
As AI coding tools have become ever more powerful, taking on sizeable programming tasks with autonomy, the industry is pondering how we adapt our processes to capitalise on the strengths of this technology and address its weaknesses.
Spec-Driven Development (SDD) is a new approach designed around agentic AI where polished specifications become the single source of truth, guiding AI agents to reliably generate working software.
Intrigued by the idea, I decided to put SDD to the test using Spec Kit, rebuilding a feature from one of my hobby apps to see how this workflow holds up in practice. The experience wasn’t great, a sea of markdown documents, long agent run-times and unexpected friction. While SDD is an interesting thought experiment, I’m not sure it is a practical approach.
To find out more about my experiences, read on …
What is Spec Driven Development (SDD)?
When you first start using AI agents first challenges you wrestle with is just how much detail to give it in each instruction. Is it better to guide it towards your goal through multiple, single sentence instructions? Or provide it with a more detailed paragraph of text, hoping that it will successfully write a bigger increment in a single go?
A year or two ago, when these tools were relatively immature, it was generally more effective to work in small increments. Larger increments rarely worked effectively, leading to more time spent debugging and ultimately a longer journey to reach your goal.
Just under a year ago I recall reading Harper Reed’s excellent post titled “My LLM codegen workflow atm”. where he outlined the process that worked well for him. Rather than provide a longer prompt (i.e. a few sentences / paragraphs), hone the idea in conversation with an AI chat, pass it to a reasoning model, and ask it to build detailed plan. Once you’ve reviewed the plan, ask the coding agent to implement. I tried the approach myself and found similar results – I was able to implement larger increments armed with this plan. Harper noted that this process works best for greenfield projects.
As an aside, it’s amazing how much things have changed in less than a year. I’ve re-read Harper’s blog and it already feels very dated, through no fault of the author, it was ground-breaking stuff, for a month or two!
Pick a framework …
I wanted to give SDD a try, but there are growing number of frameworks and approaches to choose from. Here are a few notable projects and tools relating to this nascent approach:
- GitHub Spec Kit (Sept 25) - An open source, AI agent agnostic toolkit, that encodes a multi-step spec workflow (Constitution → Specify → Plan → Tasks → Implement → PR)
- Tessl Framework and Registry (Sept 25) - A startup, “Tessl is pioneering spec-driven development”
- Amazon Kiro (Nov 25) - Amazon’s offering that “helps you do your best work by bringing structure to AI coding with spec-driven development.” (Requirements → Design → Tasks → Implement → PR)
While these tools all provide a form of SDD, their workflow to differ quite a bit. I’d definitely recommend reading Birgitta’s post which outlines three different levels, spec-first, spec-anchored and spec-as-source, which helps to understand the differences.
Of the above frameworks Spec Kit adheres to SDD in the purest form (spec-as-source). Here is a paraphrased version of their introduction to the topic:
Traditional development treats code as the source of truth, causing specifications to drift, creating a gap.Spec-Driven Development reverses this by making the specification the primary artifact that from which you can generate implementation plans and code. Specifications become precise enough for AI systems to produce consistent, working software directly from them.Maintaining or extending a system means updating the specification and regenerating code rather thanmodifyingcode manually.Debugging and refactoring involve clarifying the specification, allowing teams to focus on design clarity and problem-solving.
It is also wildly popular, having attracted 50k GitHub stars in just a couple of months.
I decided to take Spec Kit for a spin.
The challenge
Over the past few months, I have been vibe engineering a personal application called KartLog. My son races go-karts, which involves capturing and managing a lot of data (engines, tyres, lap times, kart setup, temp, weather conditions …). I used to store this all in a Google Sheet with various scripts and formulae, but decided it would be fun (and useful) to create a dedicated Progressive Web App. It is a very conventional tech-stack, JavaScript, Firestore, SvelteKit and the SMUI (material) library.
Rather than implement a new feature I decided to ‘surgically remove’ an existing feature. The app currently allows you to manage the tracks you’ve visited:
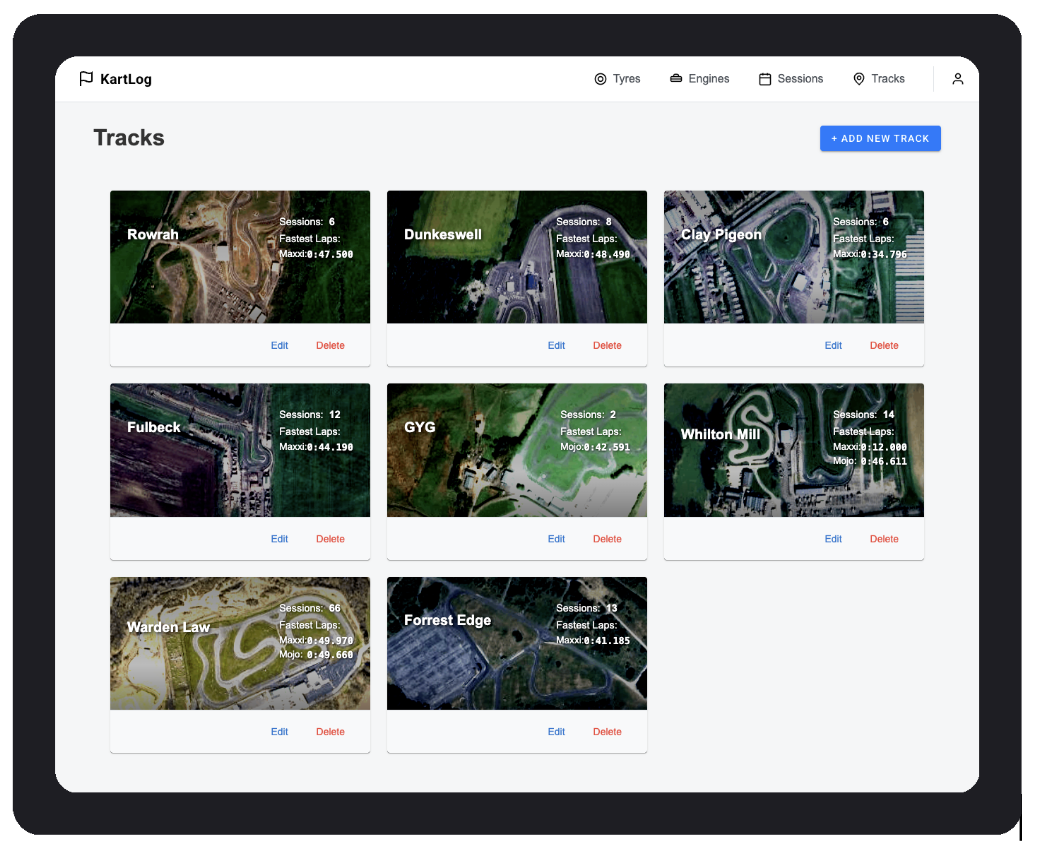
I removed this feature, reverting it to a simple string when recording sessions. This resulted in ~1000 lines of code being deleted.
My goal was to re-create this functionality using Spec Kit, evaluating whether this approach is superior to the current vibe engineering techniques I use (covered later). This felt like a good test case; a reasonably sizeable product increment of modest complexity (CRUD functionality, integration with existing data model, GPS integration), but also one where I could confidently write an unambiguous specification – because I’d already built it.
Getting started
Spec Kit is quick and easy to install, being provided as a simple command line tool. The specify init command creates the project-specific configuration. I’m using GitHub Copilot (with Claude Sonnet 4.5), which results in Spec Kit adding a number of custom agents, which can be run via slash commands in the Copilot chat window, e.g. /speckit.specify. Looking in the .github/agents folder reveals that these custom agents are basically prompts, with a little bit of metadata.
So far, so easy.
During this blog post I’ll link to the git commits for each step, here’s the first one, adding the Spec Kit prompts.
Constitution
The first step is to create your ‘constitution’, which the documentation describes as “a set of immutable principles that govern how specifications become code”.
I ran the constitution agent, waiting for 4mins, watching it analyse the codebase, as per the prompt, and construct a 189-line markdown file. I reviewed the file, and it looked OK (if a little obvious) in its contents. The default constitution favours a TDD approach, however, for my hobbyist app I am happy with manual verification. I asked Copilot to reflect this in the constitution, and after a couple more minute I had something I was comfortable with.
You can see the file it produced in the corresponding commit.
Going forwards, for each step, I’m going to include the overall statistics relating to agent execution time, the time I spent on reviewing artefacts and tokens consumed:
- 4min generation
- 5min review and adjust
- 161 lines of markdown generated
Specify
The next step is where it gets interesting, building the specification for the feature you want to implement. I decided to split my implementation into a couple of steps – here is the prompt I used to create the specification for the first:
/speckit.specify I’d like to extend this application to provide more feature rich functionality for managing circuits. At the moment the circuit is just a string associated with each session. I’d like to turn this into an entity (with circuit name, latitude, longitude, notes), that has a CRUD style interface (similar to engines) that allows the user to update and manage circuits
The above created a 189-line specification, which you can see in this commit. The specification comprises 5 user stories, which are a decent break down of this ‘epic’ as well as 18 functional specs, 6 outcomes, 8 assumptions and more. This looks reasonable, and a few of the assumptions it identified (e.g. the need to migrate session data to conform to this new data model) were quite insightful.
Oh yes, it also added a 41-line self-assessment, checking this specification against the constitution. Good to know!
I did make a few changes to the specification (via the chat), removing some NFRs that felt a little misplaced.
- 6min generation
- 15min review and adjust
- 230 lines of markdown generated
Plan
The next step is to create a plan, “Once a feature specification exists, this command creates a comprehensive implementation plan”.
Executing this step took 8 minutes, and created a lot of markdown:
- 444-line module contract – a human-readable description of the persistence JavaScript module, which includes a lot of code snippets. Ironically this is 4x the length of the actual module itself (once implemented).
- 395-line data model– that has a few interesting migration details, but otherwise a lot of code snippets and excessive detail (in my opinion). Much of this feels like an obvious and valueless transformations of the spec (validation logic, lifecycle, …)
- 285-line plan - reiterates tech stack, outlines folder structure
- **500-line quick start **– details the step by step implementation, plus test plan
- 406-line research document - including justification of decisions (e.g. why it is using the SMUI (Svelte Material UI) library? erm … because every other page uses that!)
It isn’t entirely clear whether you are supposed to review the output of the Plan step, but the contents detailed above feels quite excessive. Take a look for yourself.
- 8m30 generation
- 2 hour review (might not have been needed)
- 2,067 lines of markdown generated
Tasks
At this point I thought it was time to implement, but not yet, there is one more step – task list creation. “After a plan is created, this command analyzes the plan and related design documents to generate an executable task list”
Thankfully this was relatively brief, creating a 66-step implementation plan, mapped to user stories, includes checkpoints, opportunities for parallel execution. Here’s the commit.
- 8m30 generation
- 2 hour review (might not have been needed)
- 2,067 lines of markdown generated
Implementation
The /speckit.implement command took 13m15 to execute, creating 14 files and \~700 lines of code (see this commit), which seems about right. Ahead of reviewing the code, I launched the dev server and … it didn’t work!
There was a small, and very obvious, bug in the code that was easily fixed by pasting the error into the chat agent (vibe coding style!). The error itself was very simple, a variable (circuitsData) used within the ‘new session’ form wasn’t being populated from the datastore.
Given that I am following SDD, I should clarify my specification, then repeat the above steps. But how to express this bug from a specification perspective? It was a trivial and clumsy mistake. I asked Copilot, and it concurred, this isn’t an issue with the spec.
There is a lot of debate on the GitHub Discussions board about how to refine / fix the implementation. It isn’t entirely clear.
- 13m15 generation time
- 689 lines of code
- 30min review
After this, I now had a fully functional application where I can add / remove circuits and associate them with sessions:
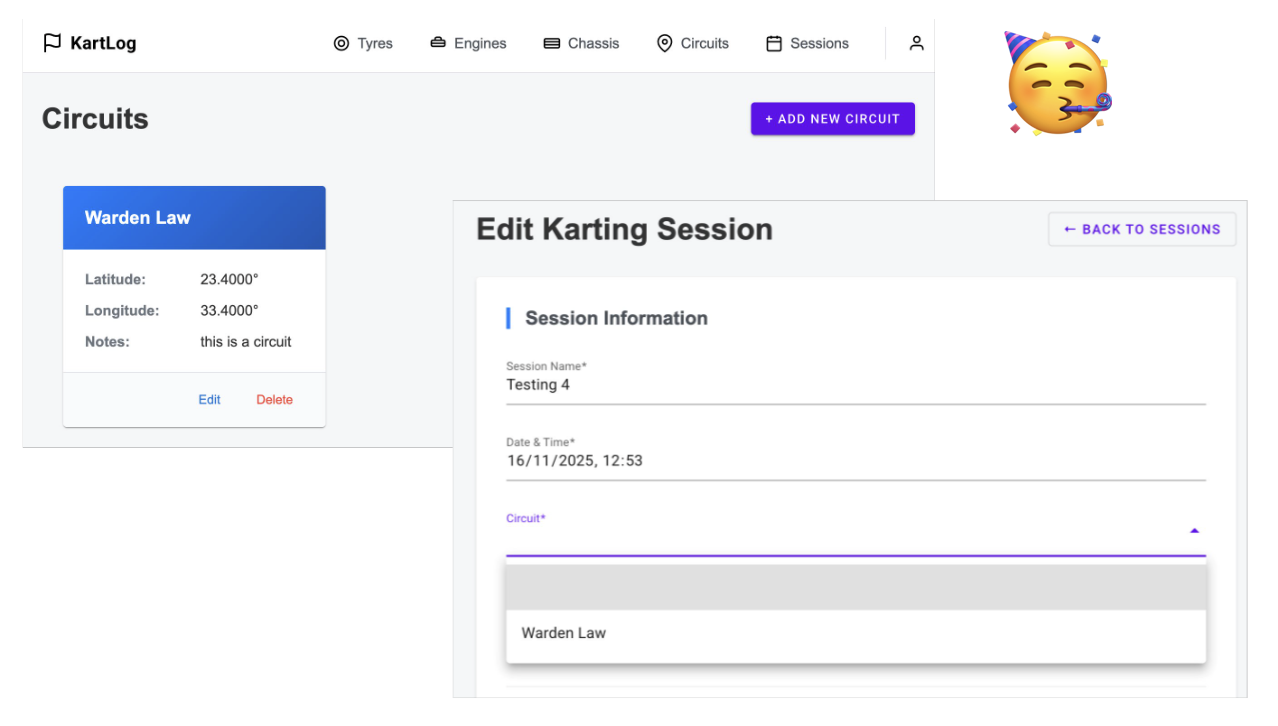
And the grand totals were:
- 33m30 - of agent execution time
- 689 loc
- 2,577 lines of markdown
- 3.5 hrs review time
Next increment
The next step was to add GPS functionality, deriving a spec from the following:
use geolocation APIs to make it easier to manage sessions. When editing sessions, the circuit should default to the closest circuit to the users current location, and when adding circuits, allow the lat / long to be set using the current location.
I’ll not got into the detail of each step again, just provide the totals:
- 23m30 - of agent execution time
- ~300 loc
- 2,262 lines of markdown
- ~2 hrs review
You can see the individual steps in my commit history if you’re interested. Given that this was a small increment, I was surprised to find the implementation step took 11 minutes to execute.
Spec Kit Process Overview
Taking a step-back, the timeline for implementing each feature (via a specification) was roughly as follows:
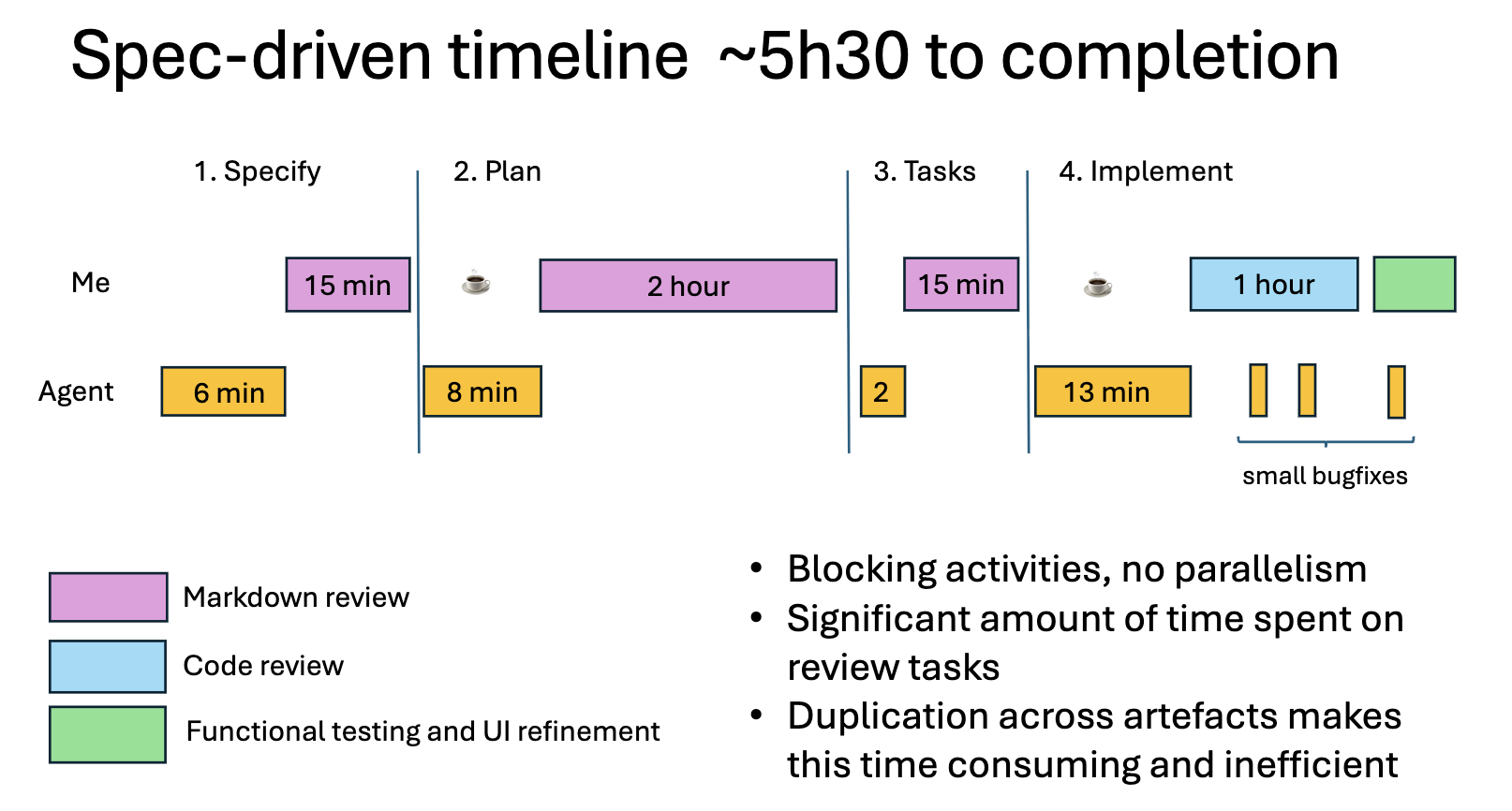
Ultimately a lot of time spent reviewing markdown or waiting for the agent to churn out more markdown. I didn’t see any qualitative benefit to justify the overhead.
Comparing my ‘regular’ approach
So, how does this compare to the approach I typically use, building features using small increments and simple prompts?
Here’s the summary:
- 8m - of agent execution time
- 1,000 loc (and no markdown!)
- 15 min code review
- 9 min functional test and small fixes / tweaks
I reached my end goal much faster, and without any bugs in the implementation.
Viewing the process as a timeline you can see some significant differences between the spec-driven and ‘regular’.
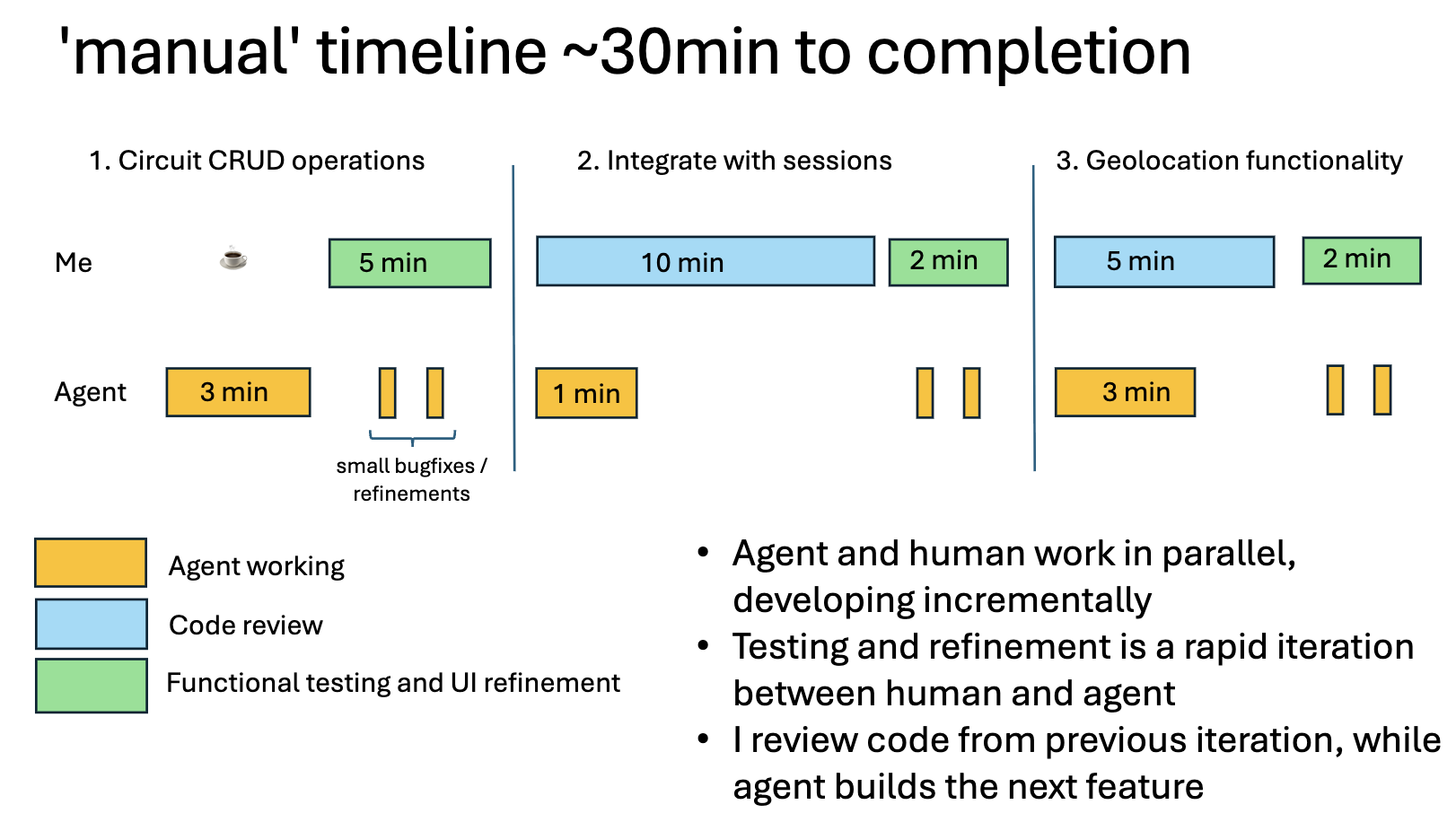
My high-level approach is as follows:
- Prompt Copilot to implement a modest size increment, something I feel I can confidently review in 10 minutes.
- When it has finished, immediately move to a functional verification, providing additional prompts if I see bugs or visual issues.
- Once it passes my functional tests, I prompt Copilot to implement the next feature while I spend time familiarising myself with the code from the previous step. At this point I might determine the need to refactor some of the code, which I’ll bundle into my next functional test / fix cycle.
Compared to working with Spec Kit there is very little down-time at all. I am working while the agent works alongside me.
Also, my review is all ‘high value’, functional testing, code review. I feel like I can keep up with what the agent is producing, even though it is producing it faster than I could.
I like this process, it feels empowering.
A Critique of SDD
The simple fact is I am a lot more productive without SDD, around ten times faster. But speed isn’t everything, putting this point aside for now, I have some more significant concerns about SDD (or at least the way Spec Kit implements this approach).
Code is the law
Spec Kit starts from the premise that ‘Specification is the law’, as opposed to ‘code is law’. They advocate creating detailed and polished specifications from which any sufficiently competent AI can generate a fully functional application. I think this is a flawed goal.
Code is law because it is formal language you can reason about. You can test it. You can prove it is right or wrong. Specifications, or at least ones expressed in the markdown format of Spec Kit, lack this formality. They are not a law I would put my trust in.
Much of the content within the various Spec Kit steps is duplicative, and faux context. For example, it creates ‘fake’ background context (reasoning about the UI design because I might be wearing gloves at the circuit). This is a common problem with the use of AI in general – it creates detail that fundamentally lacks depth of value.
**Rationale**: Karting users need to log data trackside on mobile devices, often with gloves or in suboptimal lighting. Poor mobile UX renders the app unusable in its primary context of use.
Finally, in most development processes specifications are a point-in-time tool for steering implementation. Once complete, and fully tested, how often do you re-visit a user story? Very rarely, they lack much value once the feature is complete.
I’m not against all documentation, on the contrary, capturing architectural details and design decisions is very valuable. Code can give you the ‘what’, but cannot tell you the ‘why’, i.e. why was a specific pattern selected?
A return to waterfall?
As an industry we’ve moved away from waterfall, which favours up-front design and a relatively rigid sequential process, replacing it with something more iterative and agile. My experience of AI is that it makes you even more agile, iterations are faster. Spec Kit drags you right back into the past!
One of the biggest super-powers of AI (for software development) is that code is now ‘cheap’, it is quick and easy to produce. Yes, the quality is variable, but you cannot deny the speed.
As we adapt our software development processes because of this new reality, we should seek to maximise the benefit of this fact. Code is now cheap; we can create it quickly and throw it away just as fast. Spec Kit, and SDD, don’t capitalise on this.
It didn’t result in better code or fewer bugs
This one is quite simple, the code quality created when following Spec Kit was just fine, but the simple and obvious bug threw me a little.
Furthermore, Spec Kit burnt through a lot of agent time creating markdown files that ultimately didn’t result in a better product.
Are agents better at writing markdown or code?
Given that code, of any conventional programming language, is a significant part of the model’s training dataset, and that it is a language they can reason about, surely, they are better at writing code?
I know that is not a terribly compelling argument. But put quite simply, I think that asking an agent to write 1000s of lines of markdown rather than just asking it to write the code is a misuse of this technology.
Is SDD teaching agents to suck eggs?
“Suck eggs” is a phrase used in the idiom “Don’t teach your grandmother to suck eggs,” which means you should not try to advise or instruct someone who is already an expert in a subject.
The whole Spec Kit process is designed to create a guided path for the agent to follow when implementing a feature.
This year we have seen a significant amount of research and product development effort being poured into coding agents. It has become one of the primary battle-grounds for commercialising this technology. In the last week we’ve seen Gemini 3, GPT-5 Codex Max and Claude Opus 4.5 released. Reading the details of the releases, you’ll find that they are all rapidly developing approaches that help their agents better analyse, plan and implement features. These may not be surfaced directly to the user, but they are all part of the internal workings as they battle for supremacy on the SWE-Bench, MITR and various other benchmarks.
Are a bunch of smart and detailed prompts created in an open source project really going to keep up with and exceed the performance of the latest foundation models? It feels like re-reading Harper’s blog post which I referenced earlier. It becomes dated almost immediately.
In defence of SDD
I think it is quite clear that I don’t think SDD works for my workflow, on this specific application. And I am willing to generalise, I don’t think I’d reach for SDD regardless of the context. However, while I feel like I’ve given it a good shot, it would be churlish of me to dismiss it entirely.
I do want to provide a few caveats and potential words of defence.
From reading the Spec Kit forums, there are quite a few active discussions around how you evolve specs, incorporate bug fixes, and other elements of the process. It is clear that Spec Kit is immature and answers to these questions may emerge over time.
Furthermore, I am willing to entertain the possibility that I am simply just using it wrong! In Brigitta’s post (referenced earlier), she stated that “I wasn’t quite sure what size of problem to use it for”, neither am I.
I also wonder whether I am the target audience for this tool? In this specific context (developing my hobby app), I am a vibe engineer. While I am using AI to write most of the code, I am the architect, and lead engineer. I review, I correct mistakes, refactor and generally guide it towards a pattern I am happy with. Perhaps Spec Kit is for the vibe coders? For the product owners? For the people who don’t write or fully understand code?
Parting thoughts
While the overall tone of this blog post is quite negative and heavily criticises SDD, or at least the Spec Kit flavour of it, I do still think there is genuine value in SDD.
I view it in much the same way as Test Driven Development, Vibe Coding and Extreme Programming. There is a long history of more radical approaches to software development. I’m a pragmatist. I wouldn’t advocate implementing these approaches in their purest form, however, there is much to be learnt by giving them a go, by talking about them, pondering, considering and critiquing.
I see Specification Driven Development as an interesting concept, a radical idea, a subject of lively, interesting and healthy debate. But I don’t consider it a viable process, at least not in its purest form, as exemplified by Spec Kit.
For now, the fastest path is still iterative prompting and review, not industrialised specification pipelines.

