
This blog post describes the process of creating a GitHub bot, hosted as an Amazon Web Services (AWS) Lambda function, that performs various checks on pull requests. This post looks at the AWS configuration and Lambda function developer cycle, usage of the GitHub APIs, and how to store user ‘secrets’ such as GitHub access tokens.
Contributor License Agreement
If you don’t care why I created this bot, and just want to see the code, feel free to skip this section!
I recently joined the Symphony Software Foundation, an organisation that fosters the use of open source within financial services, and a few weeks ago we moved a project into the foundation as an ‘incubator project’. The Foundation provides project governance that includes selecting appropriate licenses, copyright notices and a Contributor License Agreement (CLA).
If you’ve not encountered a CLA before they are actually quite straightforward; a CLA is a legal document in which you state you are entitled to contribute the code you are committing and are willing to have it used in distributions and derivative works. Small-scale open source projects rarely bother with CLAs, but any large organisation (which has a legal team to worry about these matters!), will require all contributors sign one. For example, Facebook, GitHub and Microsoft all have online CLAs that must be signed before they’ll accept your contribution.
As a project maintainer, a CLA gives you legal peace-of-mind, but adds process overhead. For this reason Facebook, Microsoft and GitHub all have CLAs which are electronically signed and a GitHub ‘bot’ that checks pull requests (PRs) on your behalf.
Unfortunately Symphony Foundation doesn’t have a bot - so I decided to write one!
I did have a quick look to see if there was anything out there that might already fit the bill. I found clabot, which you have to host yourself, cla-assistant and CLAHub which were implemented as services, but managed the full CLA signing process. As there is a lot of variability in how CLAs are represented and signed, none were a good fit.
The actual process of creating a CLA document and collecting a signature isn’t hard (you only perform this once per contributor), it’s the overall integration into the development workflow via GitHub that is the hard part. This is the part I wanted to automate, and host as a service, leaving the specifics of the CLA signing process configurable and pluggable.
Creating an AWS Lambda
The logic that this bot runs is pretty simple, ideally no more than a couple of hundred lines of code. This feels like a good fit for AWS Lambda, where you create services as simple node functions, using a server-less architecture (they are of course hosted on a server, but with the server-less pattern the server, or servers, is not your concern).
Setting up a Lambda and exposing it via HTTP is a relatively complex task. For a detailed set of instructions, refer to the ‘Build an API to Expose a Lambda Function’ tutorial.
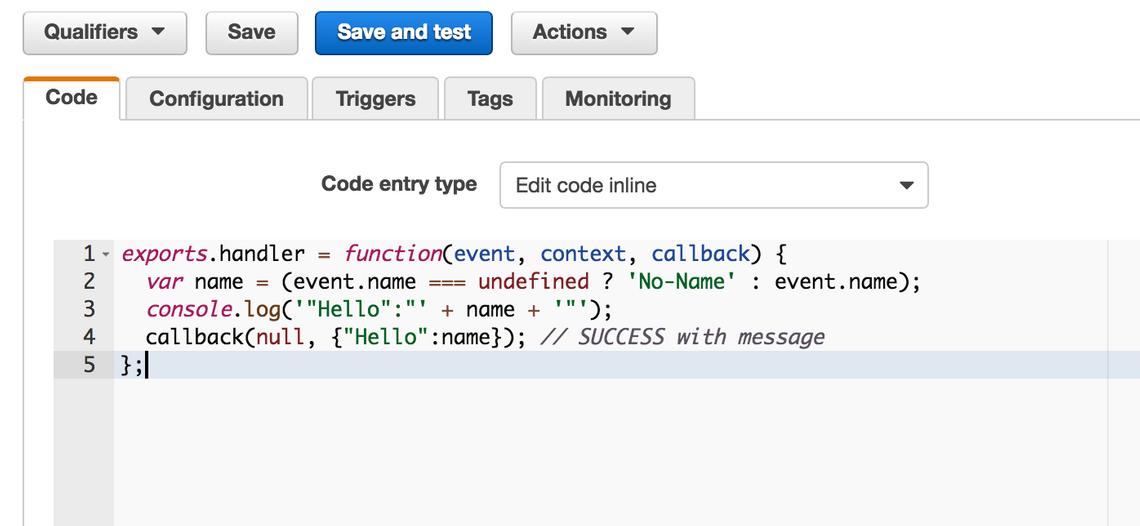
The tutorial leads you through the process of creating a very simple Lambda that echoes back the user’s name:
exports.handler = function(event, context, callback) {
var name = (event.name === undefined ? 'No-Name' : event.name);
console.log('"Hello":"' + name + '"');
callback(null, {"Hello":name}); // SUCCESS with message
};
This Lambda is exposed as an HTTP Endpoint via the API Gateway, with an IAM role configured that allow Lambda execution and logging to CloudWatch.
The least obvious part of the whole set-up is the way the HTTP API is connected up to the Lambda. You can point the endpoint at the function, however, extra configuration is required to map the various request information (header, body, querystring, post parameters) to the event which forms the Lambda input. This configuration uses the Velocity Template Language.
I have no desire to learn this template language, so instead I just copied a generic mapping I found on someone’s blog post:
{
"body" : $input.json('$'),
"headers": {
#foreach($header in $input.params().header.keySet())
"$header": "$util.escapeJavaScript($input.params().header.get($header))" #if($foreach.hasNext),#end
#end
},
"method": "$context.httpMethod",
"params": {
#foreach($param in $input.params().path.keySet())
"$param": "$util.escapeJavaScript($input.params().path.get($param))" #if($foreach.hasNext),#end
#end
},
"query": {
#foreach($queryParam in $input.params().querystring.keySet())
"$queryParam": "$util.escapeJavaScript($input.params().querystring.get($queryParam))" #if($foreach.hasNext),#end
#end
}
}
This basically maps everything in the request so that it is available via the Lambda’s event parameter. Job done!
Development via node-lambda
One you’ve created a Lambda, the AWS console allows you to editing via an online interface, a bit like CodePen, but relatively limited in it’s functionality.
This interface is fine for familiarising yourself with the basics of Lambdas, allowing you to provide a JSON input and view the callback response and any logging, but the overall workflow soon becomes cumbersome. Also, the editor only allows you to edit single-file Lambdas, they can actually contain multiple files and dependencies as defined via a package.json file. For these more complex cases, the interface only gives you the option to upload a ZIP file.
There are a few open source projects that automated Lambda deployment, after trying out a few, I finally settled on node-lambda. This simple command line allows you to run your Lambda code locally, package and deploy.
I created a new npm package for my bot, and added this tool as a dependency:
npm install --save-dev node-lambda
In order to run locally, you need to create an event.json file which is used to create the object passed to the event parameter of your Lambda. Deployment is a little more complex, requiring you to create an AWS access key, adding the details, together with your previously created IAM role, to an .env file:
AWS_ENVIRONMENT=dev
AWS_ACCESS_KEY_ID=--your-aws-access-key--
AWS_SECRET_ACCESS_KEY=--your-aws-secret-access-key--
AWS_ROLE_ARN=--your-aws-role-arn--
AWS_REGION=us-east-2
AWS_FUNCTION_NAME=clabot
AWS_HANDLER=index.handler
AWS_MEMORY_SIZE=128
AWS_TIMEOUT=3
AWS_RUNTIME=nodejs6.10
NOTE: the node-lambda command line tool concatenates the environment and function name; in this case the the Lambda name is clabot-dev
The node-lambda tool also allows you to provide environment variables which are included as part of the deployment process. I used this to supply the GitHub access token for my bot account to the Lambda, so that it doesn’t appear in the code (which is freely available). The deploy.env includes the environment variables:
GITHUB_ACCESS_TOKEN=--my-bot-token--
Finally, I added npm scripts:
{
"scripts": {
"execute": "node-lambda run",
"deploy": "node-lambda deploy --configFile deploy.env"
}
}
This provides a very easy interface for running, or deploying. Here’s a deployment example:
$ npm run deploy
> cla-bot@1.0.0 deploy /Users/colineberhardt/Projects/cla-bot
> node-lambda deploy --configFile deploy.env
=> Moving files to temporary directory
=> Running npm install --production
=> Zipping deployment package
=> Reading zip file to memory
=> Reading event source file to memory
=> Uploading zip file to AWS Lambda us-east-2 with parameters:
{ FunctionName: 'clabot-test',
Code: { ZipFile: <Buffer 50 4b 03 04 14 00 00 00 08 00 a2 31 a9 4a 85 f2 0d 35 62 04 00 00 04 20 00 00 09 00 1c 00 2e 44 53 5f 53 74 6f 72 65 55 54 09 00 03 df 4f 11 59 df 4f ... > },
...
Environment: { Variables: { GITHUB_ACCESS_TOKEN: '---' } },
DeadLetterConfig: { TargetArn: null } }
=> Zip file(s) done uploading. Results follow:
{ FunctionName: 'clabot-test',
FunctionArn: 'arn:aws:lambda:us-east-2:462989979267:function:clabot-test',
...
TracingConfig: { Mode: 'PassThrough' } }
=> All tasks done. Results follow:
[
[
[],
[]
]
]
Ideally the deployment would be fully automated and performed via CI, when PRs are merged into branches, with each branches representing an AWS environment. But I’ll leave that task for another day!
When it comes to testing a Lambda function, there are quite a few different options. You can test:
- Via the AWS console, where you supply the event information in JSON via the online interface. This is the most ‘direct’ way to test it.
- Locally via node-lambda, which is good for rapid development cycles, but may not be an entirely accurate simulation of your real environment.
- Using the API Gateway console you can construct GET / POST HTTP requests that invoke the Lambda.
- You can invoke the URL directly using a tool such as Postmaster.
Lots of options! When I encountered configuration errors I would typically start at (1) and move ‘outwards’.
Creating a Simple bot
For my bot I created a new GitHub account github-cla-bot, and yes, this is an acceptable use of GitHub!
In order to use the GitHub API, you need to create an access token. This allows you to invoke API methods using the identity of the user that is associated with the given token. You can create tokens via settings / developer settings / personal access tokens.
In order for the bot to add labels to PRs it needs to have write access to the repository. So I added it as an external collaborator on my repository. This isn’t a great long-term solution, but was a simple way to get the bot started.
GitHub has a Webhooks API where you can supply URLs that are invoked when certain events occur (e.g. comments, PRs, labels being added), these are added under the settings for your project. I added the API Gateway URL as a webhook so that it receives these webhooks.
The first thing I did was create a simple Lambda function that adds a label to all pull requests:
const request = require('request');
exports.handler = ({ body }, context, callback) => {
if (body.action !== 'opened') {
callback(null, {'message': `ignored action of type ${body.action}`});
return;
}
const pullRequestUrl = body.pull_request.issue_url;
request({
json: true,
headers: {
'Authorization': 'token ' + process.env.GITHUB_ACCESS_TOKEN,
'User-Agent': 'github-cla-bot'
},
method: 'POST',
url: pullRequestUrl + '/labels',
body: ['bug']
}, (error, response, body) => {
if (error) {
callback(error);
} else if (response && response.statusCode && !response.statusCode.toString().startsWith('2')) {
callback(new Error(`GitHub API request failed with status ${response.statusCode}`));
} else {
callback(null, {'message': `added label 'bug' to ${pullRequestUrl}`});
}
});
};
With the above code deployed, whenever a webhook occurs, the API Gateway directs the HTTP request to the above Lambda, with the webhook payload mapped to the body property of the event. Note the destructuring assignment to extract this property. The Lambda checks the action supplied by the webhook to discard any non-PR events.
The webhook payload contains a lot of properties which provide API URLs that relate to the event, in this case pull_request.issue_url is used, with /labels appended to invoke the endpoint for adding labels. The body of this API request contains the array of labels to add. Notice that the GitHub access token is obtained from the environment variable via process.env.GITHUB_ACCESS_TOKEN.
The above code can be tested locally, simply by providing a suitable event.json file, for example:
{
"body": {
"action": "opened",
"pull_request": {
"issue_url": "https://api.github.com/repos/ColinEberhardt/clabot-test/issues/9"
}
}
}
This test payload only contains the properties that the Lambda currently uses. You can see a complete payload example on the webhook docs page. The above event adds a bug to issue number #9 on my test repo:

By deploying this code, every newly opened PR received this label.
A really useful feature of GitHub’s webhook interface is that it stores the inputs and outputs of recent invocations. Here is an example of the webhook invocation and its payload:

And here is the corresponding output:

The webhook response is a good place to report errors. Also, in the top-right you’ll find a ‘Redeliver’ which does exactly what it says, redelivers the payload to the webhook URL. This is a really useful feature!
Determining Collaborators
In order to turn this into a more useful bot, it needs to determine whether the person who created the PR is known to have signed a CLA, and either label as ‘cla signed’, or add a comment prompting them to sign a CLA. The webhook payload contains the users identity via the pull_request.user.login property.
As the bot now needs to make multiple API requests, with common logic for handling error responses, I created a simple githubRequest function to encapsulate this logic:
const claboToken = process.env.GITHUB_ACCESS_TOKEN;
const githubRequest = (opts, token = clabotToken) => new Promise((resolve, reject) => {
// merge the standard set of HTTP request options
const mergedOptions = Object.assign({}, {
json: true,
headers: {
'Authorization': 'token ' + token,
'User-Agent': 'github-cla-bot'
},
method: 'POST'
}, opts);
// perform the request
console.log('GitHub API Request', opts.url);
request(mergedOptions, (error, response, body) => {
if (error) {
reject(error.toString());
} else if (response && response.statusCode && !response.statusCode.toString().startsWith('2')) {
reject(new Error('GitHub API request failed with status ' + response.statusCode));
} else {
resolve(body);
}
});
});
This function does a few things:
- Adapts the request to return a Promise, which is a much better API for handling chains of asynchronous actions.
- Provides standard error handling logic for generic errors and non 2xx HTTP responses
- Allows requests the GitHub token for the request to be specified (I’ll use this later).
Each repository needs to manage its own list of contributors. I’d rather not store this data within the service itself, the current solution is simple and stateless. I’d have to use something like DynamoDB if I wanted to store this information with AWS. Instead, I decided to take a similar approach to the way that most CI systems work, where a configuration file in the repository is used to supply service-configuration data.
Here’s an example of the .clabot file for a repo which has two contributors who have signed a CLA:
{
"contributors": [
"ColinEberhardt",
"GitHubUser2001"
],
"label": "cla-signed"
}
The Lambda now makes multiple requests, firstly fetching the configuration file (which actually requires two separate requests), then based on whether the PR is from someone in the contributors lists, either labels or comments.
Here’s a portion of the updated code:
const getReadmeUrl = (context) => ({
url: context.webhook.repository.url + '/contents/.clabot',
method: 'GET'
});
const getReadmeContents = (body) => ({
url: body.download_url,
method: 'GET'
});
const addLabel = (context) => ({
url: context.webhook.pull_request.issue_url + '/labels',
body: [context.config.label]
});
const addComment = (context) => ({
url: context.webhook.pull_request.issue_url + '/comments',
body: {
body: context.config.message
}
});
exports.handler = ({ body }, lambdaContext, callback, request) => {
const context = {
webhook: body
};
githubRequest(getReadmeUrl(context))
.then(body => githubRequest(getReadmeContents(body)))
.then(config => {
context.config = Object.assign({}, defaultConfig, config);
if (config.contributors.indexOf(config.webhook.pull_request.user.login) !== -1) {
return githubRequest(addLabel(context))
.then(() => callback(null,
{'message': 'CLA found, added label to PR'}));
} else {
return githubRequest(addComment(context))
.then(() => callback(null,
{'message': 'CLA not found, added comment to PR'}));
}
})
.catch((err) => {
callback(err.toString());
});
};
Assuming the user’s identity
Currently the bot uses its own identity, which results in a few issues:
- The GitHub API imposes usage limits, which for a standard user is 5,000 requests per hour. This is not an issue right now, but for any bot that becomes popular, this could easily be exceeded.
- Currently the bot must be added as a contributor, which provided read / write access to the entire repository. This isn’t ideal; a bot should be granted with only the privileges it requires to perform its core functions.
Many other GitHub related services share the above problems. One common solution employed by CI systems, and other tools such as semantic release is to use the identity of the repository owner to perform their core functions.
In order to do this, you need the user to create an access token with the required privileges. Here’s an example showing a token created via the web interface:
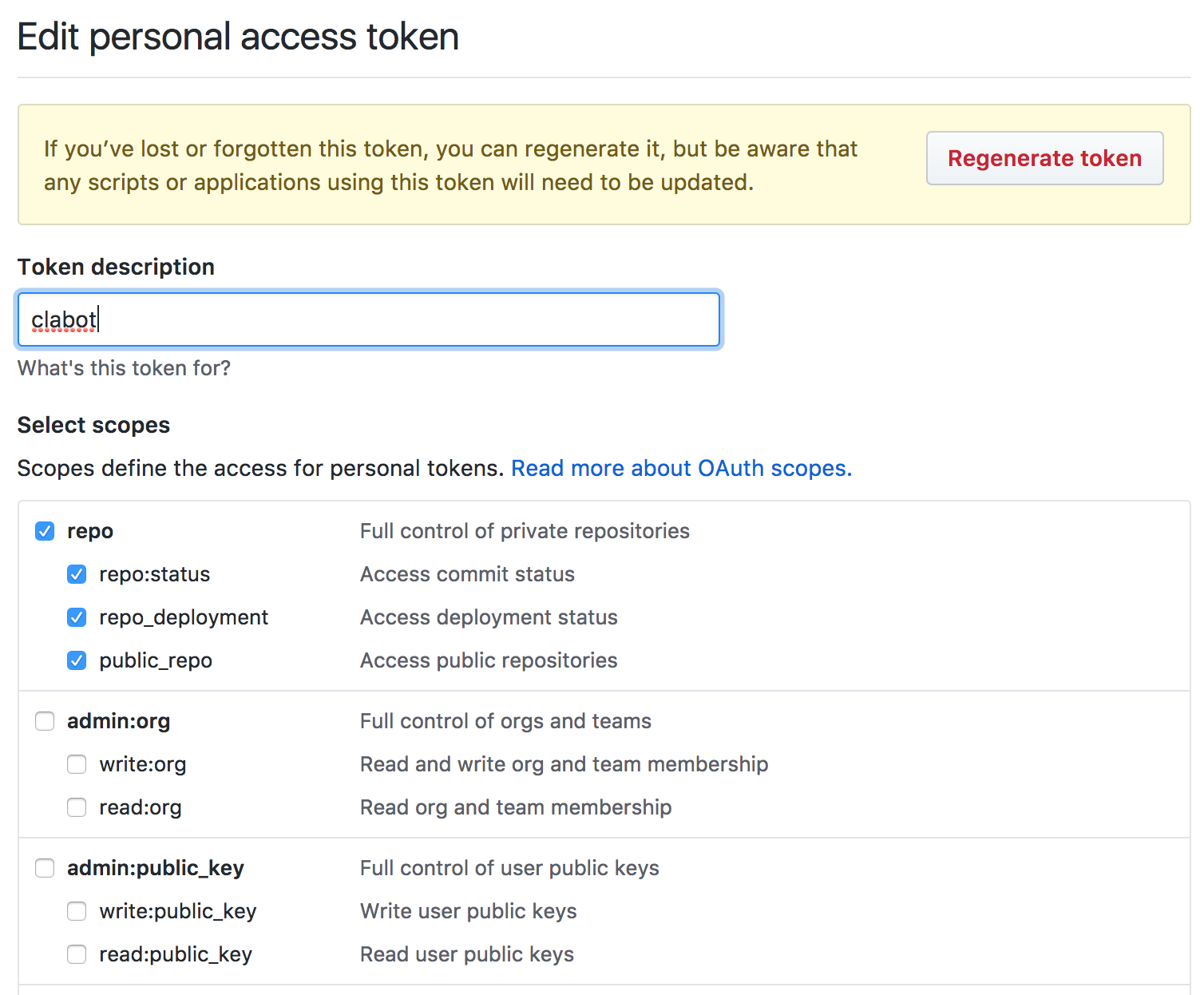
As you can see, you have a lot of control over the ‘scopes’ that limit the API access available to a request bearing this token.
The next problem is where to store this token? Just like the contributor list, I don’t want to make my Lambda any more complex by managing state. The solution I opted for is to store this in the .clabot file.
In order to protect the token, the bot has uses RSA cryptography. The users token is encrypted using a public key, while the bot keeps the private key (as a secret, it’s not checked into GitHub!).
Here you can see the token within the config file:
{
"contributors": [
"github-cla-bot",
"ColinEberhardt"
],
"label": "cla-signed",
"token": "HH6ZdxD9Myb+tr3OblmhhwJh/LFkhB7Y2xYli7pY2o5K4jiEdN9fKHutbtAiDNogg6ACjjAjcDXtrabFc7J+6EjOMoZA1XIiF+NE1g9Hf0JJ68VGwLQVTvziFTVOb5+shc1oRgHDfNjNjkPXlxDZSxT089vdkog8NaClJ/Ufs3U="
}
The ursa package provides a simple interface for reading RSA keys, and using them for signing or encrypt / decrypt:
const ursa = require('ursa');
const privateKey = ursa.createPrivateKey(fs.readFileSync('clabotkey.pem'));
With this key the user token can be decrypted and used for subsequent API requests:
githubRequest(getReadmeUrl(context))
.then(body => githubRequest(getReadmeContents(body)))
.then(config => {
context.userToken = privateKey.decrypt(config.token, 'base64', 'utf8');
// continue with the logic
// using userToken for labelling / status / and the bot for comments
})
This provides many advantages, the bot no longer needs to be added as a collaborator, and only the initial two requests to fetch the .clabot file ‘eat into’ the bot’s usage limits.
Conclusions and Future Work
There is still quite a bit of set-up involved in integrating this bot with a repo, creating access tokens, encrypting them, adding a .clabot file, setting up webhooks. One approach I’ve seen for simplifying this process is to create a CLI tool that acts as a setup ‘wizard’. The semantic release CLI tool is a good example. Another option, which provides an even simpler setup experience is to create a GitHub integration - that’s something I’ll explore next.
The bot itself still needs more features to be really useful. Rather than checking the user that opened a pull request, it should check the users for all the commits in a PR. This will require further API requests. Also, I’d like to make the confirmation of contributors ‘pluggable’, perhaps being read from a file over HTTP (e.g. a gist), or invoking an endpoint, e.g. https://api.foo.com/check-cla/?user=bob.
This is the first time I’ve used AWS Lambda, and while the initial set-up is complex, the workflow I’ve found with node-lambda is really simple and straightforward. I think the server-less approach is ideal for simple integration tasks such like this,
The code for this (work in progress) bot is on GitHub, you can also see this bot interacting with PRs via a test project, feel free to create a PR and see what happens! I’d be happy to receive contributions. For now, no CLA is required to contribute ;-)
Regards, Colin E.