
After a few weeks of HTML5 and Java training, the Newcastle summer graduates were given the task of creating a stock portfolio watchlist application that allowed the user to track the prices of various stocks. There were several requirements for this app, including a responsive design that suited anything from desktop PCs to mobile devices, being able to display visual information about stocks in multiple reorderable lists, and the ability to save these watchlists within a user account.
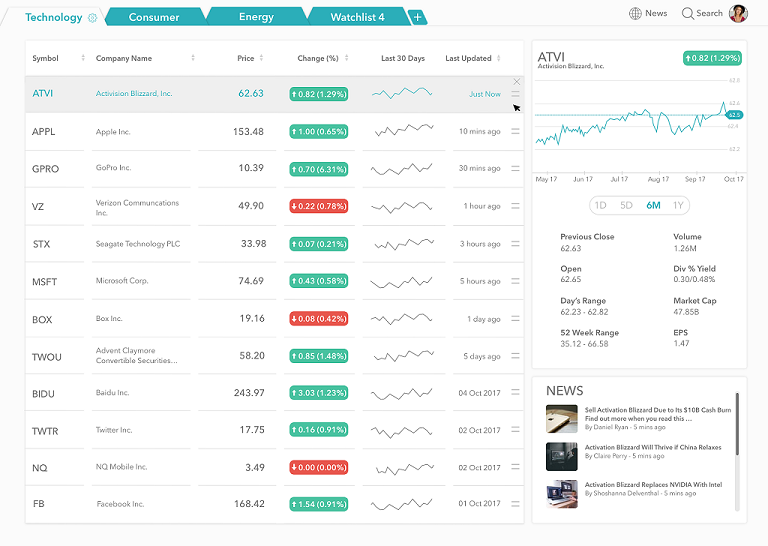
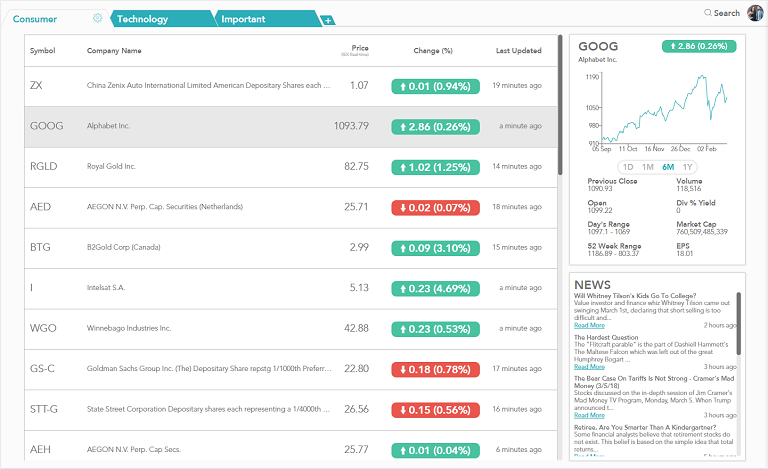
Below is the final UX design we received, displaying various important features: multiple watchlists, relevant news articles, the percentage change of each stock and the chart showing the price over time.
Project Structure
We used an Agile development approach, following Scrum and splitting the time spent on the project into small one-week sprints. We divided the functionality of the application into smaller tasks, each with a rough estimate of the time and effort it would take to complete. We assigned a certain number of these tasks to the current sprint depending on their estimate and how many we believed we could feasibly get done in the time-frame. We met every morning in daily stand-ups, discussing what we did the day before, our plan for the day ahead, and if there were any blockers preventing our progress.
Weekly demonstrations were scheduled with our product owners, where we presented new features and received regular feedback about our current work and the direction or area that was preferable to focus on next. Following this we would have a team retrospective to discuss how we found the previous sprint and what we thought went well or not, before estimating the next set of tasks for the week coming.
Research
The first task was to research around the project. We investigated various key features, including financial APIs for the stock information, data persistence and continuous integration. We also looked into different libraries and frameworks for authentication, testing and websockets. This was an important starting point as it encouraged us to think more about the work we were planning, letting the team read around the various topics before jumping straight into the development.
Continuous integration is the practice of regularly committing code then automatically building and testing it. If the code passes the tests, it is then merged into the rest of the codebase. We used a combination of CircleCI and Docker to immediately deploy our master branch to Heroku on every merge, meaning we could quickly have our most up-to-date version of the app displayed and useable.
For the source of the stock information we chose IEX, an exchange based in New York that contained a variety of useful features we could make use of. IEX offered a very comprehensive API that enabled us to get all the details we needed about specific stocks, including information such as the Market Cap, Volume and Range. The exchange provided this information in real-time, which meant we would be up-to-date with the correct prices and percentage changes as expected in a financial application. Additionally, IEX provided all this for free, which we found to be something of a rarity during our research.
Choice of Technology
React/Redux Front-end
We utilised a React/Redux front-end. The app was to be made up of reusable components, such as the rows in the tables, and these needed to be updated frequently and independently. React was perfect for this as it updates a virtual DOM first, compares this to a snapshot taken before the update, and then only updates the corresponding elements in the real DOM that actually changed. This prevents the entire DOM updating whenever a single price changed, for example. When it was possible to have hundreds of stocks in a single watchlist all updating in real-time, only changing the elements that actually updated was very important.
Redux was chosen for its ability to control the state of the application. Redux handles when the application can be updated, storing the entire state within a single tree. This state is only changeable through pure functions called reducers, which take the previous state and an action and return the new state. Multiple reducers were used for each aspect of the state we wanted to control, such as the watchlists or whether the search-bar was open. It became very straightforward to handle the constant flow of price updates, stocks being reordered and switching between watchlists.
React Libraries
We utilised various React libraries during the project, to avoid getting sidetracked by tricky tasks that had already been solved. For instance, the application needed a search function to allow users to find stocks to add to their watchlist. As there were thousands of stocks, a less specific search term would result in a large number of results being displayed, which could negatively impact performance. React Virtualized solved this issue by only rendering visible items in the DOM, meaning we could return thousands of search results without performance issues.
For the drag and drop functionality of the watchlists we used React Sortable, a very simple solution to a complex problem. This allowed us to include drag handles on mobile, as well as a slight delay on larger screen sizes to differentiate between dragging and clicking. There were a few challenging styling issues on dragged stocks, but they were eventually resolved.
The login and authentication was handled by Auth0. Relatively easy and very popular, Auth0 enables users to log in using various social media accounts. For Stock Watcher we utilised Facebook, Google and Twitter. It meant that authenticating users became extremely simple, especially as we were able to use a pre-existing modal.
Java Back-end
Our Java back-end was built around the Spring framework. This allowed for a quick set-up with minimal configuration. We primarily used Spring for dependency injection, with annotations instead of the old XML file injections. Spring helped us to create a simple REST API and using the CrudRepository interface we were able to reduce boilerplate code. We were also able to protect against SQL Injection by making use of Hibernate.
The back-end would receive information about subscribed stocks from IEX, and then send these to the front-end. We chose not to use websockets with IEX as the API was limited to Node.js servers, and that was incompatible with our Java back-end. We could have handled the websockets in our front-end, but there was a constraint in our brief regarding being able to swap out the data source without having to adjust the front-end accordingly. To get around this, we had the server periodically request new prices and then cache this information. We could then provide the last available details about a stock when the market was closed without having to make a request.
To avoid exceeding any API limits on the number of requests in a certain time, we batched the requests for the stocks currently in use so they only counted as one, so we still received up-to-date information for each stock. These new prices were then broadcast via websockets to the client, to ensure that the client saw regularly updated prices for the stocks in their watchlists.
We stored information about users, their watchlists and the stocks inside them in a PostgreSQL database, chosen primarily as it was free to host on Heroku. As a result we were able to store user data, such as the number of watchlists and their names and the positions of the stocks inside, and provide this to users on login or when they refreshed.
Testing
We used Jest for our front-end, creating unit tests for each component, reducer and selector. For our back-end we used JUnit to run both our unit and integration tests. All of these tests ran during every push on CircleCI, this meant that even if we forgot to run the tests locally we would soon be very aware if they failed and so we were quickly able to adjust and fix the code.
We utilised Selenium and Webdriver JS with Jest to handle our end-to-end tests. These checked the main functionality of the application, running through various features such as the drag and drop, login and searching. Primarily used as regression tests, we ran these regularly and were quickly alerted to any modified code breaking the functionality of the app.
Retrospective
For most of the team this was our first experience of working with Scrum. We found the sprints to be extremely productive, keeping our focus on a small number of features that gradually expanded over the duration of the project. We rarely found our attention shifting to issues out of scope, which helped keep us on track and stick to deadlines.
Originally we started as a 5 person team; however, due to new projects starting in the business this eventually shrunk to only 2 people. While this caused a few issues early on, including an initial lack of expertise in certain areas we had not personally had experience with, we coped well with the change. In fact, it resulted in extra scrutiny being applied during code reviews to avoid any issues. This in turn improved the level of code that was produced and overall quality of the project.
If you compare the finished application with the final designs, it’s quite apparent how successful the translation of UX to final product was. Some changes were made based on feasibility or usability, but overall the work remains fairly true to the initial spec.
Despite the clear benefits that continuous integration offered, we encountered several issues with CircleCI over the course of the project. To persist data, we essentially required 3 databases: a local version, a version using a Docker image for CI and one for Heroku. However, when attempting to set up the database for CircleCI, we had difficulty getting it to work inside the VM. It was a real hassle to try and configure the correct environment variables in the correct form and it took some trial and error before we finally got it up and running. Originally we had the end-to-end tests running on CircleCI on every push, but for some reason these weren’t passing consistently. We eventually discovered that the tests themselves were running faster than the VM could manage, resulting in search terms not returning in time or other steps being skipped. To resolve this, we had to trust ourselves to regularly run the E2E tests locally to ensure our changes never broke the application.
As the project only lasted a few months, there were a few issues we would have liked to fix if given more time - most notably a lack of security. For example, to get the stocks in a specific watchlist, you only need the watchlist ID. In truth, we should also have some form of user verification to make sure that only the user can get their own watchlists. In addition, due to the shifting focus of the team as members left, there was a lack of any true exploratory or performance testing, meaning there may still be some unknown bugs in the system. While the unit and E2E tests had fairly good coverage of the code and functionality, it would’ve been good to devote some time exploring the application and getting to know its real limits and capabilities.
Overall the project was extremely enjoyable: it gave us a good insight into how we would be working in the future. Having never really had the chance to use services like Github and Jira, we found the experience vital. It allowed us to really improve our skills with JavaScript and Java and taught us about the importance of code reviews and general collaboration within the team. It left every member of the team hungry for more, and looking forward to the opportunities ahead.

