

Frequently I’m asked what all the hype behind this Big Data nonsense is about. To some extent I think dropping the ‘Big’ would get more buy in from developers. Streaming architectures supported by technologies such as Kafka, Storm, Spark and Flink can really scale to the Big in Big Data, however we’re missing the real use case. These architectures enable us to alert end users in real time of significant events, for example consider a use case where we alert users when air pollution becomes unacceptable.
What we used to do (and sometimes still do …)
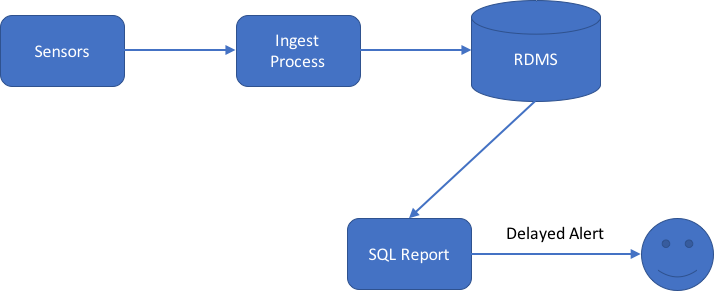
Throughout the day we feed our sensor readings through an ingest pipeline into our relational database. Periodically we run an SQL query something like the following:
SELECT *
FROM
(
SELECT timeBucket, AVG(reading) pollution
FROM SensorReadings
GROUP BY timeBucket
)
WHERE pollution > 75.0 /* bad value */
ORDER BY timeBucketBut what’s wrong with this?
- Sure we’ll eventually figure out that the air pollution went above an acceptable level but not until our next execution of the query.
- Relational databases typically sit on one machine; there is a limit to the amount of storage and compute we can put on this box. I.e. we can’t scale to IoT levels of sensors. Also before that we’ll hit a point where we need multiple ingest processes that we have to deploy and manage.
What innovating companies are currently doing

Kafka is a message broker that scales across machines and provides resilience, lose a machine and you don’t lose any of your data currently in the pipeline. Combine this with a processing engine such as Apache Spark and you can scale to IoT proportions. Spark Streaming allows you to micro batch enabling you to perform calculations over the past time window and alert immediately if the pollution is high. This core Spark logic looks something like the below:
object Spark {
private case class Measurement(time: String, pollution: Int)
def main(args: Array[String]) {
// Running in local mode, in production we'd run on a cluster
val conf = new SparkConf().setAppName("Pollution Monitor").setMaster("local[*]")
// Setting the batch interval over which we perform our pollution average calculation
val streamingContext = new StreamingContext(conf, Seconds(10))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "pollution_consumer",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// Creating a stream to read from Kafka
val topics = Array("pollution")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
// Calculate the pollution average over the last interval
stream.foreachRDD { rdd =>
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val row = rdd
.map(_.value.split(","))
.map(attributes => Measurement(attributes(0).trim, attributes(1).trim.toInt))
.toDF()
.agg(avg($"pollution") as "pollutionAverage")
.filter($"pollutionAverage" > 75.0)
.foreach(row => println("Raise alert for pollution level: " + row(0)))
}
streamingContext.start()
streamingContext.awaitTermination()
}
}But again what’s wrong with this?
- Spark micro batches on processing time, i.e. the time the event is observed by the machine processing it, not event time, i.e the time the event actually originated. This has big implications for our pollution level monitoring. Let’s say a bunch of sensors go offline for a few seconds and then suddenly come back up and start sending buffered data from that down period. This could get processed along with a later window’s data giving us erroneous air quality readings.
- While Spark can scale to IoT proportions, its scaling ability is not independent of the window size. If you have high data throughput, you need to measure in windows of at least 10s of seconds. This doesn’t seem right, sometimes we want small windows.
The future?

Take Spark Streaming, layer on logic for processing windows based on event time and remove the dependence on window size for throughput and you’ve got Apache Flink. It has a similar relationship with Kafka and it looks and feels like Spark. The ideas behind processing based on event time came out of Google Cloud Data Flow but with Flink you get the open source implementation. Let’s specify that ordinarily sensor readings don’t arrive more than 2 seconds late:
class TwoSecondDelayWatermark extends BoundedOutOfOrdernessTimestampExtractor[Measurement](Time.seconds(2)) {
override def extractTimestamp(element: Measurement): Long = element.time
}And then the Flink program is something like the following:
object Flink {
def main(args: Array[String]) {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "flink_consumer")
env
.addSource(new FlinkKafkaConsumer09[Measurement]("pollution", new MeasurementSchema(), properties))
.assignTimestampsAndWatermarks(new TwoSecondDelayWatermark())
.timeWindowAll(Time.seconds(10))
.apply(
(0L, 0.0, 0), // (Window End Time, To Store Mean, Count)
(acc: (Long, Double, Int), m: Measurement) => { (0L, acc._2 + m.pollution, acc._3 + 1) },
( window: TimeWindow,
counts: Iterable[(Long, Double, Int)],
out: Collector[(Long, Double, Int)] ) =>
{
val count = counts.iterator.next()
out.collect((window.getEnd, count._2/count._3, count._3))
}
)
.filter(_._2 > 75.0)
.print() // Replace with call to custom sink to raise alert for pollution level
env.execute()
}
}Note that the code to calculate the mean is a bit more verbose than Spark. Just as Flink is advancing its Table API and SQL, Spark has caught onto Flink’s advances and now enables processing based on event time in its new Structured Streaming API.
Wrapping up
If your use case demands you know the answer as things are happening then streaming could be a great fit regardless of how ‘Big’ your data is. Kafka, Spark and Flink are all great tools to achieve this. The full example code can be found on GitHub.

