
Last year, we were given the task to create a conference talk-assignment-algorithm, for our company’s internal conferences. In the first blog, we explored how to assign talks in a single time slot, which is really the bedrock of the algorithm. However, looking at the bigger picture, being fair across multiple time slots is also highly important.
We would not want the same attendees to always get their second choice, or worse still their third choice across multiple slots. Therefore, to be able to empirically measure this, we conceptualised the amount by which a single attendee has received different choices in the past as a value called “compromise”. For example, an attendee didn’t get their first choice, so they had to compromise with a second/third choice.
This time we will discuss how we measured compromise, and then explore its interesting interplay when sorting with surplus difference.
Compromise
Every time slot, attendees are given a slot compromise score according to what choice they were assigned. The greater the score, the more the attendee has had to compromise on their choice. We believe people are generally not too concerned about getting their 2nd choice, but comparatively a lot more disappointed to get their 3rd choice. Therefore we made the slot compromise score grow at an increasing rate. For example, the 3rd choice over the 2nd choice is worse than getting your 2nd choice over your 1st choice.
Therefore, we decided the compromise for each choice should be:
- 1st choice: 0 (no compromise at all)
- 2nd choice: 2
- 3rd choice: 5
Take note of the incremental difference between first to second and second to third - the slot compromise score becomes increasingly worse.
The Slot Compromise Formula
This is based on the formula: \[Cₙ = n + Cₙ₋₁\] where \(C\)ₙ is the compromise for the nth choice and \(C1 = 0\).This can also be reformulated to: \[Cₙ = \frac{(n-1)(n+2)}{2}\]
Looking back however, perhaps getting your 5th choice or your 6th choice wouldn’t be much different so perhaps choosing a curve that tends to a fixed value would be better (perhaps of the form \(1-\frac{1}{x}\)), as we have done with surplus difference. In any case, there were only 3 choices per slot for our application, so this worked fine.
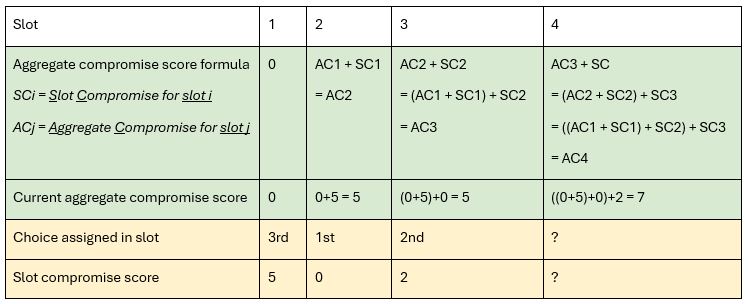
This slot compromise score is accrued after every slot assignment is added to a user’s aggregate compromise score. As it says on the tin, this tracks how much an attendee has had to compromise across multiple slots.
So for example, imagine an attendee, Alice over the course of 3 time slots, is assigned:
- First slot: 3rd choice
- Second slot: 1st choice
- Third slot: 2nd choice
Her slot compromise scores would be 5, 0, 2 respectively. Therefore, her aggregate compromise score before each slot assignment would be:
- Slot 1: 0 - she hasn’t had to compromise yet
- Slot 2: 5 - so they are more likely to receive a better score in this slot
- Slot 3: 5 again - they got their first choice in the previous talk, no change
- Slot 4: 7
As seen in the table below.
Sorting with Compromise
To be as fair as possible to all attendees, we want to make sure people who have a higher compromise score take precedence over those who have had to compromise less in the past.
Let’s introduce a new attendee, Bob, with exactly the same votes as Alice (to bypass surplus difference sorting). We also assume that each talk has only capacity for one attendee, like a one-to-one. There will be another arbitrary attendee who takes the places that Alice and Bob do not, but we won’t consider their score in this example. This is how the compromise score would affect the outcome between Bob and Alice.
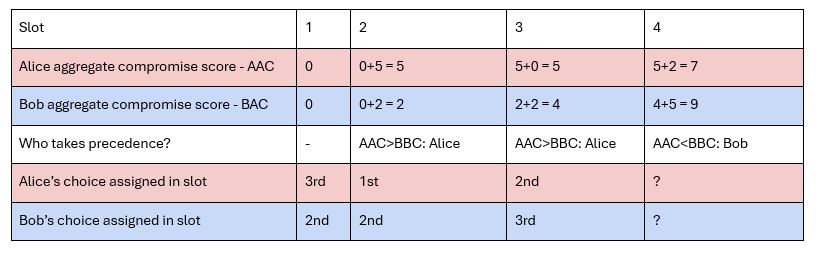
- Slot 1: Bob is given his 2nd choice (chosen arbitrarily), so his aggregate compromise rises to 2. However, Alice is given her 3rd choice and so has had to compromise more in this first round. In slot 2 Alice will take precedence over Bob.
- Slot 2: Alice gets her first choice, Bob gets his 2nd choice. Even though Bob gets a worse score than Alice in the second slot, Alice’s aggregate compromise is higher. This is because she was given her 3rd choice in the first slot and we consider one 3rd choice worse than two 2nd choices - refer to the slot compromise formula.
- Slot 3: Alice gets her second choice and Bob gets his 3rd.
- Slot 4: Bob’s aggregate compromise score has surpassed Alice’s, and so he will take precedence in choice here.
Sorting Compromise and Surplus Difference
This is where things get interesting. Compromise measures how much a user has been assigned talks which have not been their 1st choices. Surplus measures the repercussions of giving a user a worse choice. In short, Compromise is a conference scoped measure of fairness, Surplus is a slot scoped measure of fairness. Comparing these correctly will mean the users will be ordered in a way that will minimise overall compromise.
Prioritising compromise sorting will mean that everyone will tend to have a similar compromise, but as a whole there will be more compromise. Prioritising surplus difference sorting will mean that less compromise is made as a whole, but the spread of compromise may be uneven.
Let’s look at the example from the last blog:
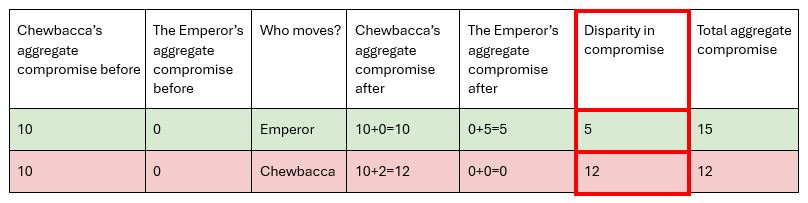
If Chewbacca’s aggregate compromise was greater than the emperors, then the sorting at slide 6 becomes quite nuanced. Say Chewbacca’s aggregate compromise is 10 and the Emperor’s is 0 (we ignore Darth Maul for this example, imagine he had a very high aggregate compromise of 20+). Then in this case we wouldn’t want Chewbacca to compromise any further, especially compared to someone who hasn’t needed to compromise at all yet. Therefore, the Emperor would take the 3rd choice and Chewbacca his 1st. Although this would mean the total compromise made between these 2 characters is greater (0+5=5 for the Emperor’s 3rd choice, over 2+0=2 for Chewbacca’s 2nd choice), it is still a fairer decision so that Chewbacca is not always compromising. This is prioritising sorting by compromise.
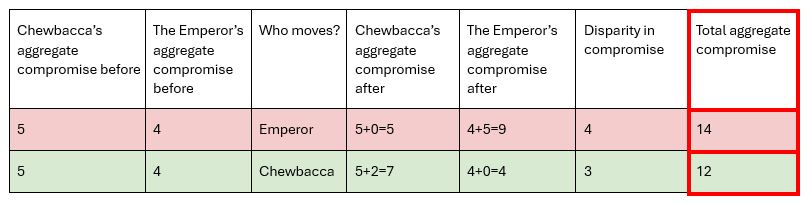
However, if Chewbacca’s aggregate compromise was 5 and the emperor’s compromise was 4, we would want a different outcome. Since the difference between the two aggregate compromises is small, we would rather Chewbacca move and have his 2nd choice (and have an aggregate compromise of 7) rather than the Emperor to take his 3rd choice, shooting his aggregate compromise from 4 up to 9. I would argue therefore that Chewbacca should take his 2nd choice shown in the slideshow, meaning Chewbacca would have an aggregate compromise of 7 and the Emperor have an aggregate compromise of 4. This is prioritising sorting by surplus difference.
All of this is to say, we can’t sort one way after the other, we need to sort compromise and surplus difference simultaneously to cover all circumstances. Capturing these nuances in an algorithm however is easier said than done. Aggregate compromise, by nature, increases in size every slot so it is hard to compare with surplus difference, which remains roughly within the same range.
To dive deeper, click here
For example, in slot 2, aggregate compromise per attendee could range from 0-5 (1st choice = 0, 3rd choice = 5), but in slot 10, the aggregate compromise per attendee could range between 0 and 50. Ignoring the fact that the algorithm would not be working very well if one person had 10x 3rd choices (giving an aggregate compromise score of 50)!However, in both slot 2 and 10, the average surplus difference may be within the range of -6 and 6, assuming the average room surplus is 3. See the first blog in the series for how the surplus difference is calculated.
We considered normalisation, however, the highest value (no matter whether an outlier or close to the average) is always 1, meaning it is not a good indicator of the significance of compromise. If we think back to the example comparing Chewbacca and the Emperor, if there existed a large outlier of aggregate compromise, such as Darth Maul having 20+, then irrespective of whether Chewbacca had 10 or 5 for aggregate compromise, Chewbacca’s normalised aggregate compromise would be relatively similar in the two cases, and therefore distinguishing whether the difference between two attendees’ normalised aggregate compromise is significant would be difficult. Especially if the situations are more subtle.
Finally, we landed on using the Z-score for aggregate compromise. The Z-score is a statistical value which measures how many standard deviations (a measure of spread) a dataset value is from the average. This means that compromise will play a more significant role in sorting when the aggregate compromise value is an outlier, however it would have a relatively small effect if the value is close to the average of the attendees’ aggregate compromise, no matter how large the compromise or the surplus is.
Comparing Compromise and Surplus Difference
The value which we use to sort attendees can be calculated as: \[ \begin{align} \text{sorting score} \; = \quad \; &\text{standardisedSurplusScore} \\ -\; &\text{standardisedCompromiseScore} \end{align} \]
Where the \(\text{standardisedCompromiseScore}\) is:
\[ \begin{align} standardisedCompromiseScore \; = \quad \; &\left( \frac{\text{mean surplus difference}}{\text{max surplus}} \right) \\ \\ \times \; &\left( \frac{\text{attendee Z score}}{2.72} \right)^3 \end{align} \]N.B. The Z score is calculated with the median to avoid extreme value skewing.
And the \(\text{standardisedSurplusScore}\) is:
\(\text{if } maxSurplus \neq 0 \text{ and attendee surplus difference} > 0 \text{:}\)
\[standardisedSurplusScore = \frac{\text{attendee surplus difference}}{\text{max surplus difference}} \](here max surplus will be positive)
\(\text{if } maxSurplus \neq 0 \text{ and attendee surplus difference} < 0 \text{:}\)
\[standardisedSurplusScore = \frac{\text{attendee surplus difference}}{| \text{min surplus difference} |} \](here min surplus will be negative)
\(\text{if } maxSurplus = 0 \text{:}\)
\[standardisedSurplusScore = \text{attendee surplus difference} \]The rationale behind this was as follows:
The \(\text{standardisedSurplusScore}\) should be in comparison to the maximum value, otherwise the compromise would give an extreme value. We want the compromise to be in the same range of values as the \(\text{standardisedSurplusScore}\), except for the outlying compromise, and therefore \(\frac{\text{mean surplus difference}}{\text{max surplus}}\) brings the \(\text{standardisedCompromiseScore}\) into the relative range of values, and \(\frac{\text{attendee Z score}}{2.72}\) should be in the range of \(\pm 1.3\), with the larger values being extremal. When this overtakes the \(\text{standardisedSurplusScore}\), (surpassing the value just greater than 1), we want this to occur quite rapidly because extremal compromise is much more important to deal with. Therefore we cube it. Cubing not only rises quickly, but unlike squaring, it maintains the sign, which is important for capturing whether the value is above or below the median. After some fine tuning, it also appears to give an optimal result.
The value of 2.72 comes from the fact that for a normal distribution, 95.4% of values are found within 2 standard deviations of the average and 99.7% of values are found within 3 standard deviations of the average. This gave a rough range between 2-3 and after some fine tuning, 2.72 gave the optimal result.
Conclusion
In this blog we have seen how we can measure and maintain fairness across multiple time slots using the idea of compromise. We have also seen how this interacts with sorting surplus differences and how it’s important to find a balance between the two. In the next and final post in this series, we will look at how ordering time slots can make a significant difference to the outcome of the algorithm, along with concluding how the algorithm comes together as a whole.