
Advent of Code (AoC) is an annual, christmas-themed, coding competition that has been running for the past years and is something that I participate in at times. This year, while ~~subjecting myself to~~ learning Rust, I decided to see how OpenAI’s latest model fared at the challenge. I quickly knocked together a script, and to my astonishment, found that o1-mini gave correct answers to all but one part of the first six days. It was writing code to complete puzzles that took me half an hour or more, in just seconds!
In this blog post I’m going to dig into the results in a bit more detail.
Before I proceed, I do want to very briefly address the elephant in the room here. AoC is a community contest, with people understandably being quite excited about the competitive element. Unfortunately this year the leaderboards have been overrun by people quite clearly using LLMs, completing the puzzles in seconds. There is a long discussion on this topic on Reddit, with thoughts from Eric, the creator of AoC. I have no intention of using LLMs land a spot on the leaderboard. With the powerful LLMs that have recently emerged, anyone could do this. If after reading this post, you do decide that’s what you want to do, I don’t consider it a demonstration of your skill, instead it is a demonstration of your disregard for other people. My only motivation in this post is to use AoC as a highly relatable exploration of LLM capabilities.
The test harness
To allow for better automation, I replaced my hacked together script with something more robust, using the excellent Inspect framework from the UK AI Safety Institute. It abstracts across multiple LLMs, provides multi-threaded test running, logging, statistics and much more. The only part of my test suite that is a little unusual is the scoring step, which executes the LLM response, checking against the AoC answers. I was also very happy to find an AoC dataset on Hugging Face going all the way back to 2015.
Probably the most interesting part of my test suite is the system prompt, which is pretty simple:
You are skilled JavaScript engineer that is competitive at code competition. Your
input is a programming puzzle. Your job is to solve the puzzle by writing a JavaScript
function call 'main' that takes the puzzle input as a string, returning the result.
Do not describe your approach, only return the JavaScript code.
When give a puzzle that has a part one and part two component, only give code required
to answer for part two.
Just how good is o1-mini?
Various other people have experimented with using LLMs to solve AoC puzzles in the past. Last year ‘The Motte’ used GPT-4 to tackle the first 12 days of AoC23, finding that it could answer 29% of the questions. Also, in June 2024 Johannes Sandström published a thesis which looked at the performance of numerous models (ChatGPT, Copilot, Deepseeker, Gemini, Le Chatm, Claude Opus and more), but concluded that:
it is clear that these LLMs are good at generating code, but Advent of Code 2023 is too difficult to solve.
The best performance came from GPT-4, which solved 32% of the puzzles correctly.
There is scope to make these LLMs perform better at coding challenges by using prompting techniques such as chain of thought. However, I, and the authors above, are more interested in the ‘out of the box’ performance.
OpenAIs o1 was only released a couple of months ago, and differs from other models in that it has been trained to spend more time ‘thinking’ by following a chain of thought process internally. This makes it more suited to reasoning tasks, such as AoC.
I tested the performance of previous generations of OpenAI models (GPT3.5, GPT4) to see how they compare. The following chart shows the number of correct responses given for the first 11 days (22 problems) by each model:
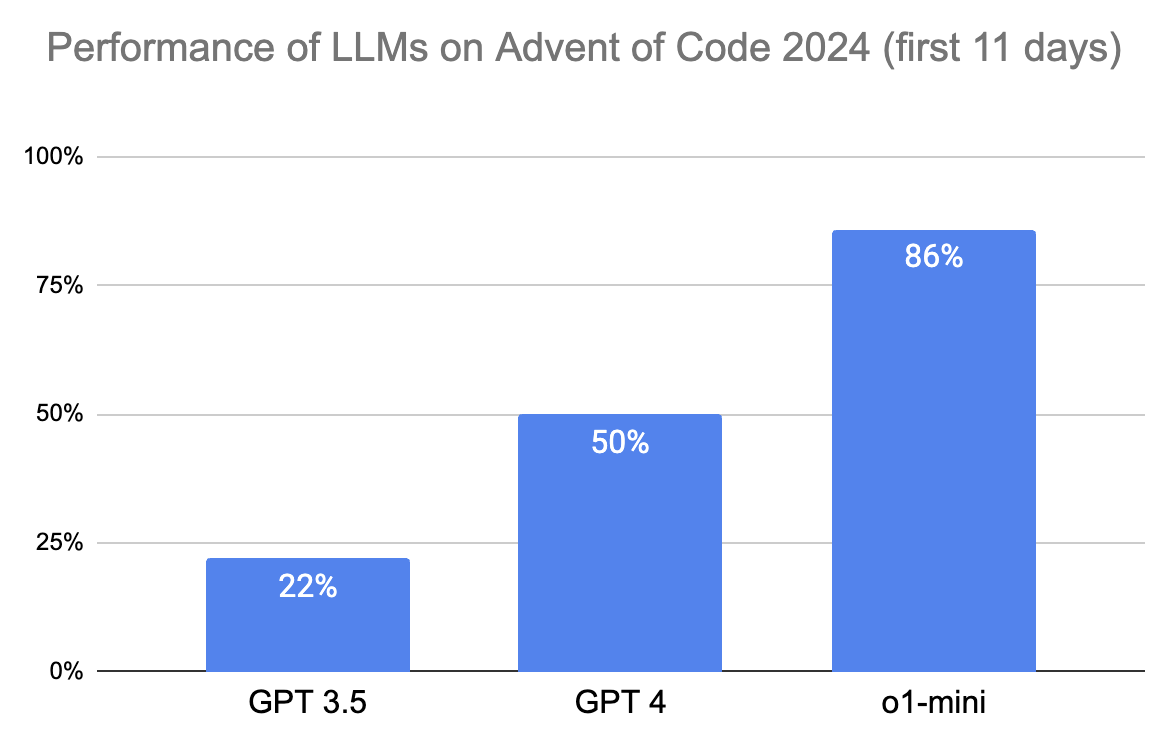
From the above chart, it is clear that o1-mini provides a significant step forwards, solving 86% of the puzzles (failing only on part 2 of day 6 and both parts of day 9). For those of you who are familiar with AoC, you’ll know that this is a deeply impressive result. While the first few days are relatively easy, the difficulty ramps up very quickly. Less than a quarter of people who started AoC this year have made it to day 11.
These aren’t trivial challenges either, the answer o1-mini provided for day 8 part 2 is 90 lines of code.
As an aside, I also briefly experimented with Anthropic’s Claude Opus, their flagship model, and found it’s performance to be similar to GPT4. I also found Claude to be incredibly slow, responding in ~40 seconds, whereas all of the OpenAI models respond in just a few seconds.
I was also interested to see how o1-mini would perform on previous years challenges, and the full 25 days. Here is the results for the past six years:
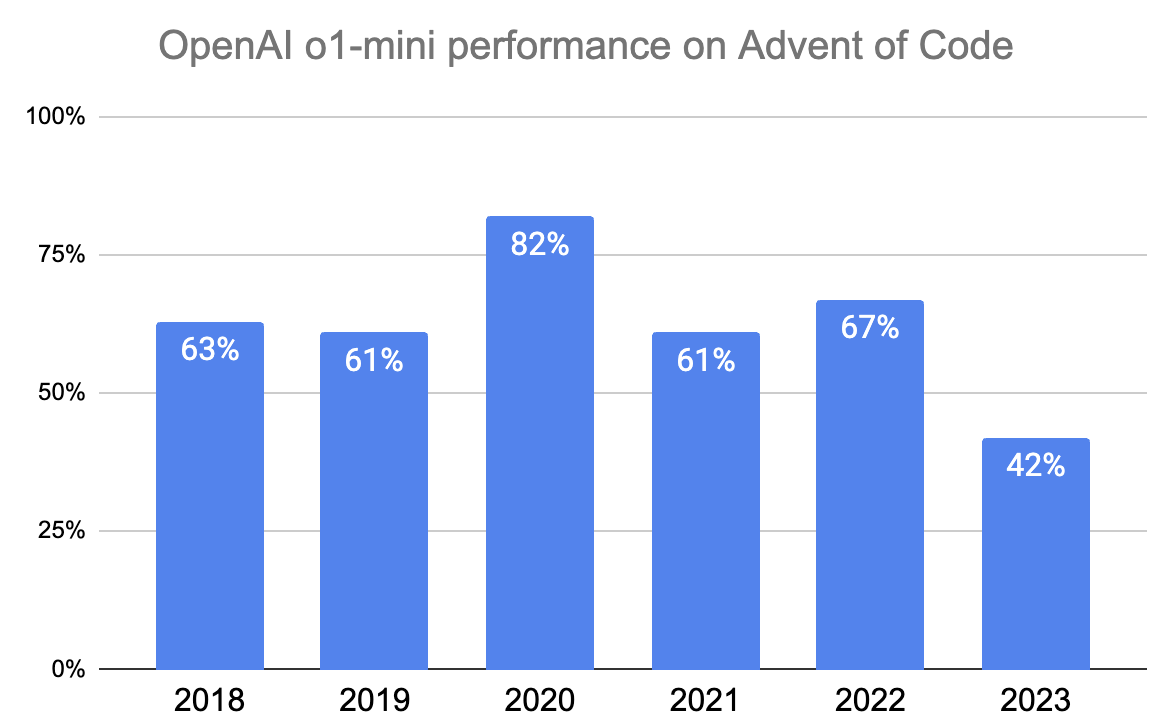
An impressive result, however, it is worth noting that AoC is talked about on many forums, and there are hundreds of GitHub repositories containing answers which this model will have been trained on. This is of course not the case with the 2024 questions.
Failure modes
For one of the years (2019) I took a closer look at the puzzles where o1-mini had failed to give the correct answer. Here’s a visual summary:
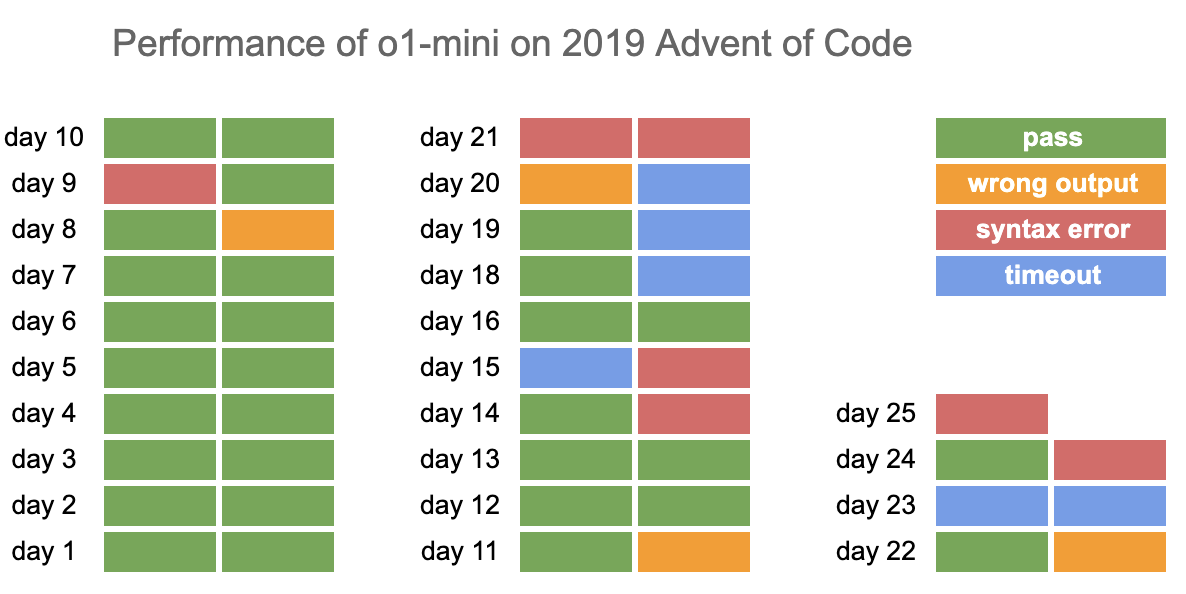
The failure modes are:
- wrong output - In these cases, the code provided by the model simply gives the wrong answer
- syntax error - Here, the code provide by the model is mal-formed in some way. This highlights an important point, LLMs do not ‘understand’ code or its syntax. They do not compile or interpret the code before responding. They are instead following patterns from their training dataset. Given this fact, it’s quite astonishing that they can emit so much code without syntax errors!
- timeout - This is something of an AoC special! As the competition progresses, the puzzles tend to be written in such a way that the brute force approach is prohibitively slow.
With this years challenge, the brute force approach to day 11 runs for days, and the initial output from o1-mini fell into this trap. I experimented with adding the following to the system prompt:
Consider smart algorithmic methods and mathematical techniques that might yield a better result.
And instead it provided a recursive solution, with caching, that solved the problem in less than a second. Impressive!
Closing thoughts
Given the performance of o1-mini, I feel it is inevitable that it (and whatever advances come next) is going to have a significant impact on the world of software engineering. Yes, AoC is somewhat contrived version of what software professionals do for a living. But its ability to take lengthy prose and convert it into tens of lines of code that accurately reflects the requirements is astonishing. Just a few years back, would any of us have imagined that this would be possible?

