
In this blog post, I put ChatGPT 3.5 through its paces by getting it to help me create a small project, namely a reverse proxy server: a locally running server that will fetch web pages and re-render them for me.
The post is split into two parts. In the first part I get the reverse proxy server up and running.
In the second part we’ll use this starting point to try and do something more interesting: parsing out the human readable text from the html pages being proxied.
The aim is to see how easy it is to generate working code using ChatGPT. Although I’ve done about a year’s worth of front end dev work in the past, I wouldn’t count it as being my strong suit. That’s a deliberate choice since I wanted to see if ChatGPT can do the hard work for me and come up with a solution by responding to what I want rather than telling it how to implement the code. As we’ll see, the results were fairly mixed.
You can read the whole conversation I had with ChatGPT here, in case you do want to see how I produced the code in more detail.
Part 1
A flying start
With the help of ChatGPT, I managed to stand up an express server and have it running in next to no time. When I’ve done this before for previous pet projects, this has always come with a fair bit of time on Google and StackOverflow, so my AI helper was definitely a speed boost for this early stage of the project.

Creating the reverse proxy
Now I was in a position to ask ChatGPT to create a reverse proxy for me. I used only a few lines to describe what I wanted to achieve:
I want the server to be a reverse proxy.
What I mean by this is, if I got to http://localhost:3000/some_url
Then I want the server to fetch some_url, and return the content.
Later on I’ll be modifying the content, but for now I just want to see the web page as though I’d visited it directly.
The code returned had a glaring flaw: it took me to a hardcoded url instead of taking some_url from the path like I had intended.
// Create a proxy middleware
const proxyMiddleware = createProxyMiddleware({
target: 'http://example.com', // Replace with the target URL you want to proxy
changeOrigin: true,
});
// Apply the proxy middleware to all requests
app.use('/', proxyMiddleware);
I’ll leave it up to you to decide if my prompt was ambiguous or not.
It’s probably a caching issue
With a few more prompts and directions, I was provided code that could take the url from the path of the request and proxy to that site.
However, the behaviour was still not quite what I intended. Rather than fetch the content of the url and re-serve it, the code was just redirecting the browser to the site. That wouldn’t do because, as I said in the initial prompt, I wanted to be able to modify the content further down the line.
No matter how much I tried to get ChatGPT to correct this behaviour, the code it returned always had the same problem.
After far more time than I care to admit, I realised that it wasn’t an issue in the code at all, but a caching issue. The Edge browser was caching a previous call I had made and was returning that on every request. I confirmed this by stopping the express server from running and seeing that I was still being returned the website that I’d hit the first time.
I explained this to ChatGPT, but it didn’t believe me.
One step forward, two steps back
Despite ChatGPT’s best efforts, I managed to fix my caching issue. Now I had a slight problem. I had told ChatGPT that several solutions it generated for me didn’t work, however actually I was never hitting them, just the cached page.
Luckily, I had asked ChatGPT to put version numbers on each iteration of the code which it generated (something it generally did quite well but occasionally forgot and had to be reminded). Using these version numbers I set the code back to just before I hit the caching issue, to see if it had fixed the redirection issue after all.
This version had a separate error, trying to split a null value.
Fixing this issue with a null, ChatGPT reintroduced a variant of the first issue I had: hardcoding a url to proxy.
app.use(
'/',
createProxyMiddleware({
target: 'http://theguardian.com/uk',
changeOrigin: true,
secure: false,
})
);
It really did feel like one step forward and two steps backwards.
This quickly became a theme. ChatGPT would often reintroduce the same error multiple times. In the end, I wasn’t able to disentangle what it was doing any more, so I set it back to an older code version and told it specifically what I wanted to change in the code
Let’s use this code:
// Code Version: 2.6
const express = require(‘express’); const app = express();
app.all(‘*’, (req, res) => { const codeVersion = ‘2.6’; console.log(‘Code Version:’, codeVersion);
// Proxy logic or any other desired functionality const targetUrl = req.url.slice(1); // Remove the leading slash (/) from the URL res.send(
Proxying to: ${targetUrl}); });const port = 3000; app.listen(port, () => { console.log(
Server is running on http://localhost:${port}); });But call it version 4.0 And I’d like to log out the version number when I log out the server is running. (And keep iterating everytime you generate new code for me)
But let’s actually get the content at the targetUrl and return that, rather than just say we’re proxying to the targetUrl
Given a hint of what to change, ChatGPT returned code for a working proxy.
// Proxy logic to fetch and return content from targetUrl
const targetUrl = req.url.slice(1); // Remove the leading slash (/) from the URL
try {
const response = await axios.get(targetUrl);
res.send(response.data);
} catch (error) {
console.error('Error proxying:', error);
res.status(500).send('Error proxying request');
}
Although I had told it what to change, I hadn’t given it any technical hints on how to do it, so I was quite impressed that it provided a working solution here.
Part 2
Human readable?
I won’t lie, the web often annoys me. Visit a website and you have lots of scrolling to do before you get to the actual content. For example if you land on a particular Guardian article, it looks like this:
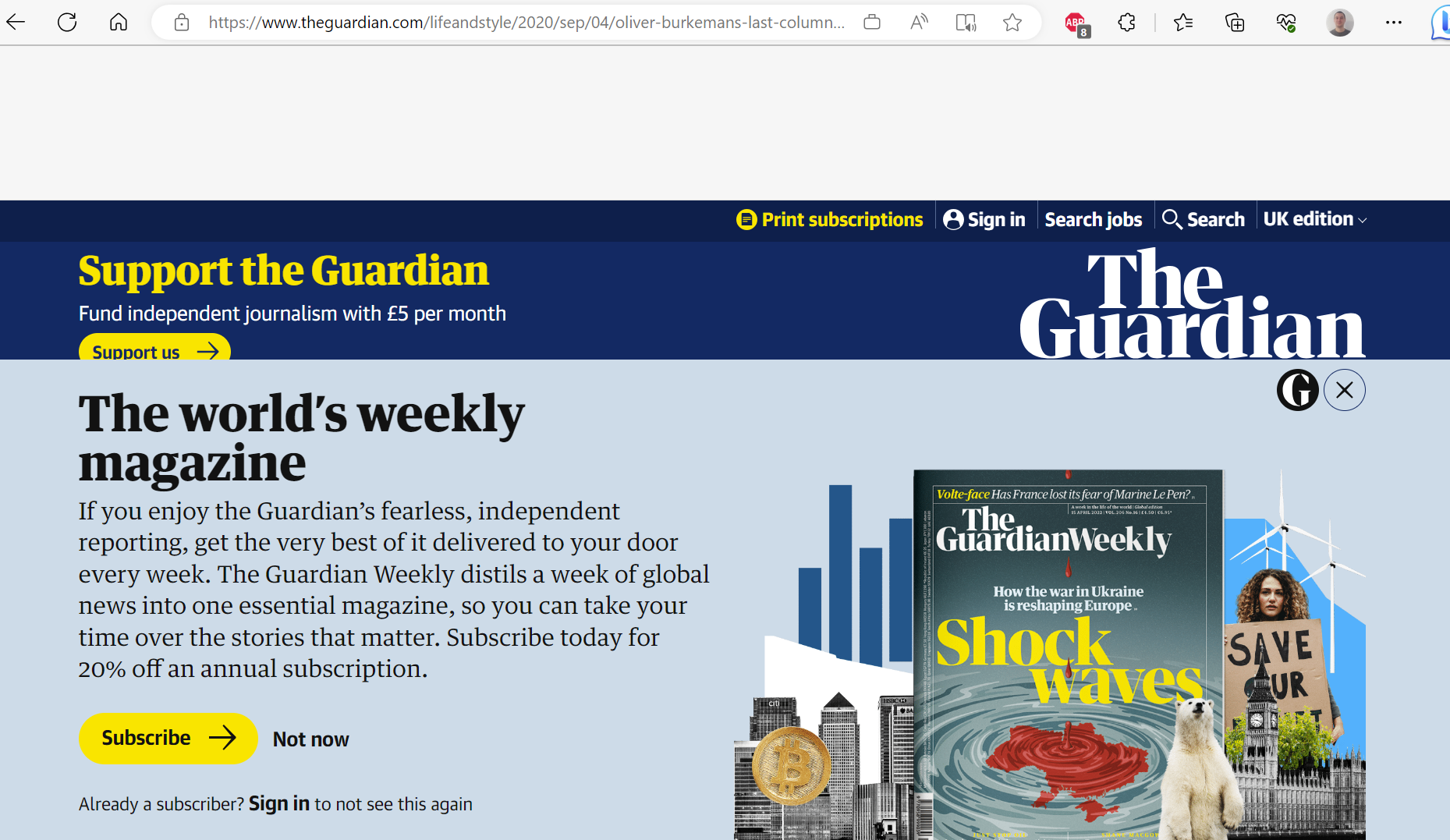 wouldn’t it be nicer if you could just read the content?
wouldn’t it be nicer if you could just read the content?
Now we’ve got our reverse proxy server running locally and fetching the contents of web pages.
I’ll use that as a starting point and get ChatGPT to process the html of the web pages its visiting, parsing out the human readable content from them to serve a version of the page without headers, navbars and images etc.
In order to do so, the proxy server would need to know which html elements contain text that we’re actually interested in.
ChatGPT misunderstood rather what I was asking, and after removing certain html elements it didn’t think I’d be interested in, it returned the body of the remaining html as raw text.
const $ = cheerio.load(html);
// Remove unwanted elements like banners, models, and images
$('header, footer, aside, img').remove();
// Extract text content from remaining elements
const textContent = $('body').text();
This resulted in content like this:
Skip to main contentSkip to navigationdocument.addEventListener(‘DOMContentLoaded’, function(){ // Used to toggle data-link-name on label buttons var navInputCheckbox = document.getElementById(‘top-nav-input-checkbox’) var showMoreButton = document.getElementById(‘show-more-button’) var veggieBurger = document.getElementById(‘veggie-burger’) var expandedMenuClickableTags = document.querySelectorAll(‘.selectableMenuItem’) var expandedMenu = document.getElementById(‘expanded-menu-root’) // We assume News is the 1st column var firstColLabel = document.getElementById(‘
In fairness, I think the prompt I gave ChatGTP wasn’t particularly clear. So I refined it:
Ok you’ve misunderstood slightly. I don’t literally mean I want the text contents of the elements. I mean I want elements that are text.
You can assume the targetUrl is a longform article, I just want the main body of that article
the result was much better:
// Customize these selectors based on the structure of the target website
const selectors = [
'article', // Example: <article> tag represents the main article body
'.content', // Example: <div class="content"> contains the main content
'#main', // Example: <div id="main"> contains the main content
];
for (const selector of selectors) {
const elements = $(selector);
if (elements.length) {
mainContent = elements.first().html();
break;
}
}
This relied on the html being well formatted though, using article tags correctly, and so forth. Often this is the case, but I still wanted to be able to hit web pages where the tags weren’t being used.
I think your solution, while good, relies on the correct use of ‘article’ and ‘main’ tags.
Can you provide a solution which would work if these tags hadn’t been provided?
ChatGPT’s response to this was to add more tags that it thought would be helpful. After trying and failing to get this approach to work I suggested something different.
This is good, but I’m now capturing too many tags not meant for human consumption. Can you think of a way to remove elements that aren’t related to the main body of the page?
Don’t rely on class selectors, think about their content length and their position in the page instead.
and then further refined the ask
Not quite got there.
Are you able to look at the content of an element and decide if it is likely to be a full sentence?
Let’s only include elements that have a full sentence in them.
Not quite what I meant.
I would like to include this element
<p class="dcr-8zipgp">I am drawing a line today not because I have uncovered all the answers, but because I have a powerful hunch that the moment is right to do so. If nothing else, I hope I’ve acquired sufficient self-knowledge to know when it’s time to move on. So what did I learn? What follows isn’t intended as an exhaustive summary. But these are the principles that surfaced again and again, and that now seem to me most useful for navigating times as baffling and stress-inducing as ours.</p>Even if it wasn’t a
<p>element. Perhaps it is some unknown element<banana>but if it has that content, of full sentences, I want to see it.
We were now getting something that, while rough, was basically doing what I wanted it to do.
// Code Version: 4.10
const express = require('express');
const app = express();
const axios = require('axios');
const cheerio = require('cheerio');
const sentenceRegex = /[.?!]\s*$/; // Regex to check if a string ends with a sentence-ending punctuation mark
const codeVersion = '4.10';
app.all('*', async (req, res) => {
console.log('Code Version:', codeVersion);
// Proxy logic to fetch and return main body of the article from targetUrl
const targetUrl = req.url.slice(1); // Remove the leading slash (/) from the URL
try {
const response = await axios.get(targetUrl);
const html = response.data;
const $ = cheerio.load(html);
const mainContent = [];
$('body')
.find('*')
.each((index, element) => {
const $element = $(element);
const content = $element.text().trim();
const isExcludedTag = ['script', 'style', 'svg'].includes($element.prop('tagName').toLowerCase());
const containsFullSentence = sentenceRegex.test(content);
if (!isExcludedTag && containsFullSentence) {
mainContent.push($element.html());
}
});
res.send(mainContent.join('<br><br>'));
} catch (error) {
console.error('Error proxying:', error);
res.status(500).send('Error proxying request');
}
});
const port = 3000;
app.listen(port, () => {
console.log(`Server (Version ${codeVersion}) is running on http://localhost:${port}`);
});
(You might also notice that the code is logging the version number out on each request, and not just on startup as I asked for. )
It was interesting that by having this back and forth with the AI, I came up with a solution that I hadn’t had in mind at the outset: to look for full sentences in the html body (and ChatGPT implemented that ask well). My initial idea was to look at the length of the text within html elements.
After adding a few more tweaks, styling and adding some features like dark mode I had an app I deemed usable. The whole effort had taken about six hours.

Conclusions
Productivity tool?
With the help of ChatGPT, I was able to get a working reverse proxy server up and running quickly. Although the initial setup was quicker, I think the overall time to write it was probably longer than it would have been without assistance.
When it came to parsing the html and adding some further features like some nice css styling, ChatGPT definitely saved me time over having to implement the details myself.
So while using an AI definitely sped me up, what concerned me was that there were several spots where I had to understand the code it had written and tell it change specific parts. It certainly feels like we’re a long way off the point where ChatGPT or a similar AI tool will be able to create working software without the close supervision of a developer who understands the code being output.
This goes beyond the code itself as well, as my caching issue demonstrated. In order to create working software, you have to understand not just the code itself but also the ecosystem in which it is running and how it interacts with other moving parts.
It didn’t matter how many times I explained the symptoms to ChatGPT, it never made the leap to realising that the browser was introducing problems separate to the code it was outputting.
This tiny project was just a microcosm to explore the tool and I’m sure that ChatGPT and other AIs will become more proficient in the near future. But the problems we want to solve will be far greater than this reverse proxy as well. When ChatGPT produced code for this project which I didn’t understand, in order to fix problems I would rewind it to a point I did understand and go again. This wasn’t just me trying to be pragmatic, my attempts to get ChatGPT to fix issues by telling it the errors I was seeing proved fruitless, with the same errors often being introduced multiple times.
How would this approach fare on a much larger project with thousands of lines of code across hundreds of files, generated at the request of a dozen different developers? I think it would be all to easy to dig yourself into a hole that neither you or the AI would be able to dig you out of.
Similarly, I’m sure AIs in the near future will become more aware that their express server is being accessed by a browser and may ‘think’ to look at caching issues in the browser and not in the code. But real software projects will be parts of much larger chains of software than this, and I wonder if the AIs will be able to understand the full context for which they are producing code and reason through problems as they occur.
Technology choices and copyright issues
By using an AI in the way I did, I allowed it to make some technology choices for me. For example, in the code above you can see that the axios and cheerio libraries were suggested for me. I didn’t mention them, I gave ChatGPT a problem to solve and it provided these technologies in the solution.
And further to this, of course, the AI was generating JavaScript code for me. It’s learnt that syntax from reading existing JavaScript applications.
I often think about the moral and copyright issues behind this. Many developers have written the code that ChatGPT trained on. Is that work being acknowledged and rewarded?
An early demonstration of Copilot has stuck with me where the presenter asked the AI for an inverse square root function. Copilot obliged by reproducing exactly John Carmack’s famous fast inverse square root function, complete with the original comments.
Cases like this have made me quite hesitant about the use of AI as a coding tool, both because of potential legal issues if I accidentally used copyrighted code, but also morally about using training data that didn’t have the author’s consent.
Working on this blog post, I’ve actually come to the opposite conclusion, at least going forward.
I believe that AI will soon be in a place that it will be an almost invaluable productivity tool for developers. Once that’s the case, AIs will be in a position to suggest solutions that use particular frameworks, libraries, and programming languages. Namely the ones they were trained on.
This will act as a barrier to adopting any new technologies. For example, if you’ve written a new library, how do you attract new users? It will only get adopted if the AI suggests your library as part of a solution. Users won’t want to adopt it if their AI tool can’t help them work with it.
So how do you get your library into the training set? Do you have to produce large volumes of examples for the AI to train on in order for it to become adopted?
My suspicion is that AI training will become pay-to-play. When a new library or language is created, I think the authors will be paying the maintainers of the AI in order to get their work into the training set and pushed to end users.

