
The Problem
There are a huge number of “Big Data” products, nowadays, trying to fill different niches in the data engineering world. Some offer unique benefits; some try to be more generalist. Some directly compete against each other; others meet slightly different needs. How can you tell, as a developer or a systems architect, which one is going to be the best to meet a given set of requirements, until it is too late to go back on your decision? How can you test a Big Data product under a Big Data load, and how can you fairly test two competing products to see which fits your needs best? It’s a big problem for many of us…but it could potentially be a useful one to explore.
So, a team from the Bristol office were tasked with building a Data Engineering Comparator to compare different technologies, allowing the experiments to be configurable. Once finished, the tool should allow a user to compare technologies with different configuration options or against different technologies.
We began with Amazon Kinesis and Apache Kafka, streaming technologies, as a proof of concept. To compare them, we needed to send a high volume of messages through their systems to see how well they coped. We wanted to allow an experiment to vary a wide range of configuration options to see any effect on performance. Some of these options would require a drastic change of infrastructure. We wanted many experiments to run one after another, to get results as quickly as possible, whenever the user wanted, rather than when the developers could get around to running an experiment. We didn’t want to have to manually change our infrastructure every time we wanted to run a test, which, although fine occasionally, would be boring, time-consuming, more error prone on this scale and restricted in terms of developer availability.
This was an interesting problem requiring use of an Infrastructure as Code (IaC) technology. These are technologies that let code specify the infrastructure needed and create or destroy it for you. This way, changes to infrastructure are reproducible and quick to make.
The Options
Running a standalone product like Apache Kafka might be possible on our own hardware, but this would prevent us from testing SaaS hosted products. Also, we would have the responsibility for setting up all the hardware and looking after it, when there are more exciting things we (believe it or not) could be doing instead. There must be a better way…
We could host the experiments on a cloud provider like Amazon Web Services, or Microsoft Azure; but setting up all the necessary cloud infrastructure would still be a tedious and error-prone job if we had to do it manually. There must be a better, more automatic way…
Cloud providers do have their own deployment automation technologies, such as AWS CloudFormation or Azure Resource Manager, but we didn’t want to limit our experiments to one particular vendor’s cloud. There must be a better, more agnostic way…
The best option seemed to be an Infrastructure as Code product, such as Hashicorp Terraform. This product is a command line tool which lets you specify the infrastructure needed in code and will create or destroy it for you as needed, ensuring that changes to infrastructure are reproducible and quick to make. Although for the purposes of our trial project we limited ourselves to deployment to AWS, Terraform is not constrained to AWS but supports a variety of cloud providers; and it is not itself the only IaC product available. With Terraform, we would be able to specify a standard configuration for each experiment, create it all with a single CLI command, and destroy it all just as easily when the experiment was complete. For an introduction to what Terraform can do, see Chris’ post. This is much better, but still requires a human (or a developer) to change the configuration files for different infrastructure specifications, and to run the commands to do the work. There must be a better, more abstract way…
The Solution
Could we bring a greater degree of automation to Terraform? Could we drive it externally and automate its commands, so that our tool could set up the infrastructure for each experiment, configured precisely to the test’s requirements, and then deploy and run all the necessary software? Could we reach the point where the end user would not need to interact with the AWS console at all?
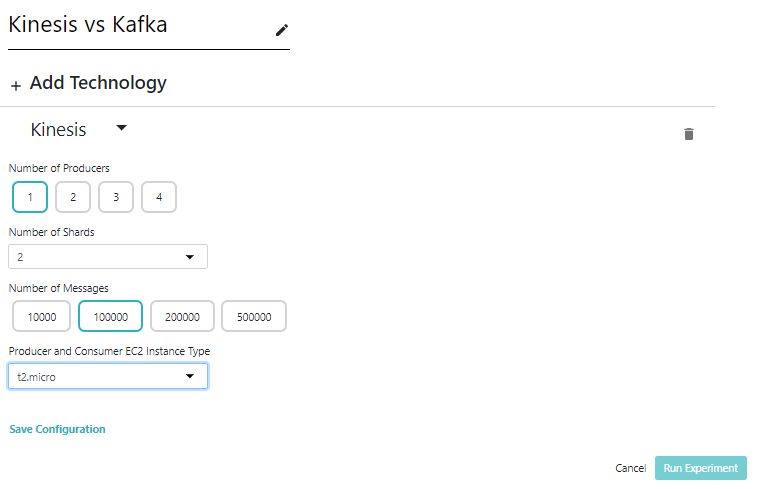
We deployed a Node.js server to AWS, to act as a back-end server. A single POST request to this server, with experiment-specific configuration options, could trigger the creation of the infrastructure, running of the experiment, and destruction of the infrastructure afterwards, all with minimal user interaction. We extended the API so that a caller could get the results of past experiments or the states of those in progress, and wrote a React front-end for the end users. Those end users don’t need to know their way around a command line; they don’t need to know anything at all about Terraform. As far as the users are concerned, the service might as well be doing the processing itself.
The Node.js server was deployed using a Docker container with Terraform installed. Terraform’s configuration file format allows you to reference variables which can be set on the command line; the server took the configuration options given in the body of the experiment requests and used them to supply variable values to Terraform to configure the infrastructure deployment for the experiment. This deployment included a Spring Java microservice to stream data into the messaging technology, and a second microservice whose job was to read data from the messaging technology and compute the experiment results. Once the experiment was completed, the aggregate results were saved to an AWS S3 bucket in order to be served up by the Node.js server, and the server then triggered the terraform destroy command to remove all of the experiment’s infrastructure.
The server itself was also deployed using Terraform, as part of our continuous deployment configuration. Every time new code was pushed to our “dev” branch, an AWS CodeBuild script would shut down the back-end server and then use Terraform to recreate it using a new Docker image. This led to a further problem: what if the server shuts down when an experiment is partway through? We wanted to avoid any risk that manual intervention would be needed if experiments ended up in an inconsistent state, so to deal with this we added a “shutdown” endpoint to the back-end API that the CodeBuild script can query. If the server is midway through processing an experiment, it returns an error code to indicate to the CodeBuild script that shutdown has been deferred until the experiment has been completed, and the CodeBuild script then waits, polling the shutdown endpoint at intervals, until the experiment has ended. This solution is exactly what we wanted; developer input is only necessary if there is an unexpected problem with the infrastructure.
Challenges
Terraform is a very good tool, but the more experiments our system was able to run, the more problems we encountered. Sometimes experiments failed for reasons we couldn’t control, but destroying the infrastructure usually fixed the problem. However, when the destroy phase failed, for whatever reason, it could cause problems that could only be solved by manual intervention with both Terraform and AWS. Our experiments required complex setup of infrastructure, so this is understandable, but it suggests that IaC tools like Terraform are still immature, and until issues like these are fixed (which will be no small task), developers of systems like the Data Engineering Comparator will have to get their hands dirty with AWS. However, we are confident that as more companies start moving to IaC, it will be much safer to use Terraform in the ways we did.
One feature that we would’ve liked, but would be no small task, would be a way for Terraform to look at the current AWS infrastructure, and update its state file to match. This way, if a terraform apply or a terraform destroy failed for any reason, then it might still be possible to delete orphaned or partially-created resources and to create any resources that were not correctly made.
Conclusions
As developers, the more processes that are automated, the better, and this holds for data engineering as much as anything else. In future, I expect to see more systems that use tools like Terraform, and that they will start to abstract their use away from the user. It is a technical challenge, but I expect it will get easier in the future with an increase in tools to help.
Further Reading
This post has only scratched the surface of possibilities and is not intended to detail techniques in Terraform, AWS or other technologies. For more information, have a look at these resources:
