
The EU’s impending Digital Operational Resilience Act (DORA) aims to strengthen the IT security of financial entities such as banks, insurance companies and investment firms across Europe. The UK has also applied a high degree of focus on operational resilience in recent years, with the implementation of a new ‘Operational Resilience’ regime in March 2022; the deadline for full implementation of the regime and fixing vulnerabilities is 31 March 2025.
While the regulations will standardise ICT risk management, business continuity, and incident response, they won’t recommend best practice resilience strategies that banks should adopt.
In this blog post, I want to share one such resilience strategy – Monzo’s – which I think is a very smart approach to Operational Resilience and DORA. But I’ll start with an overview of what prompted these resilience regulations and look at why traditional resilience strategies will put your organisation at significant reputational risk.
What prompted these operational resilience regulations?
The growing adoption of cloud technologies across financial services played a key role in the origins of both DORA and the UK’s Operational Resilience regime. In the days of on-premises hosting of banking systems, outages presented self-contained risks to the banks that suffered them. But we’re now in an era in which the big three cloud hyperscalers – Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) – host critical infrastructure for banks across the globe. If one of those hyperscalers has a major outage, it could have a significant economic impact.
The four key areas of the Bank of England’s Operational Resilience regulations are governance, operational risk management, business continuity planning, and the management of outsourced relationships. The key pillars of DORA are regulations covering ICT risk management, ICT third-party risk management, digital operational resilience testing, ICT-related incidents, information sharing, and oversight of critical third-party providers.
Traditional resilience strategies are no longer sufficient
Many companies have hinged their Business Continuity Plans (BCP) for Operational Resilience on backup/standby systems (or components), waiting for the worst to happen before being called into action. These traditional cold and warm standby systems are often slow (taking hours or days to operationalise, if very manual) and error-prone, with a risk of data loss. The regulators expect financial services companies to do more, and Operational Resilience and DORA are key pieces of regulation that will enable penalties to be imposed on those companies which fail to comply.
There are plenty of recent examples of significant outages, including TSB fined £49m over a system outage, HSBC being down for over 24 hours, and a Barclays Payments Systems outage. A lot has been written about why the TSB failure was so big, including this excellent article. Once the TSB go-live had occurred, it was quickly apparent that not all the required functionality had been thoroughly tested. In fact, TSB drove ahead with a migration date without any means of confirming whether all the functions were operating correctly once the switchover happened. As I’ll now go on to explain, if TSB had followed a similar approach to Monzo, it would have avoided the outage, the fine, and the reputational damage.
Monzo’s Live Alternate System: A game-changer
Due to their decentralised architecture, modern scale-out technologies like Cassandra and Kafka (when used correctly) can offer automatic failure handling and reduced downtime. They also reduce the need to switch manually to cold or warm backup systems.
But Monzo has gone further.
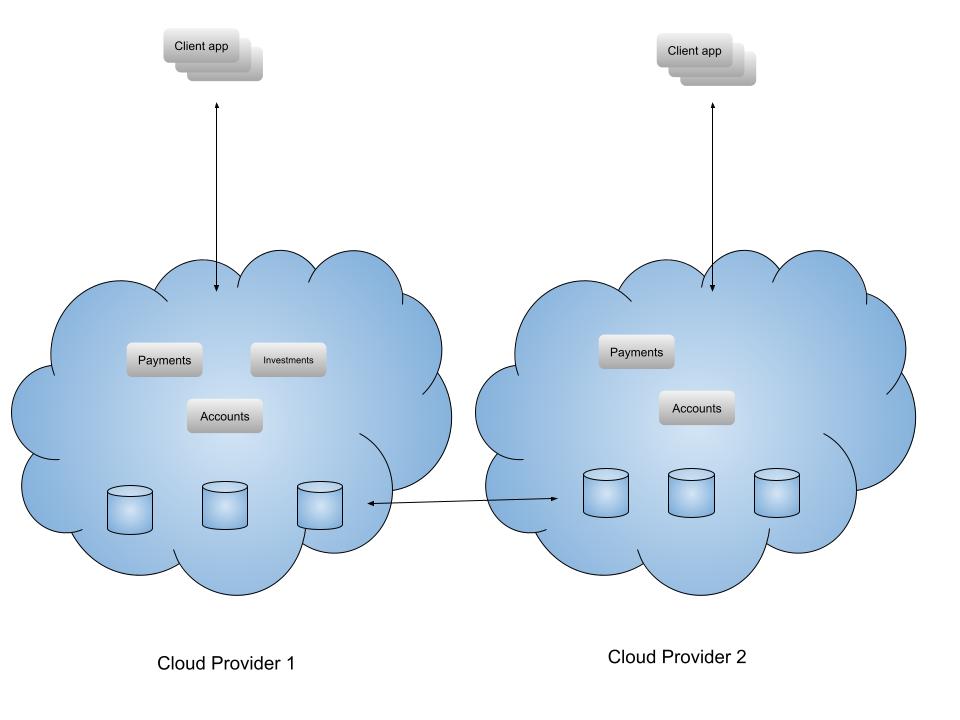
Born out of the UK’s Operational Resilience regime, Monzo’s innovative strategy (announced on a couple of LinkedIn posts) involves running a live alternate system on a different cloud provider, continuously handling a portion of live traffic. This approach – called Monzo Stand-in – provides real-time monitoring and ensures seamless failover in case the primary provider has an outage or experiences significant service degradation. This removes the need for complex Business Continuity Processes (and all the costs involved in planning and running them), as the backup systems are being tested continuously as a first-class citizen in the production environment.
To do this, each day Monzo randomly selects a tiny group of customers to complete their tasks in the ‘emergency mode’, which offers core banking functionality (e.g. viewing your account, making bank transfers, moving money between accounts). This allows Monzo to test whether or not these tasks can be completed successfully in the alternate system, with any issues being flagged for resolution. In the event of Monzo’s primary cloud provider suffering an outage, the bank can rapidly scale up its alternate system and move customers across. This ensures smooth continuity of service without the need for manual technical intervention to reconfigure the system, and all the risks associated with that.
While implementing such a system requires careful planning and investment, the long-term benefits in terms of resilience and risk reduction are significant: reduced BCP tests, automated failure handling, and minimised downtime. The running costs can be very similar. The traditional approach of having cold or warm standby systems requires complete replicas of all key systems, with charges building up continuously, regardless of whether those servers are being used. In Monzo’s live/live approach, you have pretty much the same number of servers, they are just all being used. So depending on exactly what technologies you use, the hardware costs can be comparable.
Conclusion
If TSB had followed a similar approach to Monzo, it could have started running a small amount of its customers’ data flow through the new system, while also running the same functions in the old system and comparing the outputs. The issues would have been highlighted quickly, allowing the customers to be moved back quickly to the old system until the issues were resolved.
Monzo’s success story exemplifies how embracing modern IT practices, such as scale-out technologies and live alternate systems, can be a starting point to revolutionise resilience and streamline compliance with the UK PRA Operational Resilience regime and DORA. As the examples from TSB and HSBC demonstrate, manual processes and risk mitigation aren’t as good as automated checks and balances, which are built in to the Monzo approach.
It does require careful planning and investment to design in resilience from the outset, but the benefits are reduced risk, lower costs, and happier customers. And in the end, that is what Operational Resilience is all about.
.jpg)