
Introduction
In our continuous pursuit of refining Scottbot, our LLM-powered chatbot, we have encountered and overcome various challenges. The implementation of Test-Driven Development practices and comprehensive testing, a topic previously explored in a dedicated blog, was a particularly difficult one due to the non-deterministic nature of the Language Learning Models (LLMs). Despite conquering these initial obstacles, a new challenge emerged – one that revolved around managing the costs associated with testing. In this blog post, I will explore the intricacies of this cost challenge and outline the strategic measures we undertook to streamline our test suite, thereby reducing expenses and optimizing our testing processes.
Understanding our testing approach
Our testing framework treats the application as a black box - it sends a prompt and evaluates the final response without considering how that response was generated. Given the non-deterministic nature of the underlying LLM, relying on string comparisons to judge the response’s quality would be futile. Instead, string comparison is reserved solely for verifying the presence of URLs in the response. One of Scottbot’s requirements was to always cite the source of the information it used to generate a response and, as a result, every response was expected to contain a link to the relevant document. To accurately assess the quality of the bot’s output, we employ a secondary LLM that evaluates the response against a set of reference information we provide. Moreover, recognizing the inherent variability in the LLM’s outputs, we do not rely on single-instance testing. Multiple runs are conducted for each prompt, and the results are assessed on an average basis to account for the LLM’s non-deterministic behaviour, thus providing a more robust measure of performance. You can read more on how statistics can be utilised to address randomness here.
New challenges
It should be no surprise that our solution to the non-deterministic nature of our application lead to a new challenge – a significant increase in operational costs. While our project budget was not immediately threatened and we expected that LLM costs would decrease over time, we recognized the importance of resource efficiency, especially since this project served as a training ground for our team.
The financial aspect, although important, was not the only consideration; we were equally conscious of our environmental footprint, acknowledging that every computation has a tangible impact on our planet. Moreover, the introduction of the evaluation LLM and the multiple tests runs along with the inherent latency in LLM responses, increased the duration of our test cycle substantially. This had a knock-on effect on our development cycles, slowing down the pace at which we could deliver new features and improvements. Therefore, we recognised that optimizing our test suite was essential.
Caching
Caching was naturally the first solution we explored. The Langchain library, which is a cornerstone of our project, offers a caching mechanism for storing responses to prompts that are frequently used. We started with caching the bot’s initialization process which involves an LLM call – specifically sending an initial message along with the system prompt. To prevent any interference between our tests, it was crucial to clear the bot’s memory and re-initialize it after each test. Therefore, caching this call made a notable improvement.
Our testing methodology often involved sending the same prompts multiple times to thoroughly evaluate different facets of Scottbot’s capabilities, including response accuracy, tone consistency, and the provision of URL sources. By splitting these prompts into separate tests, we gained a granular insight into the bot’s performance. Caching was instrumental in this, as it allowed us to repurpose the LLM’s responses across various tests, significantly streamlining the process. In conclusion, caching resulting in cutting down on the number of LLM requests and therefore reducing the cost and duration of our test suite.
Rethinking our testing strategy
Despite the benefits of caching, we quickly realized that it was not the silver bullet for our cost issues. The crux of the issue lay in the numerous calls to the LLM required to generate just a single response. For every user query the application uses:
- An LLM-powered agent to decide which tool to use to retrieve the necessary information.
- An LLM-powered tool (or multiple).
- An LLM to combine the information returned by the tool along with the conversation context to generate the final response.
This led to us re-evaluating our testing strategy – perhaps black box testing was not the optimal approach as it makes it impossible to avoid any of the aforementioned LLM calls. Consequently, we began exploring how we could break down our monolithic test suite into smaller, more focused tests that target specific components of the pipeline. The advantages of this approach were immediately apparent. First, it would be cheaper to run since we could now target specific parts of the application rather than the whole. Second, it would pinpoint exactly which component was failing, thereby simplifying the debugging process. The subsequent sections will delve into how this was implemented.
Agent decision-making tests
The first component to isolate is the agent’s decision-making process, which is illustrated in the diagram below.
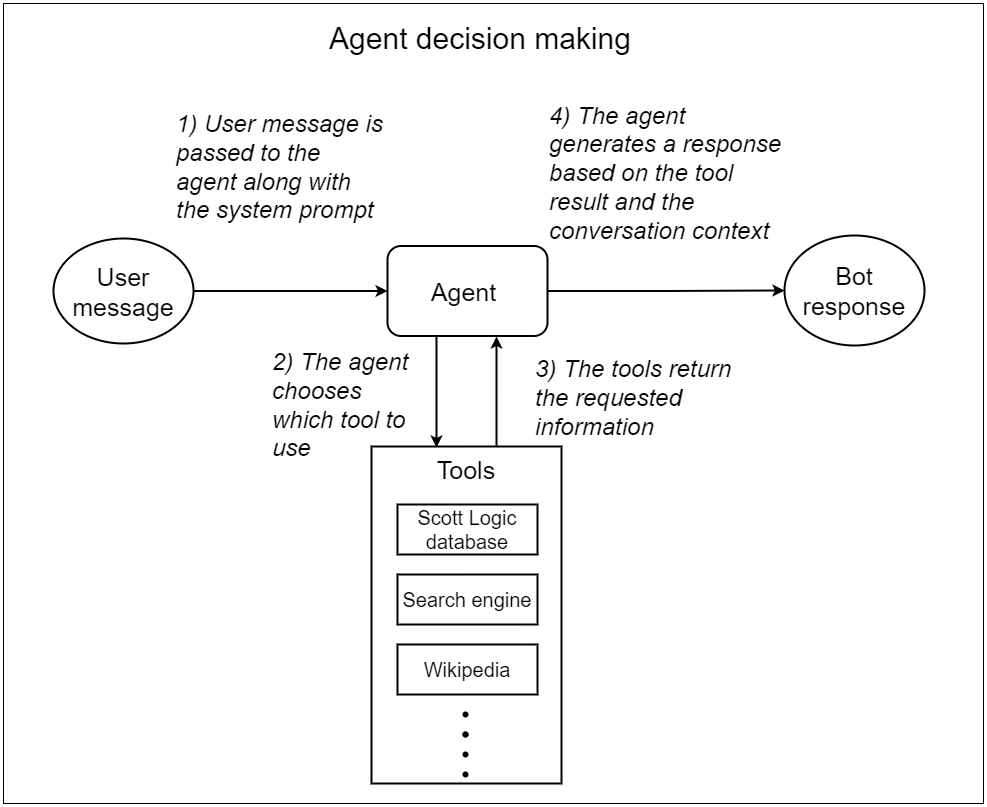
It is easy to understand if the agent selects the incorrect tool, the bot’s final response will be flawed. Therefore, there is no need to actually invoke the tool or evaluate the final response. Based on this, we designed a test suite to assess the agent’s tool invocation abilities. This suite evaluates which tool the agent chooses and the input it uses it with, in response to a given prompt. As each test need just a single LLM call, they are significantly cheaper and faster.
These tests became particularly useful when we implemented changes that could affect the agent’s decision-making process. Examples of such changes are modifying the system prompt, the agent type, the tools’ descriptions, or the agent’s underlying LLM.
Vector store retrieval tests
The next component to isolate was the vector store retrieval process. All internal documents that the bot needs to access to reply to Scott Logic-related questions have been converted into embeddings and been stored in a vector database. During runtime, Scottbot conducts a similarity search based on the user’s query to retrieve the most relevant document(s). These documents, along with the user’s question, are then passed to the LLM, which attempts to generate an accurate answer. A diagram of this process can be seen below.
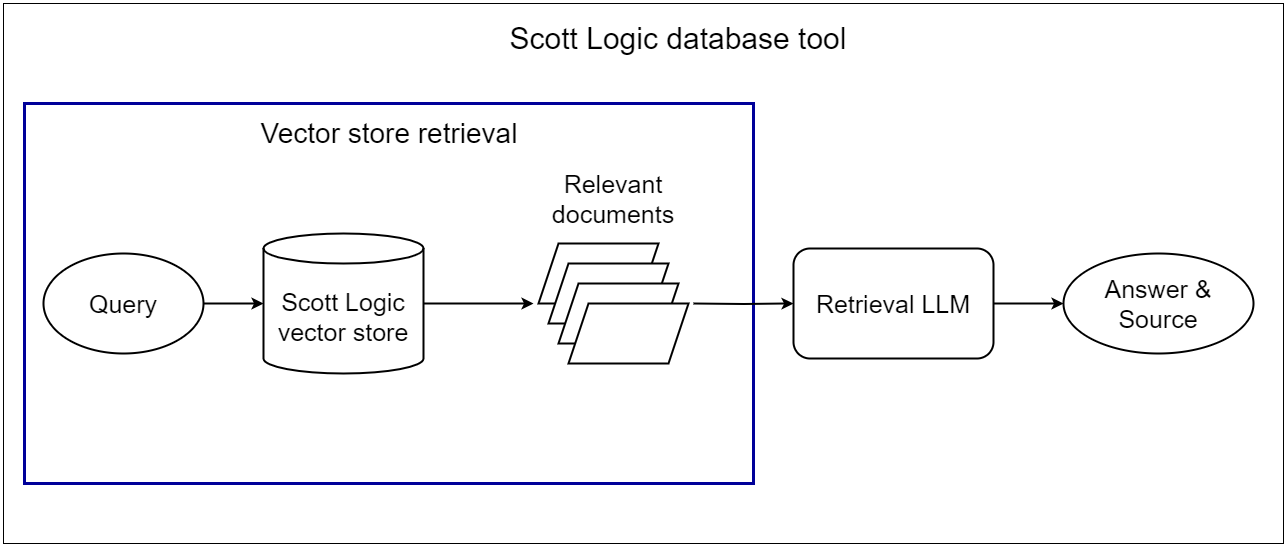
The accuracy of the bot’s response is heavily dependent on the vector store’s ability to return the correct documents. If the retrieval process is flawed, the responses will inevitably be inaccurate. Therefore, we developed a dedicated test suite focusing on whether the vector store retrieves the correct documents for a given query.
This suite was particularly helpful when changes were made that could impact the retrieval process. For example, modifications to the similarity search algorithm, its configuration, the document-to-embedding conversion process, or the document segmentation to accommodate the LLM’s context.
One of the key advantages of isolating the vector store retrieval process is that it does not rely on any LLM calls – this process is completely deterministic. This results in tests that are not only cost-effective but also rapid, providing us with the ability to swiftly identify and rectify any discrepancies in the retrieval process.
Retrieval QA Chain tests
Finally, we isolated the last part of the Scott Logic tool – the invocation of the Retrieval QA Chain. This process involves providing the LLM with the context fetched from our vector store and the user query and asking it to generate an answer.
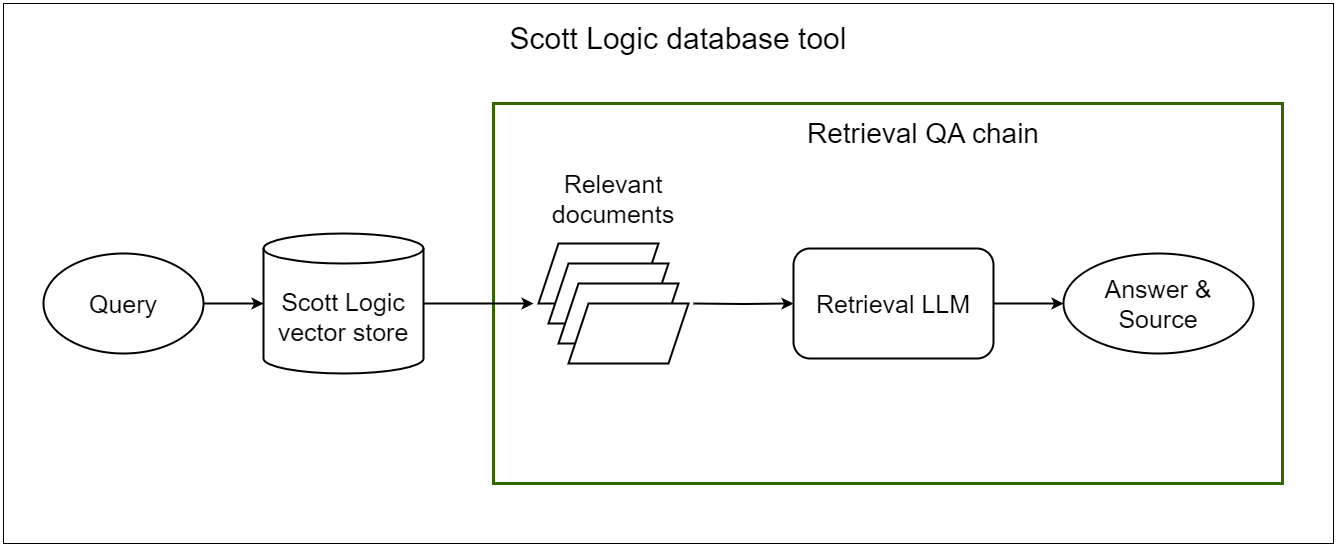
Assuming the provided context is adequately comprehensive, these tests can provide various insights. Through these tests, we were able to adjust the configuration settings of the Retrieval QA Chain. This included determining the ideal number of context documents to utilize from the vector store and the most effective method of presenting them to the LLM — be it through appending the documents or generating a synthesized summary. Moreover, the tests facilitated a comparative analysis of various LLMs, enabling us to identify the most suitable model for the question-answering part of our application.
Finally, these tests provided an easier way to ensure the source is consistently provided. This is because the response of the retrieval QA chain is a dictionary with an answer and a source key, instead of a natural language response. Therefore, we could easily check with simple code whether it is empty instead of relying on a secondary LLM to evaluate the final response of the bot.
Conclusion
Throughout the development of Scottbot, we have faced the complex challenges inherent in testing AI-powered applications. The non-deterministic nature of LLMs, coupled with the cost incurred with each usage, means that conventional, end-to-end black box testing is not cost-effective.
Nevertheless, there are always strategies to enhance testing efficiency and manage resources more effectively. For us, implementing a caching system for commonly used LLM responses and breaking down our monolithic test suite into focused, component-specific suites, reduced our operational costs and opened new ways for improving the application’s performance. A key takeaway from this project is that the diligent design of a cost-effective test suite from the beginning important and depending on the budget, might be necessary.

