multiple of these to handle fail-over.
In order to evaluate whether this is the right choice for you, the most important action for you to take is to be collecting performance metrics over time. The data you generate should allow you to forecast resource requirements – volatile memory (RAM), storage requirements, processor speeds and disk I/O speeds.
Your ability to make forecasts is important, for you need to see whether it is cheaper to have the hardware requirements you need all on a single machine or whether it is more financially viable to spread your requirements over several machines. There are only so many cores that you can fit in one machine and only so much I/O you can transfer from a single machine, so technology may force your hand in the future and require you to think about transitioning to a sharded cluster.
Consider: How should data be split into chunks?
A shard key acts as an index over your data and is needed to create a sharded cluster. When setting up a sharded cluster, this shard key is broken up into chunks by MongoDB - using a configurable data storage criterion.
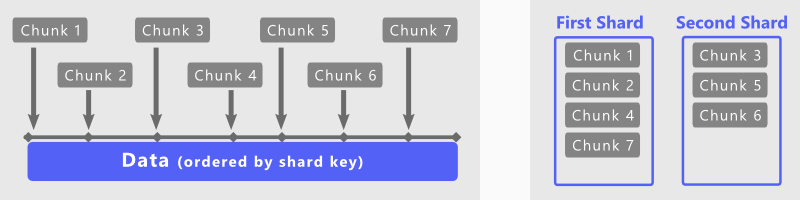
There are three aspects to consider when defining your shard key:
Firstly, the read and write queries should be spread evenly across all the shards without any biases. When done right, this resolves issues regarding write contention, as the writes are shared across the shards.
Secondly, each read or write should only target an individual shard. For the shard key, this would mean that it needs to order the data in such a way that results returned by common queries are close together. This is useful for ranged based queries as there is a lower overhead collating data from one shard compared to multiple shards.
Finally, the shard key value should be distinct across the data. This is important to consider, as data with the same shard key value will always be kept in the same chunk.
Meeting all these criteria tends to be infeasible in real world systems, so you need to base your decisions on the typical usage patterns of your data. When your system goes into production the performance of your shard key should be regularly monitored, as this should give you insight about your current usage patterns and help you be proactive when these patterns change.
Consider: What is the impact of maintenance tasks?
As part of the sharded cluster feature, MongoDB employs a balancer to distribute chunks evenly between shards. Whilst this helps keep the overall system scalable, there is an additional load placed across the sharded cluster when chunks are transferred.
A side effect of this is that when machines are added or removed from a sharded cluster, the balancer is going to move chunks between shards. This is another motivator for monitoring performance metrics, as you can the rebalance data before your system reaches a performance bottleneck.
Chunks can also be split in two and distributed on the fly when certain data storage thresholds are crossed. This means that when a large amount of data is being added, the balancer is adding data to chunks that are going to be split as more data comes in and then these new chunks will get transferred to another shard – all of which introduces additional load.
If you can predict the amount of data you will be receiving and the range of values your shard key will have, it may be possible for you to manually split chunks beforehand. By doing so, the data will be written to a chunk that is unlikely to be automatically split or transferred to another shard.
What have we discovered?
So far, we have looked at the key considerations you need to make before transitioning over to a sharded cluster. What we have seen is that there is a tremendous amount of value in collecting performance metrics as they allow you to evaluate your current resource usage, make forecasts and anticipate future performance bottlenecks. We have also seen that the transition to a sharded cluster introduces an additional deployment and maintainability cost and that the addition or removal of a machine can add an additional load. Finally, we have touched upon what a shard key is and how this one choice defines the types of performance benefits you can receive from a sharded cluster.
However, there is one thing we have not seen. Up until this point I have been vague about how performance metrics are collected and how you can use them, so in the next post on “Sharded Clusters in MongoDB” I look to address this. I will walk you through the performance metrics I have gathered when creating my own sharded clusters, what you can do with these metrics to forecast hardware requirements and how you can proactively identify performance bottlenecks ahead of time.

