
To facilitate frequent and repetitive regression testing of a web application, a robust test approach would involve automating checks at the browser level. A successful automation project of this kind should reduce the manual testing effort and allow detection of defects at an early stage. The overall testing cost should be reduced, and releases should become more frequent.
In practice, it is often difficult to reach the expected results, as browser automated checks can be:
- Slow to execute (compared to unit or API layer tests), and consequently the feedback loop can be slow.
- Flaky: tests that run end-to-end through the UI (the browser) could be non-deterministic, i.e. sometimes pass and sometimes fail. False negatives confuse the team, and need time and effort to investigate. If a test suite shows false negatives very often then real issues might slip through as the team may assume that a failure is a false negative when it is a real defect.
The main component needed to write browser automated checks is a browser controller: a tool that simulates user actions. There are a few Node.js frameworks capable of controlling a browser. The graph below shows the most popular ones (based on the number of downloads) in the last 18 months:
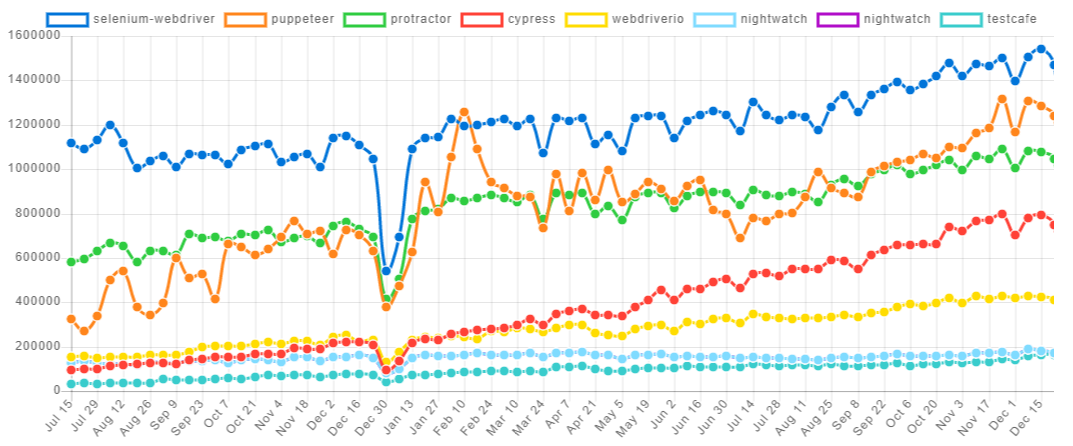
Selecting the most suitable tool contributes to browser automation project success. In this blog, through experimentation, I compare the two most popular browser automation frameworks, focusing on the two points mentioned above (speed and stability):
- Selenium: Selenium has been around the longest (since 2004), and has established itself as the most popular web browser automation tool. It supports a wide range of browsers (Chrome, Firefox, Safari …), and a wide range of programming languages (Java, C#, Python, Ruby …)
- Puppeteer: Puppeteer is much newer (first released in 2017). It was developed by Google for the purpose of automating and simplifying front-end tests and development. It can be used with Chrome or Chromium (which forms the basis of Chrome). It supports only Javascript (Node.js).
Setup:
- Puppeteer: assuming Node.js is installed, setting up Puppeteer is straight forward: just run
npm install puppeteer. This will install Puppeteer, and download a recent version of Chromium that is guaranteed to work with Puppeteer. - Selenium: here we install Selenium with Node.js and Chrome. This is probably the most commonly used setup. Assuming Node.js and Chrome are installed:
- run
npm install selenium-webdriver - download ChromeDriver. A version compatible with the installed Chrome is needed, otherwise this won’t work. This means some maintenance effort of the Chromedriver version will be needed in the future as Chrome gets updated.
- finally add the location of
chromedriver.exeto the system PATH.
- run
Clearly the setup is easier with Puppeteer, and that is because it comes bundled with the browser, and it doesn’t need a browser driver.
Test implementation:
I installed mocha framework to be able to create descriptive automated tests. To run the tests this command can be executed npx mocha --no-timeout.
Now let’s move on to writing some code. Here we try to implement the following scenario:
- Open the browser and access the website developers.google.com/web
- Search for a keyword
- Check that results are shown
- Close the browser.
This is our test implemented using Selenium:
const { Builder, By, Key, until } = require("selenium-webdriver");
const assert = require("assert");
let driver;
describe("search feature", () => {
before(async () => {
driver = await new Builder().forBrowser("chrome").build();
});
it("searching for a valid keyword shows 10 results", async () => {
await driver.get("https://developers.google.com/web/");
let inputField = await driver.wait(until.elementLocated(By.css(".devsite-search-field")));
await driver.sleep(5000);
// Type a keyword into the search box and press enter
await inputField.sendKeys("something");
await inputField.sendKeys(Key.ENTER);
// Wait for the results page to load and display the results.
const resultsSelector = ".gsc-results .gsc-thumbnail-inside a.gs-title";
await driver.wait(until.elementLocated(By.css(resultsSelector)));
// Check if 10 results are shown
let results = await driver.findElements(By.css(resultsSelector));
assert.equal(results.length, 10, "results page did not show 10 results");
});
after(async () => {
await driver.quit();
});
});
And this is the implementation using Puppeteer:
const puppeteer = require("puppeteer");
const assert = require("assert");
let browser;
let page;
describe("search feature", () => {
before(async () => {
browser = await puppeteer.launch({ headless: false });
page = await browser.newPage();
});
it("searching for a valid keyword shows 10 results", async () => {
await page.goto("https://developers.google.com/web", { waitUntil: "networkidle0" });
// Type a keyword into the search box and press enter
await page.type(".devsite-search-field", "something");
page.keyboard.press("Enter");
// Wait for the results page to load and display the results
let resultsSelector = ".gsc-results .gsc-thumbnail-inside a.gs-title";
await page.waitForSelector(resultsSelector);
// Check if 10 results are shown
let results = await page.evaluate(
resultsSelector => Array.from(document.querySelectorAll(resultsSelector)),
resultsSelector
);
assert.equal(results.length, 10, "results page did not show 10 results");
});
after(async () => {
await browser.close();
});
});
Without going into too much detail about the code, the syntax looks fairly similar for both frameworks. There are a few of points to mention though:
- In
puppeteer.launch(), I used the optionheadless: false. Puppeteer runs headless by default, but turning off headless mode to see what the browser is displaying is very useful in debugging. page.evaluate()is a very useful method in Puppeteer: it accesses the DOM of the given page and runs commands as if you were in the console of the browser, and it allows you to use the built-in DOM methods and properties. This makes writing tests easier with Puppeteer as we can run javascript code that accesses the DOM in the console first, check that it returns what is expected, then use this same code inpage.evaluate().- In
page.goto(), I used the optionwaitUntil: "networkidle0". This is used to pause the code execution and resume when there are no network connections for at least 500 ms. This ensures that all the components of the page have finished downloading before we start interacting with it. Selenium does not have a similar option. Instead we can wait for the input search field to be located before interacting with it:
await driver.wait(until.elementLocated(By.css(".devsite-search-field")));
When running the Selenium test, sometimes it passes but sometimes it fails with the error ElementNotInteractableError: element not interactable. The reason is that in this case as soon as we locate the search field, we try to interact with it. But when inspecting the network activity (using Chrome devtools) we can see that the search field can be located before the file named devsite_app.js is downloaded, but this file is needed for the element to be “interactable”. Now, to mitigate this we can set a waiting time of 5 seconds for example (await driver.sleep(5000)). This seems to fix our problem, but it obviously makes the test slower to run.
Results
Now to assess the robustness of the tests, I ran each of them 5000 times (I just wrapped them in a for-loop, and let them run overnight). These are the results of the experiment:
- Puppeteer test was on average 2.2 times faster. Selenium test was slower mainly because of the 5 second sleep in each test.
- Puppeteer test showed great stability and passed all 5000 iterations.
-
~0.4% of the selenium test iterations failed:
- Most of the failures are due to the error
ElementNotInteractableError. It seems that waiting for 5 seconds was not enough is some cases. This might be improved if we increase the waiting time, but this would make the test much slower. - Two other failures were seen a couple of times each:
WebDriverError: chrome not reachableandError: Server terminated early with status 1. These could be explained by the loose coupling between the browser controller (Selenium) and the browser. The coupling is tighter between Puppeteer and Chrome as they are installed together from the same parent (Google).
- Most of the failures are due to the error
By the way, 0.4% probability of false negatives per test might not sound high, but in a test suite of dozens of tests running several times a day in a CICD pipeline, a false negative is likely to appear every day.
Conclusion
To conclude, after experimenting with both tools:
- Puppeteer was easier to setup, as it comes bundled with the browser, and it doesn’t need a browser driver.
- Puppeteer test was easier to write, mainly thanks to
page.evaluate()method. - Puppeteer test was faster to execute, as there was no need to configure an explicit sleeping time.
- Most importantly, Puppeteer test was more reliable, mainly thanks to the tight coupling with the version of Chromium it comes with, and to
waitUntil: "networkidle0"option.
So should anyone chose Puppeteer over Selenium?
Selenium still has an important advantage which is cross-browser support. However, this comes with more issues related to the interoperability between Selenium, the browsers drivers and the browsers, and thus more flakiness. Also if a team estimates that the big majority of product defects are not browser specific, then running the automated checks only against Chrome and manually smoke testing in other browsers could be a good strategy.
I hope this helps you make more informed decisions when it comes to web automation rather than automatically using the most popular tool.

