StreamSets Data Collector (SDC) is an open source tool for stream-based extracting, transforming and loading large quantities of data. It provides an easy to use UI on top of the underlying processing power of YARN and Spark Streaming with a large number of installable integrations with source and destination systems.
We found the process of setting up an SDC system with an HDFS output somewhat fiddly, so here we provide a push button solution for spinning up this example system, based on the Docker containers provided by StreamSets and Hadoop.
You can find the Git repository for this example here. Read on for the details of how we created this system!
Installing StreamSets
We wanted a lightweight, easily reproducible install that we can hand over to others, and Docker containers provide a great solution for this. StreamSets provide a Docker container for Data Collector, obtainable from Dockerhub. Installing and starting it is a one line command.
docker run -p 18630:18630 -d streamsets/datacollector
Note that you need a Linux machine to run Docker. We used an Ubuntu 16.04 VM, the creation of which we automated using Vagrant.
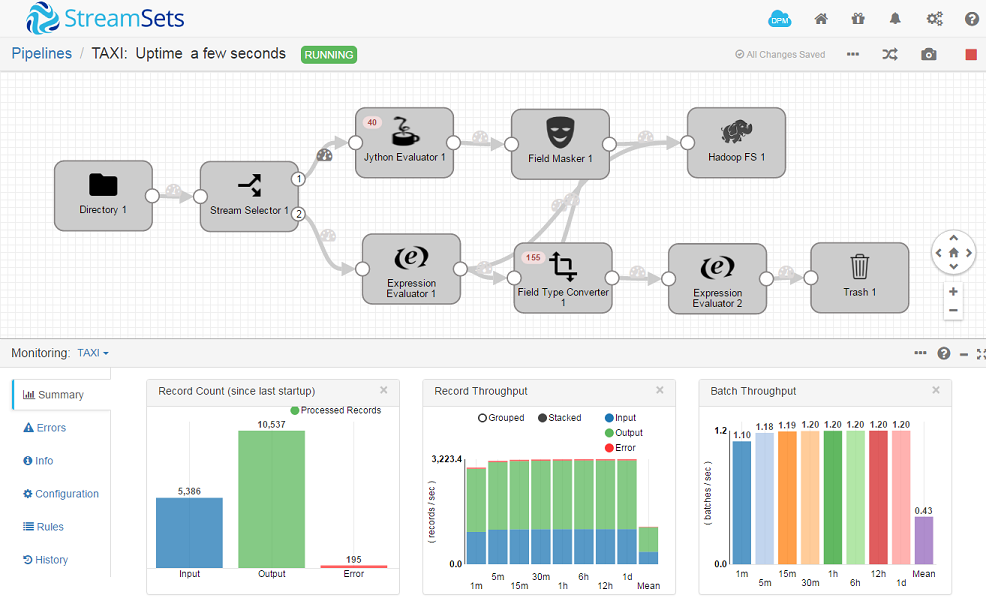
We wanted a non-trivial demo, so we wanted to integrate StreamSets with a 3rd party output. To set up the pipeline, we followed the StreamSets taxi tutorial. We chose to store the output from our pipeline in the Hadoop Distributed File System (HDFS), which could be convenient for later processing. To use this output, we needed to install a Hadoop library.
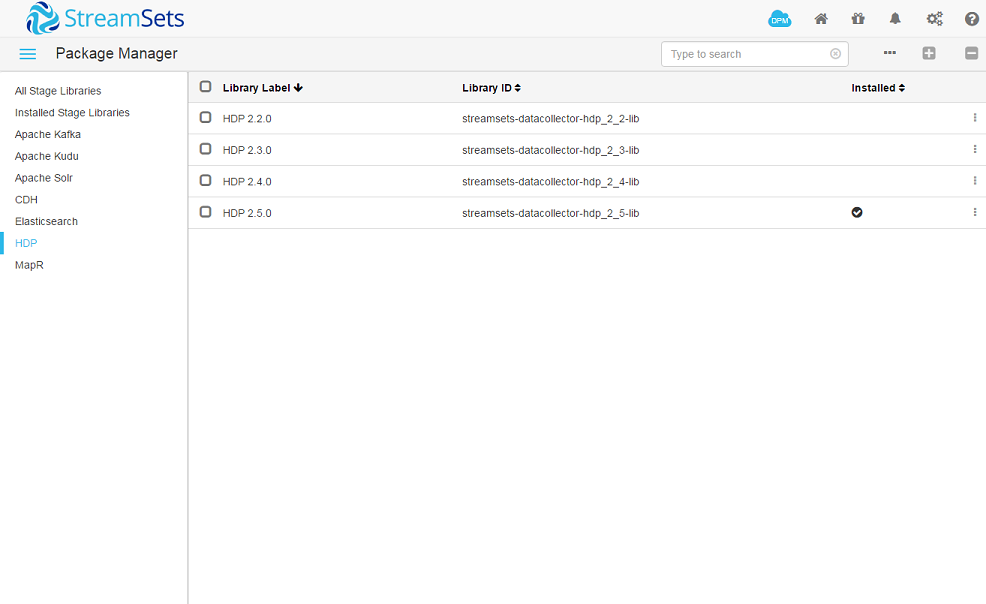
The supported procedure for installing packages into the Docker container is a little fiddly. Essentially we needed to attach a volume so that the installed packages are retained through container restarts. The installation can then be done either from the GUI or from the command line.
docker run --rm -v sdc-stagelibs:/opt/streamsets-datacollector-2.3.0.0/streamsets-libs streamsets/datacollector:2.3.0.0 stagelibs -install=streamsets-datacollector-hdp_2_5-lib
docker run -v sdc-stagelibs:/opt/streamsets-datacollector-2.3.0.0/streamsets-libs -p 18630:18630 -d streamsets/datacollector:2.3.0.0
We’re leaving behind our one line command that we started with. Thankfully, Docker containers are simple to extend.
FROM streamsets/datacollector:2.3.0.0
# Build time argument to install packages
ARG PACKAGES_TO_INSTALL=streamsets-datacollector-hdp_2_5-lib
# Install the packages
RUN if [[ ! -z $PACKAGES_TO_INSTALL ]]; then $SDC_DIST/bin/streamsets stagelibs -install=$PACKAGES_TO_INSTALL ; fi
Once this container is built, we’re back to our one line command.
Installing Hadoop
We’ve got StreamSets set up, now we need a Hadoop instance for the HDFS output. Once again, Docker comes to our rescue.
docker run -it sequenceiq/hadoop-docker:2.7.1 /etc/bootstrap.sh -bash
We needed to create an HDFS user for StreamSets (we don’t really want it writing as root). Once again, we extended the Docker container.
FROM sequenceiq/hadoop-docker:2.7.1
# User to create
ENV USER sdc
ENV USERGROUP hadoopusers
# Create the user
RUN groupadd -f $USERGROUP
RUN useradd -g hadoopusers sdc
RUN mkdir -p /tmp/hadoop-sdc
RUN chown $USER:$USERGROUP /tmp/hadoop-sdc
RUN chmod 777 /tmp/hadoop-sdc
# Create the HDFS user dir
RUN service sshd start && $HADOOP_PREFIX/etc/hadoop/hadoop-env.sh && $HADOOP_PREFIX/sbin/start-dfs.sh && $HADOOP_PREFIX/bin/hdfs dfsadmin -safemode wait && $HADOOP_PREFIX/bin/hdfs dfs -mkdir -p /user/$USER && $HADOOP_PREFIX/bin/hdfs dfs -chown -R $USER:$USERGROUP /user/$USER
Bringing it all together
We have our custom containers for StreamSets and Hadoop. The final thing we need is a push button process for spinning them up together, whilst telling the StreamSets container how to contact the Hadoop container. Docker Compose is a great solution for this. We can define everything about our containers - the links between them, the ports they expose - in one YAML file.
version: '3.0'
services:
hdfs:
image: dketley/sdc-hdfs
hostname: hdfs
container_name: hdfs
ports:
- 50070:50070
- 50075:50075
sdc:
# Uncomment these lines if you need to build the docker image locally
# build:
# context: docker/streamsets
# args:
# - PACKAGES_TO_INSTALL=streamsets-datacollector-hdp_2_5-lib,streamsets-datacollector-jython_2_7-lib
image: dketley/sdc # Comment this out if you need to build the docker image locally
hostname: sdc
container_name: sdc
links:
- hdfs
ports:
- 18630:18630
# Start DNS server so that HDFS download links work on the Linux host
dns:
image: mgood/resolvable
hostname: dns
container_name: dns
volumes:
- /var/run/docker.sock:/tmp/docker.sock
- /etc/resolv.conf:/tmp/resolv.conf
We’ve added in a DNS container so that download links from the HDFS GUI work.
And we have a one line command to spin all this up.
docker-compose up -d
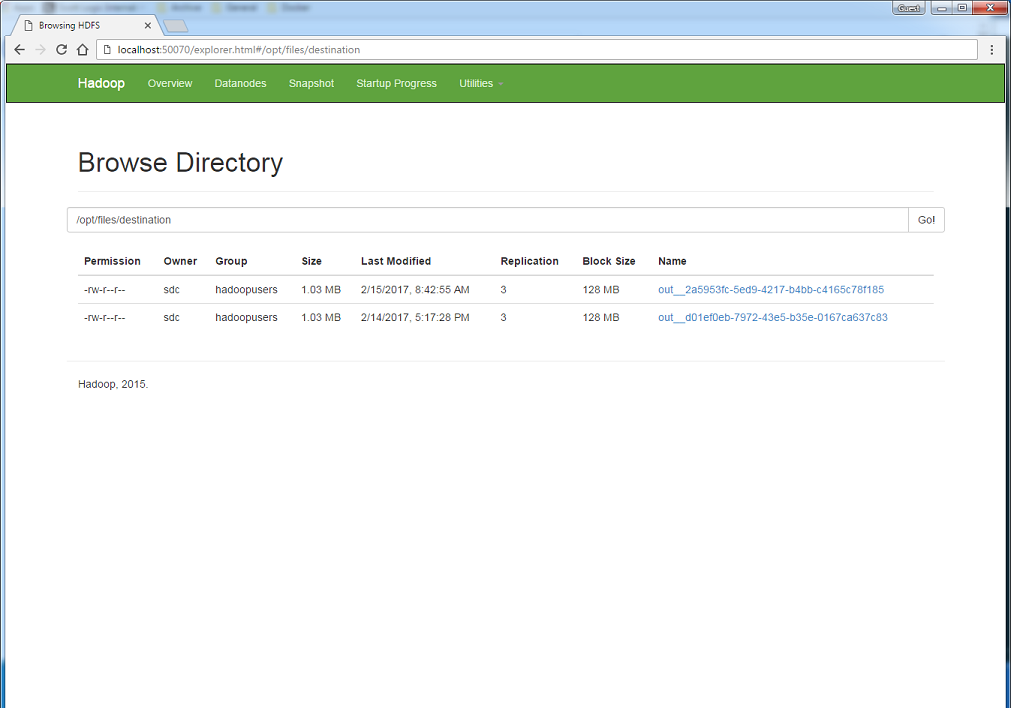
StreamSets can now store files in HDFS using the hdfs link.
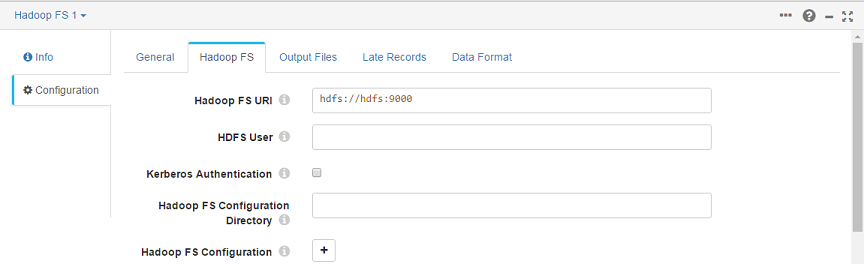
The output files of our pipeline can be downloaded from HDFS.