
Continuous Integration / Continuous Deployment is a way of working in which software changes can be easily and frequently deployed through environments into production via an automated pipeline. Every code commit can be deployed, tested and released in a predictable way allowing for a much quicker release to market for new features.
To achieve continuous deployment, we need to achieve continuous confidence of our software. This means that we need exploratory testing to tell us about the new features and regression tests that can be run repeatedly and consistently, together these provide production level confidence in quality.
We need to think about Continuous Testing.
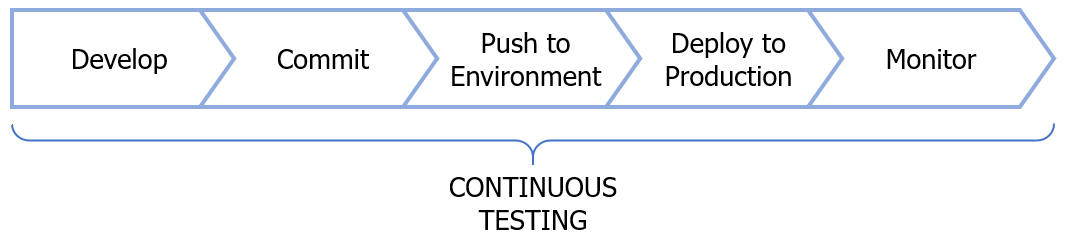
Figure 1: The CI/CD pipeline; showing where Continuous Testing fits.
Continuous Testing includes the ability to run a repeatable set of tests whenever we make a commit to the code repository, so that the CI/CD pipeline can provide fast feedback that this change will not impact the product negatively. A developer should be able to commit their code and for it to be automatically built, tested and released through the CI/CD pipeline or automatically receive quick feedback as to where it needs to be fixed in order to be production ready. As we want to optimise fast turnaround of feedback and rapid fixes of failure, we need to have efficient and reliable automated tests that can be added into the CI/CD pipeline.
Changing how we test
When we design these tests for Continuous Testing, we need to address the following things: Confidence, Implementation, Maintainability, Monitoring and Speed (CIMMS).
Confidence
Tests need to provide confidence that any committed code changes build and operate as we want them to whilst not impacting or regressing any existing behaviour. As a guide, automated tests are usually written so that we have more smaller tests than larger tests:
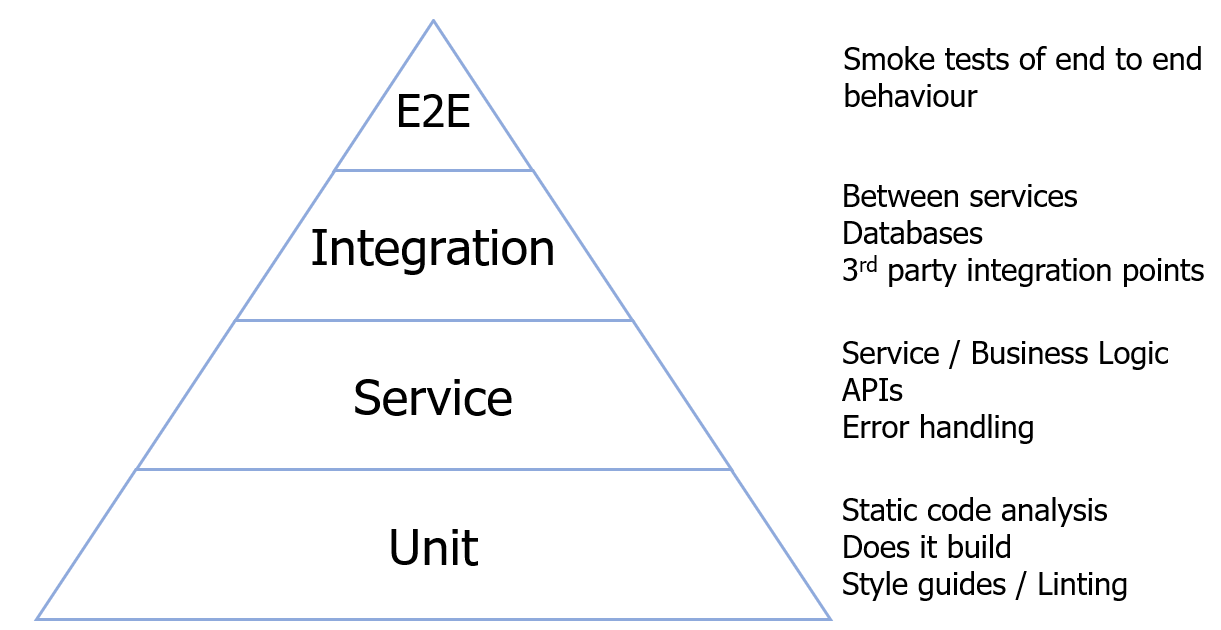
Figure 2: Showing an ideal indication of the types of test we should automate and relative volumes.
As testers, we can champion a transition away from thinking of unit tests that provide code coverage towards including validating business logic and error handling within service level tests. Service level tests should exercise the behaviour (happy path, error case, edge case, etc…) of the service to mitigate risk of failure early on. We can do this by pairing with developers as they write code to review test coverage and introduce additional tests that cover all logic. Taking a holistic approach of the system, thinking of up and downstream system needs and risks will help to identify any additional behaviour that should be exercised within a service.
Part of this transitioning will be to move tests of behaviour away from costly and slow E2E tests and towards these service tests. This means migrating away from running tests of behaviour and logic through Selenium or Cypress and adding them directly into the code for the product; as such the role of a tester becomes more strategic as they help the team to determine what should be tested, rather than writing all of the test scripts.
Implementation
Continuous testing requires the selection and use of tools that will support rapid feedback through the fast running of repeatable tests.
Service level tests can be run by building each service and passing stubbed responses from any integration points in order to exercise the service logic. One way that we can achieve this by spinning up Docker containers for the service under test and injecting specific inputs or responses into them directly (or through the use of stubbed services and integrations to third parties).
Integration tests can be run in a similar way with both services under test run in Docker containers that are set up to run within the same test network. This will allow the tests to exercise the actual integration path between services as opposed to inputs and responses being stubbed.
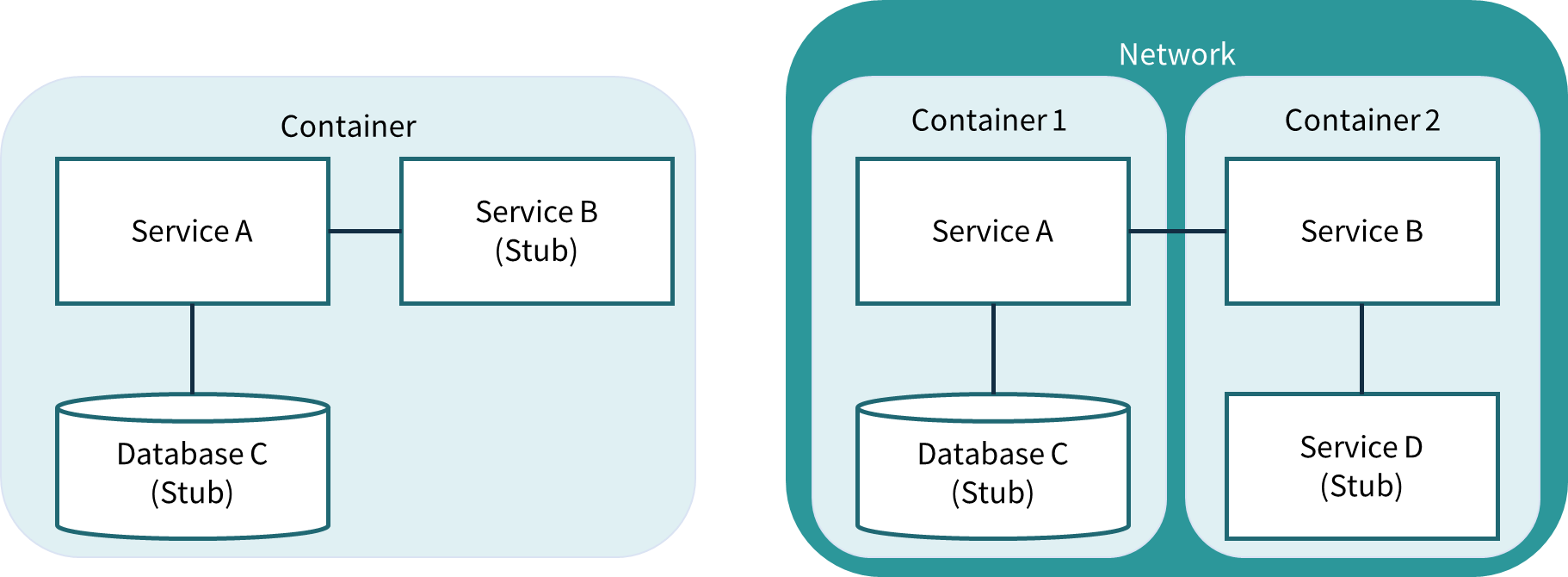
Figure 3: Example Docker usages for service and integration tests; showing the use of service stubs as opposed to running full environments.
For services integrating to a database, using a Docker image of the database in the test with a snapshot of the data allows for predictable test conditions, improving the reliability and robustness of the tests.
Running integration tests in pairwise test network containers means that complex architectures can be broken down and run in small, parallel, environments. This will speed up the running of the test suite and increases robustness due to not having as many services built and operating at once.
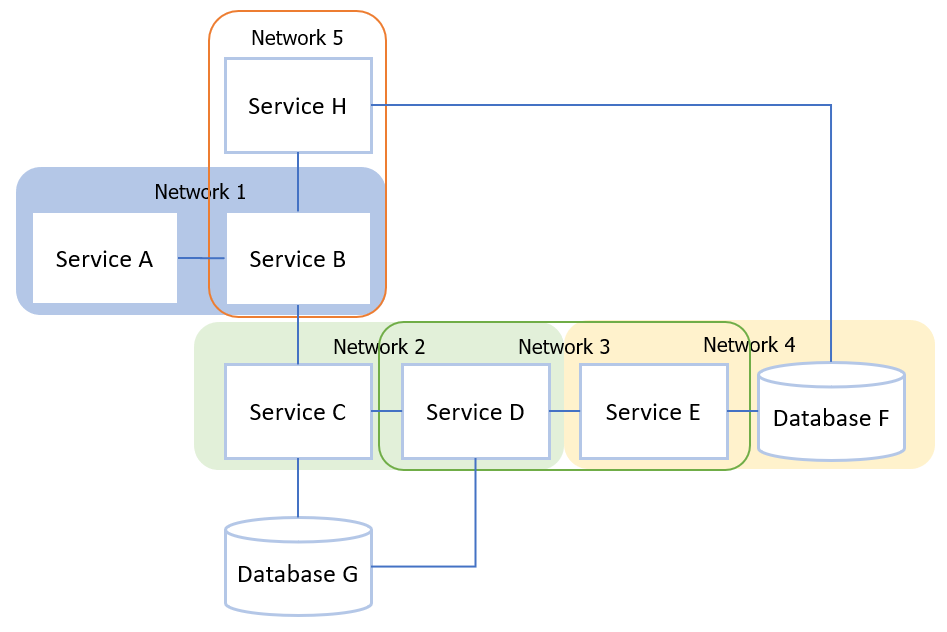
Figure 4: Example of pairwise Docker networks to test integration in parallel rather than having to spin up the whole architecture.
Full environment tests can, where possible, be limited to E2E smoke testing against a staging environment as the bulk of functionality and integration has been validated. These tests can use one of the many existing automation frameworks that can be added to the CI/CD pipeline and feed results back to the team.
Maintainability
Key to having rapid feedback is the ability to trust the tests that have been run. If tests are flaky or frequently require debugging due to environment failures, then they do not provide the confidence needed for Continuous Integration / Deployment. It is therefore important to make sure that tests are maintained and kept up to date, with any failing tests fixed as soon as possible rather than ignored.
As testers we should support the team in creating tests that are easy to maintain and debug as required. This can mean suggesting appropriate human readable logging that will allow any team member to locate where fault is and how to correct it and by ensuring that tests are named and added to the code in a meaningful way with commented descriptions if necessary. Ensuring that Unit and Service tests are added into the same repository as the code will also make it easier to maintain as it will be obvious what needs to be changed as part of a commit.
Testers should also support the team with reviewing existing tests to see if any logic or behaviour needs to be added or change due to product changes. To help with reviews a team should be encouraged to practice minimalism with their test suite; be like Marie Kondo and if a test does not spark joy, or provide useful and unique information, then get rid of it.
Monitoring
The feedback from Continuous Testing needs to be obvious and clear. Most testing tools will allow for integration into your CI/CD pipeline tools, like Bitbucket, Travis CI, CircleCI , GitlLab CI/CD or Jenkins, so that successes or failures are made visible; this even including the ability to display results on a TV screen for the team or sending emails of build failures to interested parties. As testers, we need to ensure that service and integration tests have been written so that each test highlights exactly where a fix is needed if it fails, this means having useful naming and making sure that a test checks for one thing. When a test does fail, we should champion the team into investigating and fixing the issue immediately, as opposed to allowing the team to accept red statuses on the monitoring tool. This can also involve doing the initial debugging or investigation to support the fixes.
Continuous Testing also includes monitoring in production so we should champion for improving testability of this. Adding labelling to logs to make paths of a user through the system obvious, ensuring that useful information is captured in logs in both a machine and human readable way and capturing system details about the user environment can assist with debugging. Thinking about what information should be exposed, captured and displayed in monitoring dashboard tools such as Kibana or Grafana to predict or diagnose when system outages occur is also something that testers can input into.
Speed
Continuous Testing needs to be fast in order to provide rapid feedback, having a test suite that takes hours to run will prevent the team from wanting to make small, less risky, commits. There are several ways in which we can try to speed up how tests are run, many of which have been mentioned above:
-
Reduce the number of tests, don’t try to automate everything and remove tests that provide no useful information.
-
Keep long running E2E and manual tests to a minimum and migrate to service and integration tests.
-
Reduce lengthy build times by spinning smaller integrations of services in Docker containers.
If tests in your Continuous Testing are still taking a long time, split tests to run in parallel. Many CI tools (specifically TravisCI & CircleCI) allow you to split tests across separate environments or machines to run in parallel so ensure that tests are independent and can be run apart from each other.
Alternatively, we can reduce the time needed for running the test suite by only running those related to the areas that have been changed. This can be achieved by setting services or integration points behind a flag to be run only if required, or by using a tool like Travis CI’s test segregation so that repositories with no cross dependences to the change made are ignored.
What about Manual Testing?
Manual testing is still important within a Continuous Testing environment, using exploratory testing techniques is essential to identify information related to new features.
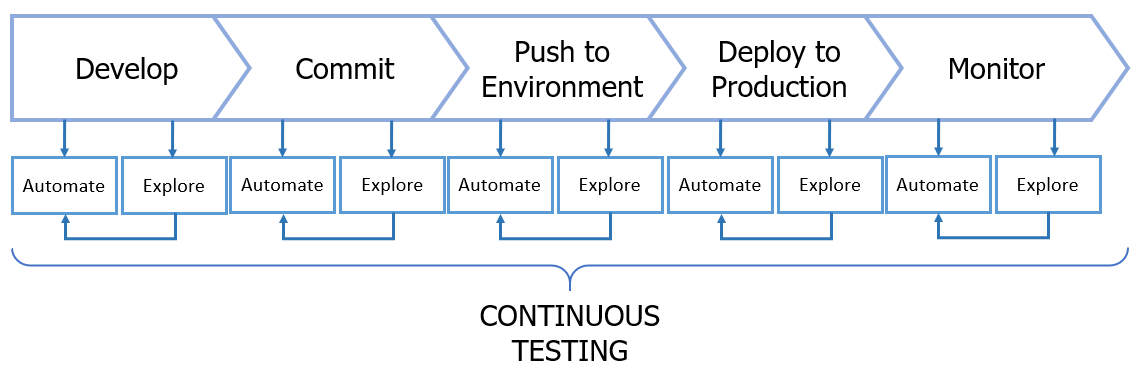
Figure 5: The CI/CD pipeline; showing where exploratory and automation are used.
When new features are developed, we should identify which behaviour is important to add to our automated regression pack from what we learn through exploratory testing. The key thing here is to be selective about what should be tested via automation; we shouldn’t automate everything as this would result in a test suite that is large, slow and unmaintainable.
As testers we should support the team with running exploratory tests to identify what new behaviour does, but also to determine which of those behaviours should be automated as service, integration or end to end level tests.
Develop
We can shift testing early by identifying risks at the ideas and design stage of development, review and input into the code by helping to review coverage of service and integration level tests with developers.
Commit
We can support code reviews, check that tests against the committed branches have been run and chase up on any failures and fixes that are required.
Push to Environment
When the code has been pushed to an environment, we can support testing through the running of exploratory tests to uncover more information about new features or in areas where integrations have been stubbed. If we uncover new behaviour or changes to existing behaviour, we should support the team in identifying which automated tests are needed or need to be changed. To support better CI/CD we should look to test environmental rollback to provide confidence that we can revert changes and not impact users or data integrity.
Deploy to Production
We can support any A / B testing or rolling out of new features by testing the roll out process, running smoke tests in production for vital system behaviour using true data and integrations can also yield important information back to the team.
Monitor
We can run known error conditions to explore how our existing monitoring picks those up and whether enough information is captured to support easy debugging. Along with the team we can review reports to identify when we have confidence for continuing rollout or when we may want to roll back and identify new risks that are seen from user and system behaviours.
Let’s change how we think about testing; let’s support our teams with ways that we can make it continuous.
