
My career as a technology strategist and architect has tended to require looking further out – considering not just the opportunities from technology but also the risks. Nowhere in contemporary technology is that more pertinent than GenAI (Generative AI). So, as we follow the track of generative AI, will we eventually see the light at the end of the tunnel, or will that light be the headlights of an oncoming train?!
This blog doesn’t intend to provide an overview of Generative AI or Large Language Models (LLMs), partly as this has been covered in other posts on this blog and our podcast. Instead, the focus of the proposed architecture is mitigating the risks of deploying these technologies, particularly when used in highly regulated environments such as Financial Services. As I’ll explain, the risks proliferate when these technologies are used in non-trivial solutions, where GenAI isn’t standalone but requires integration with enterprise systems – typically data stores, transactional and analytical systems that provide all important context to an interaction. Naturally, systems that are customer facing present greater challenges as they expose the organisation to greater public scrutiny and reputational damage.
This is a big topic and so even as a primer, this is a fairly long article! I’ll summarise here what I’m going to cover:
-
Business risks of Enterprise GenAI
-
Technology risks and challenges of Enterprise GenAI
-
A proposed GenAI architecture
-
Architecture is exciting again!
To begin with, what are the risks of Generative AI? In short, they are the converse of the characteristics of trustworthy AI systems which are nicely articulated in NIST’s AI Risk Management Framework:
“Characteristics of trustworthy AI systems include: valid and reliable, safe, secure and resilient, accountable and transparent, explainable and interpretable, privacy-enhanced, and fair with harmful bias managed.”
Whilst these are useful, they are focused more on the development of the technology itself and not so much the implications of deploying solutions using these technologies in complex enterprises.
Business risks of Enterprise GenAI deployment
So, with enterprise deployment, what are the key risks at a more organisational level? Some of the below have a strong relationship with each other – for example, bias in a model against certain customers could lead to regulatory compliance failings, leading also to reputational damage. In summary, the phrase “with great power comes great responsibility” very much applies.
Key risks include:
-
Reputational Damage
-
Legal and regulatory compliance
-
in particular “Customer Conduct” aka “Consumer Duty”
-
Intellectual Property Infringement
-
Illegal activity
-
-
Ethics and Privacy
-
Use of Personal / Personally Identifiable Data
-
Bias
-
-
Darker Shadow IT from “Bring your own bot”
Reputational damage
Reputational damage is probably the biggest concern of GenAI – in particular, given its tendency to hallucinate – to come up with credible-looking output that is flawed. However, just as much focus should be given to legal and regulatory risks – particularly if an application is customer facing and generating responses in real time. Imagine it making inappropriate product financial recommendations – it could lead to a misselling scandal.
Legal and IP challenges
Another key concern is intellectual property – datasets used for training could have used commercial intellectual property (without you realising) which the generative AI then uses to create content. In some instances, hallmarks or watermarks from this training data could appear in the generated output, leaving organisations open to litigation.
Without sufficient context (perhaps missing from the prompting of the model), there are various other ways generated content could put your organisation at risk of breaking laws inadvertently or acting unethically. There are also cyber security challenges and these are covered later on.
Ethics and privacy
When it comes to ethics and privacy risks – these are similar to those from other types of Machine Learning. Ethics are magnified by the sheer power of this latest generation of models. Is it OK to displace or massively augment people with these capabilities? Could users start to trust these systems too much? Could they be confused and manipulated? Given they are based on massive amounts of internet data, bias is a significant issue to manage.
The privacy aspect is magnified by the majority of the massive GenAI models being cloud hosted – so, you need to make sure you are OK with sending data to third parties and perhaps use pseudonymisation (where you mask personally identifiable details) or other techniques to address privacy issues.
Darker Shadow IT
Whilst this blog focuses on official and governed projects, the interest and hype around GenAI (plus the perception that internal technology teams can take too long to deliver) means that some employees and teams may be tempted to use publicly available platforms for work directly. The latest evolution of the bring-your-own-device/app trend, but one with more serious adverse impacts. The asymmetry between what the user sees and interacts with at the tip of the iceberg and the potential issues that are hidden below the waterline are huge with this technology (as the length of this summary article shows!)
Technology risks and challenges of Enterprise GenAI
Moving beneath the business considerations, there are challenges in the technology implementation that could create serious issues. These don’t just relate to ML and data science – there are arguably more challenges relating to the deployment and systems integration:
-
Explainability / repeatability / transparency
-
Scalability
-
Security
-
Data and systems integration
-
Costs and the dangers of free trials
-
Environmental impact
-
Financial sustainability
-
Explainability and Repeatability
Generative AI tends to be non-deterministic (running it multiple times even with the same input may result in different behaviour each time it is run). Therefore, how we design, manage and test it needs different thinking from more traditional deterministic technologies. As with machine learning in general, maths and algorithms that are inaccessible to the average person (without knowledge of statistics and data science) create issues in understanding and transparency. Add to this the complexity of enterprise architecture (business, data, applications and applications) in modern organisations, and explainability becomes even more difficult.
This non-deterministic behaviour also creates consistency, reliability and repeatability challenges. Here is a clip from a recent Architect Tomorrow episode that touches on these points:
Scaling and data integration
Scaling systems powered by machine learning is challenging. Creating an algorithm in a lab environment that comes up with an answer in several hours (or even minutes) is OK for a one-off exercise, but simply won’t cut it for real-time customer interaction at scale. It won’t simply be the performance of the ML models; how you integrate these models with enterprise data stores and systems of record will also impact performance. For example, being able to look up a customer’s recent and historical activity to add context is not going to work if the data integration doesn’t deliver the required response time.
Security
Managing the security risks of Enterprise AI is probably a blog post all on its own – in the meantime, this article by NCSC is well worth a read. Sadly, GenAI technologies will very likely lead to whole new classes of security issues in software that leverages them. This can be compared to the early days of web applications and the issues created by unsanitised user input and SQL injection. We are already seeing examples of jailbreaking chatbots and no doubt there will be compromises for LLM-powered applications. Applying sound security practices and not cutting corners (not always easy when you’re in a competitive race to deliver new customer capabilities) will be foundational here. Ensuring your security team is up to speed and understands this area of technology is important – otherwise, there is a danger they might want to shut projects down out of fear.
Costs and the dangers of free trial periods
It has been estimated that GenAI models take millions of dollars to train (not to mention the costs of accessing sought-after and expensive data science talent). Therefore, it’s highly unlikely that platforms that are currently free or low-cost will remain that way. If free platforms do remain, questions naturally need to be asked about their commercial model and whether that includes making use of the data that is fed into them. Checking the terms and conditions and whether these are compatible with your organisation’s policies and regulatory regimes is important. It’s also the reason why “bring your own model” is risky and unwise – unless governed through some kind of management process.
Looking at the future marketplace, it is likely that GenAI-based services will become some of the most expensive cloud services that the hyperscale providers make available. They offer the most value to users, the R&D was and will continue to be expensive, they are expensive to operate, and they come with a stack of risks for the provider to mitigate.
Personally, I think that this technology needs to become more expensive! Due to the hype, excitement and price (often free), it is being used for everything and anything. Really, the expense and energy consumption of machine learning should be applied to more challenging and important problems – challenges cannot be easily solved using traditional (and generally lower footprint) technologies. Training these models requires vast amounts of compute resources (which have an embodied carbon footprint) and consume vast amounts of electricity (again with CO2 impact). Running the models and the inferencing also consumes precious energy. We need to move beyond the era of just throwing software at problems – but this is also a separate topic that I plan to cover in the near future.
A proposed GenAI architecture
We’ve just scratched the surface here and even this creates a lot to consider! To help accelerate your thinking we have identified some key aspects of architecture to consider for customer-facing applications (such as chatbots and real-time content generation). The below diagram is open source under a Creative Commons Attribution 4.0 International License (we’d love to hear from you if you use or evolve it so that we can improve it).
The diagram assumes that you’ve already concluded that the use case or the risks are non-trivial enough that they can’t be solved solely by a GenAI solution such as an LLM (for example just using a white labelled version of ChatGPT). In the future, perhaps GenAI-centric architectures – simply leveraging smart plugins and integrations – will be credible. At the time of writing, this does not look like a sensible approach for most enterprise applications of these technologies.
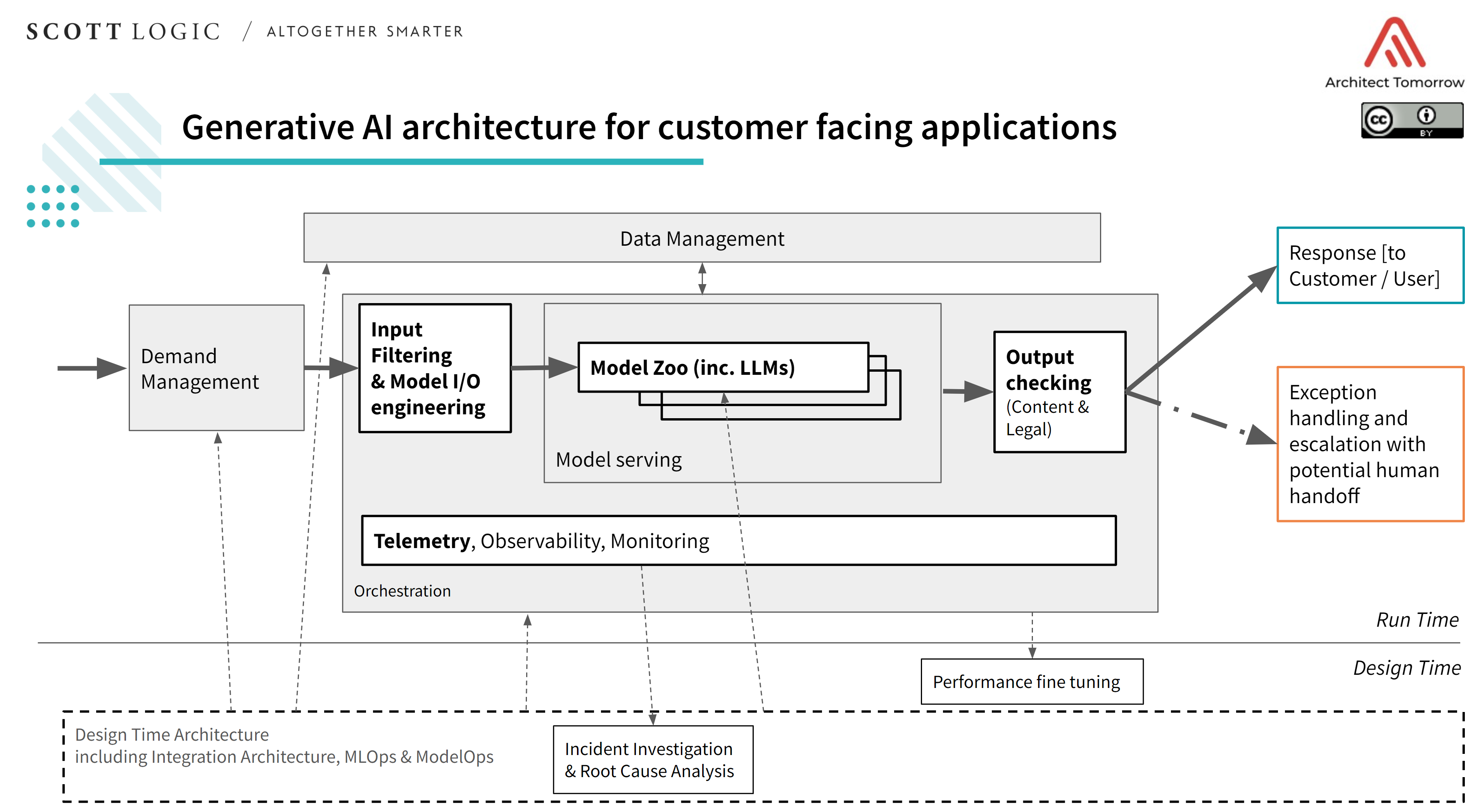
The diagram above is split into runtime and design time architecture. Starting with runtime:
Demand Management
Requests should be managed through demand management mechanisms – ideally in the form of a queuing mechanism. This ensures that the platform is isolated from and can manage the spikes in customer demand. Should the volumes be high enough and the workloads be time sensitive, auto-scaling of the orchestration components is an option to consider.
Orchestration
This is the wrapper or abstraction layer around the different components, managing the generative AI models (in the Model Zoo – more on that later) and providing the framework to add elements such as telemetry capture, input and output checking. The beauty of this is you can keep the upstream and downstream interfaces consistent but swap out components or models within the orchestrator, or scale them up and down as required.
Input filtering and Model IO engineering
Just from using them, it appears pretty likely that ChatGPT and other Chatbot implementations are using a form of input filtering. As an extension of sanitising inputs this makes a lot of sense, but for systems where the input prompt is so critical to the success of the outcome, this is even more vital. The input might need to be significantly altered to get a better chance of success or to avoid content generation risks; for example, requests that could lead to outcomes that are not compatible with the brand of the organisation. Different models in the Model Zoo might require different input data or prompting styles.
Model Zoo
It’s highly unlikely that a single model (regardless of how powerful or general purpose it is) is going to cover all the use cases of a non-trivial application. The orchestrator can draw on a number of approved models in the Model Zoo (ingested from publicly available model hubs such as HuggingFace and internal model development as required). This allows for the management and governance of models used in the application. This approach could potentially lead to something approaching Artificial General Intelligence (AGI) – as narrow specialist models can be called upon to solve specific challenges and fill gaps in more general language models that are good at human interaction.
Telemetry
When aircraft sadly crash, the black box flight recorder is crucial to the investigation of why the accident occurred. When applications leveraging machine learning fail, we need a similar audit trail data source – capturing the input data, decisions and outputs. That way, lessons can be learned and decisions can be made to tune or change models on the basis of data and evidence. From a regulatory perspective, it’s possible that this will be made a requirement when using ML technologies for customer processes – in the future, regulators may demand to see your application telemetry.
Output checking
When dealing with customer requests in real time, it’s not going to be good enough to just try and catch issues and errors after the fact and adjust architecture afterwards. In order to prevent brand damage, misselling, or other mishaps from generating inappropriate content, output checks and filtering is going to be required. This is likely to be a blend of traditional logic-based filtering and ML models that generate a confidence percentage that outputs are aligned with company policies and/or regulatory standards. Responses back to the customer can then be altered or held back and escalated to a human employee to respond to the customer instead.
Design time architecture
Underlying this will be design time components – these will ingest telemetry and performance data and assist with updates to the Model Zoo, input and output filtering, and other supporting components. The performance of the platform can be evaluated and fine-tuned and issues and incidents can be investigated from the captured telemetry data.
Architecture is exciting again!
Once you have enumerated the issues and areas of risk, it can be hard not to be overwhelmed! Every new wave of technology adoption has come with risks and rewards, and attempting to ignore what is looking like the next major technology platform isn’t a sensible option. The key is to prioritise and find pragmatic trade-offs in the areas most of concern. In some instances, it won’t be possible to get your organisation comfortable with the level of risk. When that occurs, you can consider following a “delay and develop” strategy, where R&D investments are made to explore ways to treat the risks or create new control mechanisms prior to customer-facing deployment.
GenAI is making Architecture more exciting – most new applications have been following increasingly standardised cloud platforms and this certainly shakes things up! It is a time to differentiate and innovate with architecture to manage the risks to your organisation whilst allowing for a whole new wave of innovation.
The bottom line is that you need to work with your risk, security, regulatory and/or legal stakeholders as early as possible – collaborate with them so they understand the unique characteristics of GenAI. Treat the associated non-functional requirements and quality attributes as first-class citizens. These are an area for innovation that generally gets overlooked but are vital for safe and successful enterprise adoption of groundbreaking ML models. And if you are looking for a friendly, pragmatic partner on GenAI R&D please do get in touch with myself or Colin Eberhardt!
As a final note – massive thanks to the Architect Tomorrow community and the Scott Logic AI team who have helped pull this together.
Download our white paper
I’ve recently written a white paper on de-risking generative AI in highly regulated environments – you can download the white paper here. And you can visit our page on how to Harness the potential of AI for more of our thinking in this area.