
When WebAssembly was released a couple of years ago it was an MVP (Minimal Viable Product), having a small feature-set deemed just enough to make it useable and useful. One significant feature that was missing from the MVP was threads. The WebAssembly threads proposal is now quite mature and available in both the tooling and Chrome. This blog post explores the internals of this feature, the new instruction set, and how it supports multi-threaded applications.

Multi-threading and concurrency
Before delving into the details of the WebAssembly threads specification, I’m briefly going to talk about concurrency and threads, what they are, why we use them, and the challenges they present. If you’re old and wise, feel free to skip this section!
Modern computers have multiple CPUs (which themselves have multiple cores - but for simplicity I’ll refer to them simply as CPUs), each of which is able to execute programs independently. We can take advantage of this in various ways. For example, if you have a computationally intensive task such as image processing, you can split the work across multiple CPUs to get it done more quickly. Or, if you have a task that takes a modest amount of time (a second or two), you might want to handle this on a different CPU to the one that is updating your application UI, in order to preserve 60fps frame rate.
Threads are the underlying programming construct that allow you to divide work between these CPUs. There isn’t a direct mapping between threads and CPU, but in practice, in order to achieve concurrency you need to create multiple threads.
Creating applications that make good use of concurrency is a challenging problem, where you have to reason about each ‘thead’ of execution, each with a combination of local and shared state. You need additional tools, such as ‘locks’, which are used to prevent more than one thread executing a section of code. However, these present further challenges, which excessive locking limiting concurrency, or deadlocks.
A programmer had a problem. He thought to himself, "I know, I'll solve it with threads!". has Now problems. two he
— Davidlohr Bueso (@davidlohr) January 8, 2013
It’s no surprise that modern tools, frameworks and architecture approaches typically hide concurrency; NodeJS, Lambda functions, browsers all appear as single-threaded environments. On a personal level, I must admit it’s years since I last created a thread pool!
While it is less common these days, there are still times when you’ll want to make explicit use of threads.
Web Workers and concurrency in the browser
There are a number of APIs available within the browser, allowing JavaScript developers to make use of concurrency. We’ll take a quick look at theses, and their current status.
Web browser are essentially single threaded (from a developer perspective), your application logic shares the same thread as the UI rendering engine. As a result, a long running computation will result in the UI locking or hanging. The limitations of this approach are far outweighed by its simplicity, which is why it is a common approach across many other UI frameworks (e.g. WPF, WinForms, Cocoa / iOS).
The Web Worker API, which allows you to spawn ‘worker’ threads has been widely supported for a number of years. This API allows you to create a worker that executes the JavaScript within a given file. Workers do not have DOM access, although they can make XHR request, and use WebSockets. Workers cannot share mutable data with the main (UI) thread, instead the rely on asynchronous message passing:
// ## main.js
const worker = new Worker("worker.js");
// pass a message to the worker
worker.postMessage("Hello World!");
// ## worker.js
// The onmessage property uses an event handler to retrieve information sent to a worker.
onmessage = event => {
console.log("Received message " + event.data);
};
Web Workers provide a really simple API that avoids many of the thorny issues associated with concurrency. However, this simplicity only really lends itself to a coarse-grained approach to concurrency where relatively large tasks are handed off to workers.
More recently the introduction of SharedArrayBuffer and Atomic operations have given developers the opportunity to make use of shared memory across multiple threads. This allows for the implementation of much more fine-grained concurrent algorithms. For a fantastic overview of the importance of atomic operations, see Lin Clark’s excellent cartoon guide.
Unfortunately, while shared array buffers were widely supported, the threat presented by Spectre and Meltdown (timing attacks that allow data to leak between processes) resulted in all the browser vendors immediately removing support in order to mitigate the risks due to these vulnerabilities. Currently Chrome is the only browser to have re-enabled these features (in late 2018) due to mitigations via site isolation and cross-origin read blocking. However, I’m confident that it will return in the other browsers once suitable mitigations are identified.
WebAssembly Threads Proposal
So where do threads fit in with WebAssembly? The initial MVP release didn’t include any threading-related constructs, simply because it was not viewed as necessary for the MVP - which was clearly the right choice as people have been able to achieve all sorts of interesting and useful things with the current feature-set.
I personally think WebAssembly threading support is important for a couple of reasons; firstly, WebAssembly is an ideal technology for computationally intensive tasks, where the ability to split these tasks across multiple CPUs is a significant benefit; secondly, most of the languages that have WebAssembly as a compilation target have their own threading constructs, so need this feature in order to realise their full potential.
WebAssembly has a similar proposals / specification process to JavaScript (via TC39). Threads is currently a stage 2 proposal which means that the specification draft is complete and implementations are available. The current specification draft is available via GitHub. This basically means it is ready for us to play with!
The WebAssembly thread specification is comprised of the following:
- Shared linear memory
- Atomic operations
- Wait / notify operators
The first element, shared linear memory, is very similar to the JavaScript’s SharedArrayBuffer in that it allows multiple WebAssembly modules (and the JavaScript host) to directly access the same ‘chunk’ of memory.
Concurrent memory access can result in corruption, where one thread reads a value part way through a write of the same value from another thread. This is where Atomic operations come in, they are a simple set of instructions (read, write, increment, …) that are guaranteed to be atomic, that is, other threads are only able to see their result on completion. This is a basic, but vital, building block that paves the way for creating higher-level concurrency concepts such as locks and barriers.
Finally, the wait / notify operators provide a mechanism for suspending a thread (without busy waiting), and re-awakening it from another thread.
One thing you might have noticed is that the threads specification doesn’t provide a mechanism for spawning new threads. This is a surprising and deliberate omission! It is instead the responsibility of the host (i.e. the environment which the WebAssembly module executes within), to create the threads themselves. This specification provides the tools required to allow WebAssembly to be used safely and effectively within a multi-threaded environment.
Diving in …
Right, enough theory, time to get stuck in!
In order to try out the WebAssembly thread features, I needed a task that was suited to concurrency. I opted for the classic problem of rendering a Mandelbrot fractal, this is a very simple, yet computationally intensive task that is easy to split up into little independent pieces that can be tackled in parallel.
The conventional approach to rendering the Mandelbrot set is to iterate over each pixel of the image, compute the value for that pixel (which is based on the number of iterations of the underlying equation that defines the set) and colour is accordingly. Quite simple:
for (let y = 0; y < 1200; y++) {
for (let x = 0; x < 800; x++) {
const value = mandelbrot(x, y);
setpixel(x, y, value);
}
}
The value for each pixel is quite independent from all the others, which means the above can be accelerated by sharing the load across multiple thread with relative ease. One potential approach is to have each thread compute a subset of the pixel values, then return these to the main thread for assembly into the final image. This wouldn’t require any shared state, and hence could be achieved with Web Workers without the need for a SharedArrayBuffer. However, this isn’t a great example for showcasing WebAssembly threading features.
An alternative approach is to have a single index that represents the location of the next pixel that needs computing, and a while loop that continually picks up this value, computes and sets the pixel, then increments - as follows:
let index = 0;
while (index < 1200 * 800) {
index++;
const value = mandelbrot(x, y);
setpixel(index % 1200, Math.floor(index / 1200), value);
}
Multiple threads could be set to work executing the above while loop in order to achieve the overall task in less time. However, in this case the state of the index value is shared across multiple threads, causing issues which we’ll tackle shortly. But first, we’ll take this overall approach and turn it into a WebAssembly implementation.
Hand-crafted concurrency
I do enjoy hand-coding WebAssembly (i.e. writing it directly in WebAssembly Text Format in the native instruction set, as opposed to compiling from a higher-level language), and in this case, it is most appropriate because I wanted to look at exactly what threading features the runtime has to offer.
Rather than hand-code the whole application, I did take a few short-cuts, using WebAssembly Studio to compile the basic algorithms from AssemblyScript into wasm.
Here’s the mandelbrot equation written in AssemblyScript:
function iterateEquation(x0: f64, y0: f64, maxiterations: u32): u32 {
let a = 0.0,
b = 0.0,
rx = 0.0,
ry = 0.0,
ab: f64;
let iterations: u32 = 0;
while (iterations < maxiterations && rx * rx + ry * ry <= 4) {
rx = a * a - b * b + x0;
ab = a * b;
ry = ab + ab + y0;
a = rx;
b = ry;
iterations++;
}
return iterations;
}
And here is the resultant WebAssembly:
(func $iterateEquation (param $p0 f64) (param $p1 f64) (param $p2 i32) (result i32)
(local $l0 i32)
(local $l1 f64)
(local $l2 f64)
(local $l3 f64)
(local $l4 f64)
loop $L0
get_local $l4
get_local $l4
f64.mul
get_local $l1
get_local $l1
f64.mul
f64.add
f64.const 0x1p+2 (;=4;)
f64.le
i32.const 0
get_local $l0
get_local $p2
i32.lt_u
select
if $I1
get_local $l2
get_local $l3
f64.mul
set_local $l1
get_local $l2
get_local $l2
f64.mul
get_local $l3
get_local $l3
f64.mul
f64.sub
get_local $p0
f64.add
tee_local $l4
set_local $l2
get_local $l1
get_local $l1
f64.add
get_local $p1
f64.add
tee_local $l1
set_local $l3
get_local $l0
i32.const 1
i32.add
set_local $l0
br $L0
end
end
get_local $l0
)
With the function above, and a few other similar utilities (e.g. colour scale, coordinate transforms), I was able to construct a simple loop that renders the Mandelbrot using the strategy described above, i.e. a loop that takes the next index, increments, computes and sets the pixel value.
Here is that function, which takes three parameters, $cx, $cy and $diameter, which simply indicate the location within the mandelbrot set:
(func $run (param $cx f64) (param $cy f64) (param $diameter f64)
(local $x i32)
(local $y i32)
(local $loc i32)
(block $myblock
(loop
;; load the next location that is being computed
(set_local $loc
(i32.load
(i32.const 0)
)
)
;; store the incremented version
(i32.store
(i32.const 0)
(i32.add
(get_local $loc)
(i32.const 1)
)
)
;; loop for 1200 * 800
(br_if $myblock
(i32.ge_u
(get_local $loc)
(i32.const 960000)
)
)
;; convert to coordinates
(set_local $y
(i32.div_u
(get_local $loc)
(i32.const 1200)
)
)
(set_local $x
(i32.rem_u
(get_local $loc)
(i32.const 1200)
)
)
;; compute the next mandelbrot step and store
(i32.store
(call $offsetFromCoordinate
(get_local $x)
(get_local $y)
)
(call $colour
(call $mandelbrot
(get_local $cx)
(get_local $cy)
(get_local $diameter)
(get_local $x)
(get_local $y)
)
)
)
;; repeat the current loop
(br 0)
)
)
)
I’m not going to delve into the details of the various instructions in the above code sample, hopefully they are relatively self-explanatory. The one thing that is worth mentioning is where some of the application state is stored.
The index, which indicates the next pixel to compute, is stored in linear memory at location 0, as can be seen from the code that loads it and sets the locals $loc variables. The Mandelbrot itself is also written to linear memory, with the $offsetFromCoordinate providing the required offset (starting at location 4 in order to avoid overwriting the aforementioned index!).
So how can the above code be updated to permit concurrent execution?
The functions that compute the mandelbrot result, and other utilities aren’t an issue - they are stateless, which makes them immediately thread-safe. Also, the write operations that store the result for each pixel are not an issue, as these writes never coincide on the same location. In fact, the only issue is the part that reads, increments, and writes the current index, which uses memory address 0. This would be subject to concurrent reads / writes, and in order to avoid corruption need to be made atomic.
The threads specification provides atomic load, store, read-modify-write and compare-exchange operations. In this case the whole process of loading, incrementing and writing the index needs to be performed atomically, which is an ideal candidate for an atomic read-modify-write.
The current (non thread-safe) code that performs this step is as follows:
;; load the next location that is being computed
(set_local $loc
(i32.load
(i32.const 0)
)
)
;; store the incremented version
(i32.store
(i32.const 0)
(i32.add
(get_local $loc)
(i32.const 1)
)
)
It can be replaced with the atomic equivalent:
(set_local $loc
(i32.atomic.rmw.add
(i32.const 0)
(i32.const 1)
)
)
The i32.atomic.rmw.add is a read-modify-write that performs an atomic addition, the two arguments in the above example 0 and 1 basically result in the value located at the zeroth memory address being incremented by one.
That was easy! So how do we compile and run this code?
The WebAssembly Binary Toolkit contains a number of relatively low-level tools for working with wasm modules, including wat2wasm, which is a tool that translates WebAssembly Text Format to the binary module format that is shipped to the browser. This tool has feature-flags that allow it to translate modules that use post-MVP features, as follows:
wat2wasm --enable-threads mandelbrot.wat -o mandelbrot.wasm
Wasm linear memory can either be created by the module itself, or imported when the module is created. In this case we need to mark the memory as ‘shared’ and supply it to multiple modules (each in a different web worker). Under the hood, linear memory uses a SharedArrayBuffer, which is one of the reasons why this code will currently only work in Chrome.
The following code creates a shared memory instance, spawns a number of web workers, waits for them all to signal completion, then renders the contents of the memory to a canvas:
const memory = new WebAssembly.Memory({
initial: 80,
maximum: 80,
shared: true
});
// https://commons.wikimedia.org/wiki/File:Mandel_zoom_04_seehorse_tail.jpg
const config = {
x: -0.743644786,
y: 0.1318252536,
d: 0.00029336
};
const workerCount = 4;
let doneCount = 0;
// spawn the required number of workers
for (let i = 0; i < workerCount; i++) {
const worker = new Worker("worker.js");
worker.onmessage = e => {
doneCount++;
// have they all finished?
if (doneCount === workerCount) {
// copy the contents of wasm linear memory to a canvas element
const canvasData = new Uint8Array(memory.buffer, 4, 1200 * 800 * 4);
const context = document.querySelector("canvas").getContext("2d");
const imageData = context.createImageData(1200, 800);
imageData.data.set(canvasData);
context.putImageData(imageData, 0, 0);
}
};
worker.postMessage({ memory, config });
}
The above code uses postMessage to send this shared memory, and the config object which describes the location to render to each worker.
Here is the worker.js script:
onmessage = ({ data }) => {
const {
memory,
config: { x, y, d }
} = data;
fetch("mandlbrot.wasm")
.then(response => response.arrayBuffer())
.then(bytes =>
WebAssembly.instantiate(bytes, {
env: {
memory
}
})
)
.then(({ instance }) => {
instance.exports.run(x, y, d, id);
postMessage("done");
});
};
It does little more than instantiate the WebAssembly module, supplying the shared memory, letting it run, then posting a message back to the main thread. It is pleasantly surprising how little code you need to write in order to share this task across multiple threads.
To recap, each thread repeatedly acquires the next pixel location to compute from shared memory, writing the result to the same shared memory. Each thread terminates when there are no more pixels to compute, resulting in a classic mandelbrot:

So, just how fast is this approach?
On my machine, which has 4 cores, I observed the following:
- 1 thread - 11 secs
- 2 threads - 5.7 secs
- 4 threads - 4.2 secs
A significant speed increase!
Finally, I thought it would be fun to re-render the mandelbrot set, with each pixel coloured based on the thread which computed it.
Here’s the full mandelbrot set:
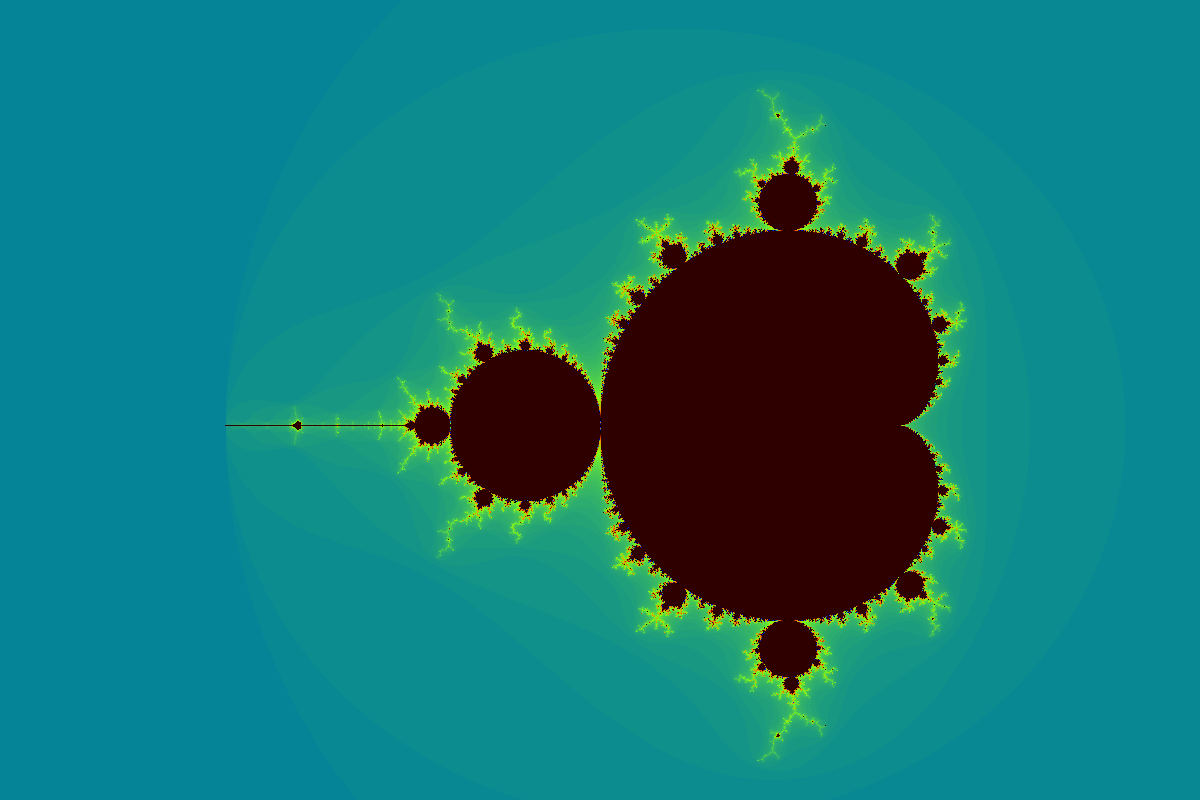
Note, if you’re not familiar with the way the Mandelbrot set works, the colour for each pixel is determined by how many iterations it takes for the underlying equation to ‘escape’. The dark region is where the equation never escapes and iterates infinitely (until an upper bound is reached). For that reason, the dark region takes much more time to compute.
And here it is coloured by thread:

I find this a fascinating picture!
At the top, you can see that the first thread made some significant progress, on some of the simpler parts of the fractal, before the others started working. Following that, you can see regions where threads take it in turns, on a pixel-by-pixel basis. When the rendering reaches the dark region, where the equation iterates infinitely, all four threads take it in turns, until the first one to reach the end, which then races ahead to complete that line - hence the streaked pattern to the right.
Conclusions
WebAssembly threads is a really interesting new feature that brings shared memory, atomic operations, and wait / notify to the language. Unfortunately this feature is somewhat coupled to SharedArrayBuffer, so until the vulnerabilities associated with this feature are resolves (in browsers other than Chrome), it could be a while before we see more widespread use. But when we do, I’m sure we’ll see some quite powerful applications being built in the browser!
If you want to dig into the code (not that there’s much of it), it’s all on GitHub. You can also run the code in your (Chrome) browser.