
In most microservice architectures, there are many opportunities and temptations for sharing code. In this post I will give advice based on my experience on when it should be avoided and when code reuse is acceptable. The points will be illustrated with the help of an example Spring Boot project available on Github.
Introduction
Before talking about sharing code and what it implies, let’s first look at what microservice architectures are trying to achieve. The main benefits for implementing microservices are:
- Better scaling - different parts of the system can be scaled independently
- High decoupling between different parts of the system - this is always desired, but easier to achieve with microservices
- Improved resilience - services can fail independently
- Freedom to choose technologies - each service could be build using the most appropriate technology
- Improved reusability of components - services (even deployed) can be shared across projects
- Many more depending on the specific architecture, or the problem being solved
Clearly, many of these benefits can produce a better system as well as make developers jobs easier and more rewarding. These could be discussed and debated further, but this is not the point of this article, so lets just assume that we agree here (and experience from the likes of Netflix and Nginx seems to strongly support these benefits). As with any architecture choice, there are also disadvantages and difficulties that have to be considered. The more important ones include:
- Increased complexity of deployment - rather than one or a few deployments, you may have to deal with tens or more
- More integration code - often the services will have to talk to each other; getting this right is very important and deserves its own blog post
- Dealing with the business domain distributed across the system will require a lot of copied code - or maybe it won’t?
The Problem
Here we reach the point where we face one of the most common question that many teams starting their work on microservices face. Based on the goals of microservices and common development best practices we arrive at the problem: “We want to have highly decoupled services, that don’t share code and dependencies. This means that every time we consume some service, we have to write the classes that deal with the response. Is DRY (Don’t repeat yourself) not important any more? What should we do?”. It is actually a good thing if the team realises the issues and starts looking for solution. There are two anti-patterns that can come up here easily:
- Let’s make services depend on one another! Well, this means that high decoupling is just a thing of the past (we clearly fail here) and that freedom of chasing technology goes as well- it is easy for logic to be all over the place and for the domain to grow more complicated than it should.
- Let’s just copy paste all the code! This is actually not as bad, as it at least preserves decoupling and naturally stops the domain from having too much logic. Client’s can’t depend on the code of the service. Let’s be honest here though- no one wants to copy paste the same classes all over the place and do a lot of boilerplate every time you want to consume that pesky user-profile service. DRY is such a popular development mantra for a reason!
The Solution
By stating clearly the goals of the architecture and explaining the problem well, the solution seems to suggests itself. If the service code should be completely separate, but we need to consume possibly complicated responses in the clients- clients should write their own libraries for consuming the service.
By using client-libraries for consuming the service the following benefits are achieved:
- Service is fully decoupled from the clients and no services depend on one another- the library is separate and client specific. It can be even technology specific if we have mix of technologies
- Releasing new version of the service is not coupled with clients- they may not even need to know if the backward compatibility is still there, it is the clients who maintain the library
- The clients are now DRY - no needless code is copy pasted
- It is quicker to integrate with the service - this is achieved without losing any of the microservices benefits
This solution is not something entirely new- it was successfully implemented in Scott Logic projects, is recommended in the “Building Microservices” by Sam Newman (highly recommended) and similar ideas can be seen in many successful microservices architectures. Here, we are mainly talking about the code reuse for dealing with a business domain, but similar approach works for code that is used for general connectivity and communication, as long as it does not violate explained here principles (this is what Netflix internal client libraries are more focused on).
Another question that can be asked is- should we worry about coupling domain objects and connectivity within client libraries. As with the answer to the main question, the most important consideration is the impact on the overall architecture. If we decide that it benefits our productivity to include the connectivity code in client libraries, it needs to be ensured that this does not introduce coupling between the client services. Given that the connectivity in these architecture usually happens via simple REST call, or a message queue, I would discourage including this kind of code in the client library, as it does not add enough benefits for the extra dependency it introduces. If the connectivity code has something very special and complicated about it- for example client certificates needed for making SOAP requests, then a case for additional library may be there. If you decide to go that route, always make it optional to use the client library, rather than mandatory. Client services should have full ownership of that code (there should be no expectation for the service provider to always update relevant client libraries).
Spring Boot Example
After explaining the solution, the best way to clearly demonstrate the point for the developers is with code. This is also a good excuse to further promote my current favourite microservice library - Spring Boot. The whole example can be downloaded from a Github repository created for this blog post.

Spring Boot lets you start developing microservices rapidly, and I really mean it. If you think that the Dropwizard introduction was fast, then be prepared for even more convenience with Spring Boot. In this example we will develop very simple User service that will be returning mocked User JSON object. This service will be further used by a notification service and a dashboard service, effectively providing different views on the data and both needing to understand the User object.
User Service
The UserServiceApplication will contain the main method. Since this is Spring Boot, running it will start an embedded
Tomcat server:
package com.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class UserServiceApplication {
public static void main(String[] args) {
SpringApplication.run(UserServiceApplication.class, args);
}
}This really could not have been simpler! Spring Boot is a very opinionated framework, so if we are happy with the defaults, there
is really not much typing at all. One thing that will need changing is the default port though. Let’s see how this is done
with the application.properties file:
server.port = 9001Simple and elegant. If you ever wrote a REST service in Java you probably know that you need a Controller. If this is
your first time doing this- don’t worry, Spring Boot makes writing controllers really simple:
package com.example;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class UserController {
@RequestMapping("/user")
public User getUser(@RequestParam(value="id", defaultValue="1") int id) {
return new User(id);
}
}This will simply enable users to make requests to the endpoint /user?id= where id can be set for the user that is required.
Seeing how simple these Classes are, surely the logic needs to be in the actual User class. This class will generate the
stub data and will be serialised by Jackson (Java JSON library):
package com.example;
import java.util.ArrayList;
import java.util.List;
public class User {
private final long id;
private final String forename;
private final String surname;
private final String organisation;
private final List<String> notifications;
private final long points;
//Friends are deprecated and should not be used
private final List<String> friends;
public User(int id) {
String[] forenames = {"Alice", "Manjula", "Bartosz", "Mack"};
String[] surnames = {"Smith", "Salvatore", "Jedrzejewski", "Scott"};
String[] organisations = {"ScottLogic", "UNICEF"};
forename = forenames[id%3];
surname = surnames[id%4];
organisation = organisations[id%2];
notifications= new ArrayList<>();
notifications.add("You have been promoted!");
notifications.add("Sorry, disregard the previous notifaction- wrong user");
points = id * 31 % 1000;
//You have no friends
friends = new ArrayList<>();
this.id = id;
}
//Getters and setters for everything...
}This is the whole service required for producing the User JSON. Since this is the first Spring Boot service presented,
it is worth to have a look at the .pom file:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>user-service</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>user-service</name>
<description>Demo user-service with Spring Boot</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.3.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.5.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>Calling the service with an id value 10 we can see the example JSON output:
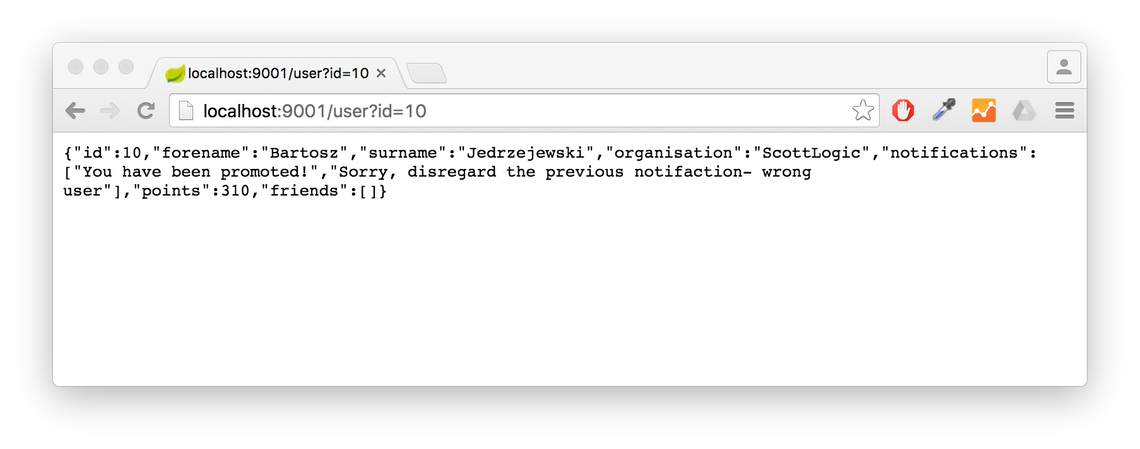
Client Library
Let’s say that we want to have two services making use of this API. Notification and Dashboard service. In the real
world example, the User object could have been much more complicated and we could have more than two clients. The
client library is a simple project called user-client-libs and it consists of a single class:
@JsonIgnoreProperties(ignoreUnknown = true)
public class UserView {
private long id;
private String forename;
private String surname;
private String organisation;
private List<String> notifications;
private long points;
public UserView(){
}
public long getId() {
return id;
}
public String getForename() {
return forename;
}
public String getSurname() {
return surname;
}
public String getOrganisation() {
return organisation;
}
public List<String> getNotifications() {
return notifications;
}
public long getPoints() {
return points;
}
}As you can see, this class is simpler- it does not have the details for mocking Users, nor does it include the
friends list that is deprecated in the original class. We are hiding this details from the clients. This lightweight implementation will also ignore any
new fields that may be returned by the API. Of course in a real life example, the client library could be much more
complicated, saving significant time lost in boilerplate and understanding of the relationships between the fields.
Clients
This example will provide implementation of two separate client services. One for producing the “user dashboard”” and one for producing a “list of notifications”. You can think of them as a purpose build micro services for dealing with UI components.
This is the controller for the dashboard service:
import com.example.user.dto.UserView;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
public class UserDashboardController {
@RequestMapping("/dashboard")
public String getUser(@RequestParam(value="id", defaultValue="1") int id) {
RestTemplate restTemplate = new RestTemplate();
UserView user = restTemplate.getForObject("http://localhost:9001/user?id="+id, UserView.class);
return "USER DASHBOARD <br>" +
"Welcome " + user.getForename() +" "+user.getSurname()+"<br>"+
"You have " +user.getPoints() + " points! Good job!<br>"+
"<br>"+
"<br>"+user.getOrganisation();
}
}And this this is the controller for the notification service:
import com.example.user.dto.UserView;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
public class UserNotificationController {
@RequestMapping("/notification")
public String getUser(@RequestParam(value="id", defaultValue="1") int id) {
RestTemplate restTemplate = new RestTemplate();
UserView user = restTemplate.getForObject("http://localhost:9001/user?id="+id, UserView.class);
String response = "NOTIFICATIONS";
int number = 1;
for(String notification : user.getNotifications()){
response += "<BR> Notification number "+(number++)+": "+notification;
}
return response;
}
}As you can see both clients are very simple and the connection between them and the service is trivial. This
of course requires adding the dependency in the .pom files for both services
<dependency>
<groupId>com.example</groupId>
<artifactId>user-client-libs</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>The only thing left in this example is to start all three services on the ports 9001, 9002 and 9003 and
look at the outputs:
Dashboard output:
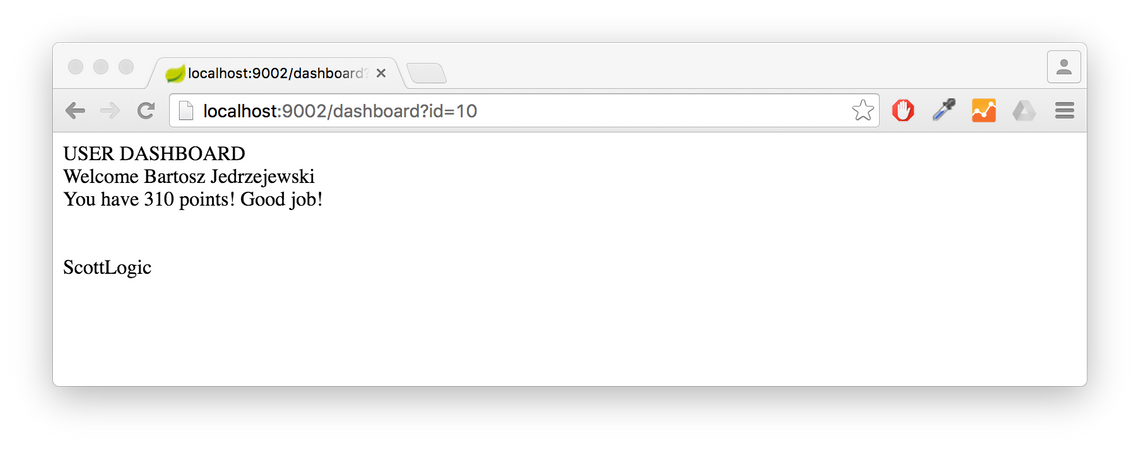
Notifications output:

Conclusion
I believe that this design solves most common problems with reusing code in microservices architecture. It is simple to understand, avoids many drawbacks of other approaches and makes developers life easier. What is more- this is a solution that was tried in a real life projects and it proved itself.
Spring Boot example really showcases the simplicity of this approach and hopefully shows that microservices are actually easier than many developers think. If you want to explore further, check out my example project from Github and see if you can take it further!
Good luck with your microservices development!
