
This year I’m attending the Linux Foundation Europe Summit, a sizable event bringing together 1,000s of people involved in open source. I typically take extensive notes of the sessions I attend, so thought I’d share them here on our blog.
This is the final day of my journal, where day one was all OSPOs, SBOM security, and AI and day two was surveys, statistics and the fragility of the node ecosystem. On the final day there was yet more AI and the looming shadow of the EU Cyber Resilience Act (CRA).
If you’re interested in the details, then read on!
Keynote
The day’s keynote kicked off with an announcement from Linux Foundation AI & Data, who have launched the Generative AI Commons. This effort is split into multiple work streams looking at LLM architectures, the hosting of models and datasets, education and outreach and a framework for evaluating the openness of ML models. Also, RWKV, an RNN with capabilities that claim to match those of more modern transformer architectures, has recently joined LF. Definitely one to look into if you’re self-hosting models.
Next up, Cristina Bentué presented a talk titled “Software Security: You are the Calvary”, a reminder that security is everyone’s responsibility, and not something that can be retro-fitted to an application just before release.
Jonathan Katz, a technical lead from AWS and PostgreSQL core maintainer discussed some of the lessons they’ve learnt. PostgreSQL has a ~15% share of the relational database market, meaning that it is incredibly widely used. It is relied upon by millions of people and businesses, as well as service providers, such as AWS. One thing I found fascinating was that the project isn’t hosted on GitHub, instead, it has self-hosted git repositories, a wiki, mailing lists and a contribution process that involves ‘hackers’ emailing patches. This has some proper old-school charm, but clearly works for them. It also goes to show how diverse open source communities and culture can be.
In sharp contrast, Patrick von Platen who is the maintainer of the HuggingFace Transformers and Diffusers libraries, talked about how they have coped with the explosive growth in ML. It couldn’t be more different than the approach taken by the PostgreSQL team. The Transformers library is a collection of ~250 ML models, which attracts around 20 pull requests each day. In order to maintain this cohort of models, they very much favour simplicity and decoupled code. Models are single files, without any common abstractions. This makes each model independent and easy to understand.

The final keynote talk was delivered by Fatima Sarah Khalid, a Developer Evangelist at GitLab. She started by discussing what sounded like an idyllic childhood, tales of eating raw noodles with friends! However, it all comes crashing to an end post 9/11, when her best friend tells her they cannot be friends any more because her mother says “you are a terrorist”. She continued to talk about the tools in your “allyship knapsack”, education, speaking up, amplifying marginalised voices, but reminded us that this is meaningless without practice. A very powerful end to the final keynote.
Cyber Resilience Act (CRA) panel
While I’ve heard about the CRA, I’ve not really delved into the details, thankfully Mirko, who hosted the panel, gave us a quick introduction. Here are the highlights …
The CRA affects anyone delivering products to EU customers and makes suppliers of software responsible for fixing vulnerabilities, providing updates and providing evidence of audit of certifications. As of now, (Sept 2022 draft):
- Individual developers are not affected, if their work is non-commercial. It would appear that ‘tip jar’ commercial arrangements are fine but regular sponsorship is considered commercial. As an open source developer who runs an Open Collective, I’m assuming the CRA will apply to me!
- Non-profit organisations are not excluded from CTRA
- Private companies clearly have no exception
The CRA has a sensible risk-based classification, where non-critical applications can self-assert, low-risk (e.g. browser) can use a standards-based assertion, and high-risk applications (e.g. Hypervisors, operating systems, containers) must have a mandatory 3rd party assessment.
The CRA also requires documentation on SBOMs, design / development processes, any EU cyber standards that the product meets, and a signed EU declaration of Conformity.
These are some quite onerous requirements.
Mirko, and everyone in the panel shared the same fundamental concern, the CRA doesn’t distinguish between open source development, where people typically share libraries and infrastructure components, from bringing products to market, most often in a commercial setting. Everyone agrees that more ‘pressure’ needs to be put on commercial organisations who sometimes knowingly shop vulnerable products. But the blanket application of these requirements is so clearly at odds with the way open source works, that many in the community see it as quite ludicrous.
Every open source licence includes a “without warranty” clause states it is consumed “as is”. The CRA undermines one of the most important components of the open source licence that is vital to ensuring this is a vibrant and creative community going forwards.
Panellists speculated whether this would result in open source libraries declaring that they are “not for EU consumption”. If the CRA in its current form passes, this could certainly become a reality.
Asymmetries in open source
The final session I attended was presented by Adrienn Lawson, an analyst from Linux Foundation Research, who we worked closely with on the ‘state of open source’ in Europe report that was announced earlier in the conference. In this session Adrienn took a look at the global results, taking the opportunity to highlight the gap between consumption and contribution. I think the following chart neatly summarises the gap:
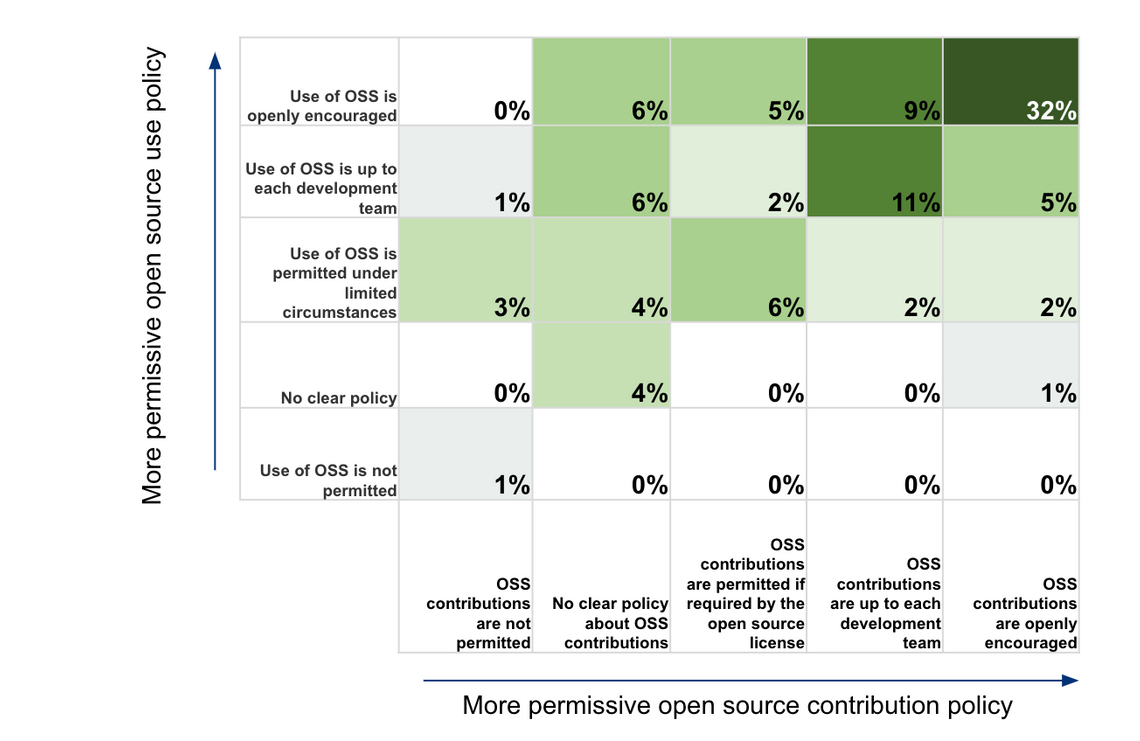
The vertical and horizontal axes indicate how permissive an organisation’s policies are with respect to consumption (horizontal) and contribution (vertical). The diagonal represents organisations that have equally permissive consumption and contribution policies. However, in practice we see a skewing of the data towards the top-left quadrant of the chart, indicating an imbalance between the two. Contribution policies are generally less permissive than consumption.
A fantastic illustration of one of the key problems facing open source.
And that’s a wrap
My parting thought from the conference is that there is no shortage of activity and excitement in the world of open source. It is deeply involved in every aspect of the diverse world of software engineering; innovation, culture, legislation and regulation. A three day conference hardly does it justice!