
Overview
In this blog we will be exploring a couple of ways to create, manage, and send email digests to users via serverless architecture, using a Twitter like social media mockup as our example platform. For this example we are assuming an Elasticsearch datastore is being used to store our mock posts.
Digests are a common use case in order to provide users with daily and real-time data, for example a summary of daily news reports, or a news feed on a social media platform. To provide this functionality we will be using AWS Lambdas, Step Functions, and Elasticsearch Service, as well as using the Serverless Framework for deployment.
The goal is to allow a user to subscribe to a digest for a search they have performed, receiving updates with new posts either daily or in near real-time (chosen by the user) via email. At the core of this process is the Elasticsearch cluster that is used for storing the documents (posts) that are contained within the system. In particular we are looking at the management and monitoring of incoming posts so that we can inform users of posts that are relevant to their digest subscriptions.
Technology Choice
Due to its efficiency and scalability we will try to push as much of the data processing workload onto the Elasticsearch cluster as possible. For our example we are using AWS serverless architecture, so we will make use of Lambdas and Step Functions in order to provide our digest functionality, and to interact with our Elasticsearch cluster.
For real-time digests we make use of an index (an index is like a database, storing documents with particular fields) that will use the Elasticsearch percolator type, this allows us to store Elasticsearch queries within the index.
Normally our Elasticsearch documents will be a representation of some data, for example we could store names using the fields firstName and lastName with appropriate field types such as keyword or text. We can then create a search, for example where firstName = John, to get all the documents where this condition is true. By using a percolator field type we can “reverse” this process by storing a search instead, for example we can store our search for firstName = John using the percolator field type. Now when we have new data we can check it against our stored searches and see which ones would match, for example if we add the data firstName = John, lastName = Smith we would get a match for our search.
Daily digests require a different approach in order to be effective, the solution we decided on was to use a cost efficient, non-relational database to store mappings of user ID’s to daily digest searches. We can then schedule a Lambda to run each day that will perform the searches that a user is subscribed to.
Real-time Alerts
Setup
To provide alerts in real-time we are going to use a percolator field type so that when we have new data we can check it against any searches we have stored. To do this we will create an index within our Elasticsearch cluster where we will store all of our searches. Creating an index requires a request to our elasticsearch cluster, the full details of the request can be found in the createIndex file, however the part we are interested in looks like this:
properties: {
search: {
properties: {
query: { type: 'percolator' },
userID: { type: 'keyword' },
searchTerm: {
type: 'text',
fields: {
keyword: {
type: 'keyword'
}
}
}
}
},
Content: { type: 'text' },
Tags: { type: 'text' }
}
We store our search under the query field using the percolator type, however we also store the fields userID and searchTerm. We need userID so that we can link each search to the correct user, this will allow us to email the correct person when we get a match. The searchTerm field is not needed for sending an alert to a user, however it allows us to provide some additional functionality where we need to be able to uniquely identify a subscription. For example we can allow functionality for deleting a subscription, and checking if a subscription already exists. Ideally we would use the query field instead of storing the search terms directly, however Elasticsearch stores data in percolator types as Elasticsearch queries meaning the data is obfuscated and we cannot search for the search terms within the query field directly.
Managing real-time digests
In order to create a digest for a user we simply need a request containing the users’ ID (we get this from our Cognito authorisation) and the search they want to subscribe to. Using the ID and the search terms we can check if the user is already subscribed to the digest and then create the subscription if they are not.
Creating a real-time digest:
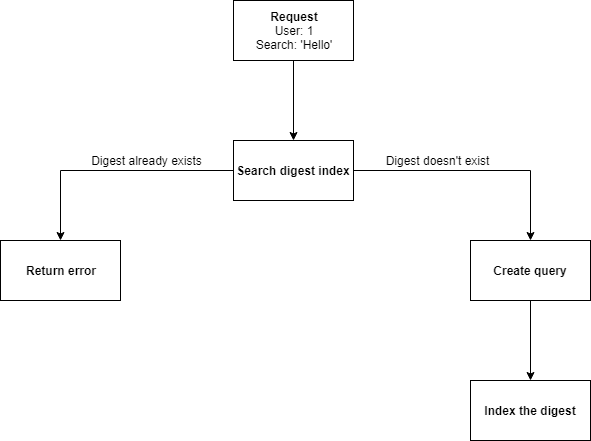
To delete a digest a request is made containing a users’ ID and the search that they want to remove. As the ID and the search terms can identify a unique entry we can look this up and remove the relevant digest from the index. We can also get all the digests for a particular user simply by searching for anything that matches their ID.
Delivering real-time digests
Delivering real-time digests is a workflow that is hooked into the process of creating a new post for the system. The following diagram shows the create-post-request-step-function that is executed in order to manage this process:
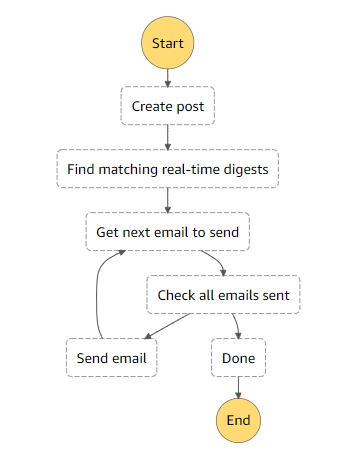
The first step is to create and store the new post in the system so that it is visible to all users, then the process for managing the digests begins. This happens in the matchRealTimeDigests Lambda where we use our percolator type field to get all the searches that would match the post. On its own however this search is not the most useful as it can return multiple entries for the same user, for example a response could look like this:
// Digests matching post 'Hello World'
[
{
...,
"_source": {
"search": {
"userID": 0,
"searchTerm": "hello",
"query": ...
}
}
},
{
...,
"_source": {
"search": {
"userID": 0,
"searchTerm": "world",
"query": ...
}
}
}
]
What we really want is each user ID to be a unique entry with a list of all the matching digests for the given user. To achieve this we make use of aggregations within the search of our index, this allows us to get all the search terms for each unique user, giving us a response that looks something like this:
"userIds": {
...,
"buckets": [
{
"key": 0,
"searchTerms": {
...,
"buckets": [
{
"key": "hello"
},
{
"key": "world"
}
]
}
}
]
}
This is more useful as it tells us exactly what searches have matched for each user. As well as this we have also pushed the majority of the data manipulation work onto the Elasticsearch cluster. This allows our Lambda to run more efficiently, and allows the system to scale better as Elasticsearch can spread the workload over its shards. Finally we remove some of the excess data from the Elasticsearch response so that we can generate an email from the data we are interested in.
We use a loop within the Step Function to iterate through and send all the digests that we have created, however an alternative to this could be to use the AWS Simple Queue Service. While both solutions are valid, the advantage we get from sending the digests via the Step Function are that we can track the tasks and the events for each execution. This gives us the advantage of being able to monitor the system in greater detail.
Daily Methodology
Setup
In order to store daily digests for a user we needed to store mappings of each user ID to a list of search terms that they are subscribed to, therefore a non-relational database such as DynamoDB was the perfect choice. From the search terms we are able to create the relevant Elasticsearch queries for the user at any time to get their digest information. An example user entry could look like the following:

Managing daily digests
Managing the daily digests is similar to managing the real-time digests, we need user ID’s from Cognito and the relevant search terms. From this we can lookup specific users, and then specific entries, within the table to provide functionality for adding, deleting, and viewing existing digests.
As the management functionality is very similar for both the daily and real-time digests we are able to effectively hide the differences in implementation from the frontend system. Restful endpoints can be provided to accept a common input format regardless of the underlying implementation, creating a more intuitive interface. For example a request to delete a subscription for the search term ‘Hello’ could be sent to either the daily endpoint or real-time endpoint with no change to the data sent.
Delivering daily digests
To start the process of sending daily digests we use a CloudWatch Event with a Cron expression to run our scheduledDailyDigests Lambda once a day. This Lambda gets all the entries from our DynamoDB table and for each user starts an invocation of the calculateUserDailyDigest Lambda to handle their subscriptions, this allows us to process each users subscriptions in parallel. The final workflow for this system looks something like this:
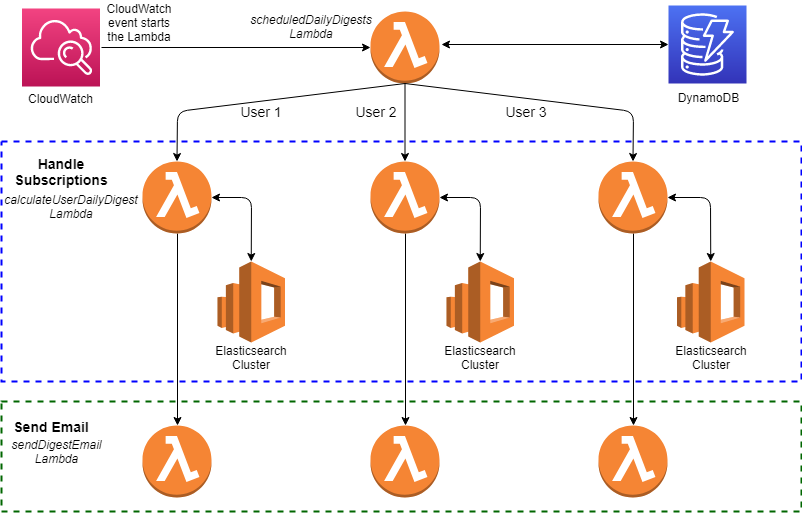
Each calculateUserDailyDigest Lambda creates a multi-search query to run against the Elasticsearch cluster, this allows us to perform all of the user’s daily digest searches at once. This helps improve scalability as we allow Elasticsearch to make use of its shards for efficient data processing. We also avoid overburdening ourselves with having to collate all of a user’s search results together. Most importantly we add a date range to the queries to ensure that all the results are from posts that have been added in the last day, otherwise we would get results for all time and not relevant results for a digest.
Finally we perform some data processing to ensure that we don’t send users duplicate posts. For example a user with subscriptions for ‘hello’ and ‘world’ will match a post of ‘Hello World’ (Elasticsearch is case insensitive) for both subscriptions. Below we can see what we want to avoid in this example and what we can achieve by collecting common results.
What we want to avoid:
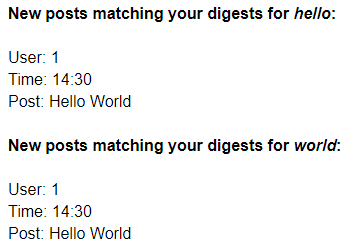
What we want to aim for:

Sending Digests
The sendDigestEmail Lambda accepts a common data format that is shared between both the real-time and daily digests to ensure that users receive emails of a common and familiar format. This also improves the reusability of the Lambda within the system as it is designed to be more generic and not accept data specific to a single use case. Examples of both a real-time and daily digest can be seen below.
Real-time:

Daily:

Digest emails are formatted to ensure that they look the same across the majority of email clients, they also make use of a layout style similar to the frontend of the system in order to appear familiar to the user. The email is broken down into sections containing posts that match a particular digest or number of digests making it easy for a user to consume the data.
Each digest search term within the email contains a link to the frontend that runs the relevant search for the user. This will allow them to view all the results from their search including the posts in their digest and older posts. As well as this there is a link to unsubscribe that links the user to the frontend system where they can delete their subscriptions.
For daily digests we also ensure that the email is limited to a maximum number of posts, this is to ensure that the user doesn’t receive an overload of data. If the limit is exceeded then each digest within the email should display an equal number of posts where possible. The maximum post limit can be configured via an environment variable used by the calculateUserDailyDigest Lambda.
Conclusion
Our goal was to allow a user to subscribe to either real-time or daily digests for their searches, and to deliver this via serverless architecture. Although this required two different solutions we have shown how this can be achieved using a variety of serverless architecture services. Our solutions show how our system could potentially scale up by leveraging the processing power of Elasticsearch and the parellelisation of AWS’s serverless architecture to handle large scales of data.

