
A few days ago the roadmap for future Angular releases, starting with v.4 in March 2017, was unveiled. It once again made me re-visit my personal doubts about semantic versioning, the underlying issue being that it is great for computers, but bad for humans. Considering that people are the primary consumers of your libraries and frameworks this can’t be right? Perhaps a hybrid approach that combines both semantic and romantic versioning would keep both the computers and the humans happy?
Let me explain …
Great for library authors
Semantic versioning (semver) has been embraced by development communities across a wide range of languages. If you’re unfamiliar with the concept, I’ll give a very brief overview. Software is versioned using three different numbers, MAJOR.MINOR.PATCH, e.g. 1.3.2. The semver specification defines when these should be incremented:
- PATCH – for backwards-compatible bug fixes
- MINOR – for backwards-compatible addition of new features
- MAJOR – for incompatible changes
These rules are precise, and for the author of a library provide an easy and entirely unambiguous mechanism for managing versions.
Within the JavaScript world, where Angular lives, this scheme is widely used, with npm creating 1.0.0 packages by default (as a way to discourage 0.x releases that have weaker semantics), and tools like semantic-release (https://github.com/semantic-release/semantic-release) making it easy for library authors to manage version increments and create change logs.
For library authors this is great!
Let’s take a look at the experience of the consumer.
Active and Passive version increments
There are only two ways that the version of a library that you depend on can be updated, either passively or actively.
If you use range specifiers (such as tilde or caret) for your dependencies, you are allowing the computer to determine whether a dependency can be updated. For example, if you use a tilde to define a dependency on version ~1.0.1 of a library, a patch update in this same library to 1.0.2 matches this version range and your dependency will be updated.
While in principle it might sound like a great idea to passively accept minor or patch increments, which provide bug fixes or add new features that are strictly backwards compatible, I’m not so keen in practice.
Regarding patches, I like my applications to be deterministic. I dislike the notion that if I have the same application on my dev machine, and you have the same on yours, that the two could behave differently due to patches in dependencies. I’ve had this happen a few times before. It’s not fun.
And regarding minor updates that introduce new features? Passively accepting these seems somewhat futile. Unless you update your code, these new features will be unused.
In summary, I’d rather not allow passive updates. While you can control your direct dependencies, specifying explicit versions rather than version ranges, you may still end up passively accept updates of your transitive dependencies due to them using version ranges. This is why shrinkwrap exists, to lock everything down.
Well that deals with passive updates, what about active?
An active version increment is where you, a human, decides to update a dependency. In this context an increment in patch version is actually quite useful, I like to know that my dependencies are now better, more stable, less buggy – and at certain points in my app development cycle, where I have time to integration test, I gladly accept these.
But minor and major updates? in order to sensibly accept a minor update that includes new features, I need to change my code. And for a major update? The same applies, I need to change my code.
The big question is by how much will my code need to change? And what value will these changes deliver?
In brief, I don’t buy into passive updates, and for active updates patch version increments provide some value, but the differentiation between minor and major provides little benefit.
I am guilty too
As a library author I very much like the sound of semver, and with the semantic release utility in our tool-belt our open source charting project d3fc, reached version 12 in around one year. Whilst a double-digit major version number did strike me as mildly ludicrous for a relatively new project I was please to be following the standard!
However, while most of our releases have included some very minor breaking changes, causing us to increment the major version numbers, these have largely been trivial breakages.
That was until our v12 release which was a major re-write with wide-spread API changes, in part fuelled by our most significant dependency D3 moving to a new major version.
Again, we used semver and incremented the major version, however I did feel that this did a very bad job of communicating the extent of the change.
Easy for me as a library author, but not so great for our (human) consumers.
Pre-semantic versioning
Prior to the rise in popularity of semver, we used to use major, minor and patch versioning but they had a different, and less precise meaning. While patch version increments were generally used for bug-fixes, both minor and major increments could include breaking changes. Which you incremented was a signal to your consumers regarding the extent of the change.
In some ways this versioning is more ‘semantic’ in that it is true to the definition of what the words major and minor actually mean, when viewed from the eyes of the consumer.
This approach to versioning, which is a little fuzzy, has been dubbed romantic or sentimental.
There are still people that adhere to a versioning approach that conveys magnitude. One example is the library underscore, where the author met with a lot of objections when the move from 1.6 to 1.7 was found to include breaking changes!
Back to Angular
The move to semver for Angular (2!) is a great illustration of the issues with this approach. The change from Angular 1 to 2 was significant, they are effectively different frameworks, sharing common concepts, but having entirely different APIs.
One month ago when the team started to talk about releasing Angular 3 in early 2017, in anticipation of the panic, a number of people very quickly published posts telling people not to worry this was not going to be an Angular 1 to 2 style transition.
Their milestone page on GitHub confirmed this:
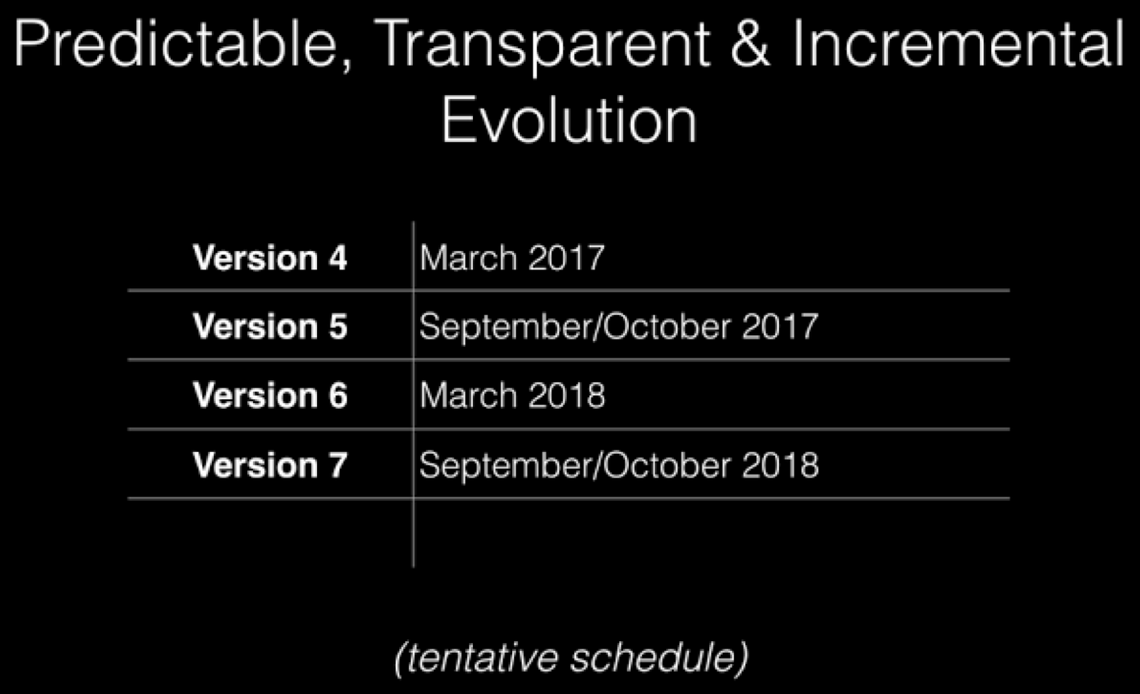
Since then things have progressed further, with the team detailing their future plans to release major versions twice a year.
They are also encouraging people to drop ng2 project prefixes and simply call the framework Angular from now on.
When I saw this plan, I did the only sensible thing. I grumbled about it on Twitter.
Thankfully Chris Eidhof directed me to a fantastic video from Rich Hickey on the subject of change. The video goes far beyond criticising semver, instead he takes a detailed look at what change is, focussing very much on the perspective of the consumer. It’s well worth watching. I’m going to watch it again and take notes next time.
A couple of messages in the talk that resonate with me is that we should focus on ‘growing’ our software rather than changing or breaking it. Also, from a functional programming mindset we should view our library as being immutable. A breaking change isn’t a change at all. It is the creation of a new thing!
Conversely semver almost encourages us to change things and break them. Because we can.
Semantic and romantic
So what’s the solution to this problem?
Clearly many people (and even more computers!) derive value from semver, so I would not advocate that anyone stops using it. However, there is still a need to be able to convey the magnitude of change.
So why not just use a combination of both?
Using Angular as an example, as well as using a semantic version number, a (romantic) name could be used as well. The difference between Angular 1 & 2 is huge, a real paradigm change, so requires a new name. Whereas, future major increments, while breaking changes, are likely to be relatively minor. However, at some point in the future we may see a similar significant re-write.
Perhaps we could use the names “Obtuse” for Angular 1, and “Acute” for Angular 2, and maybe “Isosceles” for some future significant change:
Angular 1 - Obtuse
Angular 2 - Acute
Angular 3
Angular 3.1
Angular 5
Angular 5.0.1
Angular 6 - Isosceles
Angular 7
(Yes, these names are pretty terrible, but you get my point!)
And as for d3fc?
Will we use this hybrid romantic / semantic approach? I’m not sure. For now, after watching the talk by Rich Hickey, I’d like to stay at version 12 for as long as possible!

