
Why Would I Do This?
Initially, my Advent of Code solutions were written in Rust using the standard library, running on a typical desktop or laptop with ample processing power and memory. In January, after Advent of Code had officially completed for the year, I was discussing with my colleague Chris the challenges encountered and whether they were solvable on more constrained hardware. Thus was born the challenge to implement solutions on bare-metal hardware, specifically on a Raspberry Pi Pico.
Questions I was interested in:
- Would a tiny microcontroller like the Pi Pico handle Advent of Code challenges effectively?
- Could it process intensive computations within reasonable time limits?
- Would the process of implementing solutions for the more constrained hardware be rewarding?
Advent of Code
Advent of Code is an annual programming competition that runs throughout December, offering daily coding challenges that increase in complexity. The problems often involve computationally intensive tasks like pathfinding, recursion, and data manipulation, which made them challenging to solve when running on embedded hardware with limited resources.
The Raspberry Pi Pico
The Raspberry Pi Pico is a microcontroller based on the RP2040 chip. It has the following characteristics relevant to the challenge:
- Dual-core ARM Cortex-M0+ processor running at up to 133 MHz
- 264 KB of SRAM, and 2MB of external flash
While the Pico is powerful for a microcontroller, it lacks the conveniences of a full-fledged operating system—no dynamic memory allocation (malloc/free), no standard I/O, and no built-in file system. This makes running Advent of Code solutions particularly tricky, as they often involve handling large data sets, recursion-heavy algorithms, and complex computations.
Goals of the Migration
I decided that migrating the first 10 days of my Advent of Code solution would be a sufficiently challenging objective. It would include challenges solved by 75% of those participants who completed at least day 1 (based on completion statistics summary):
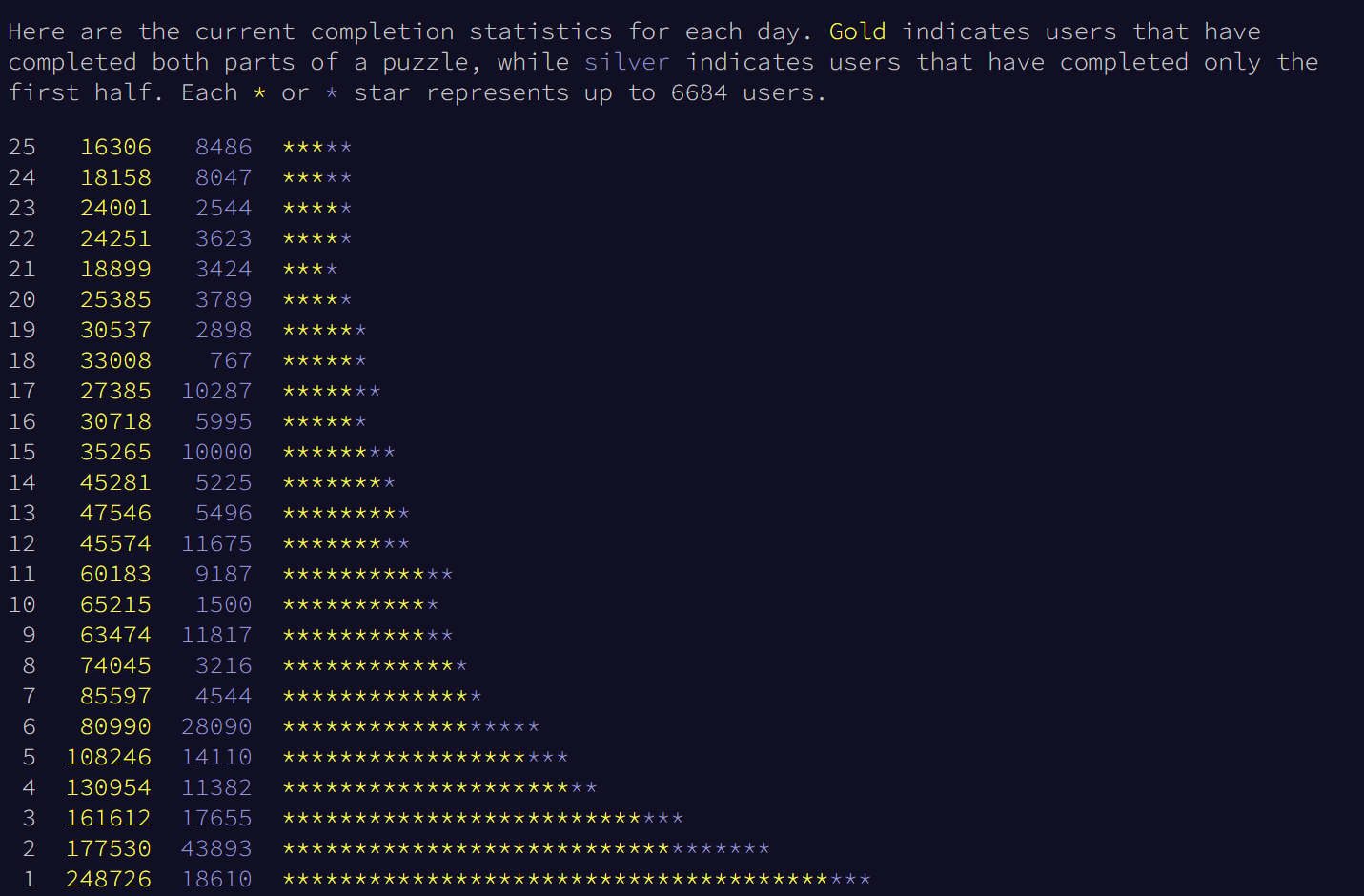
Migrating my Advent of Code solutions to no_std Rust on the Pi Pico meant setting some clear objectives:
- Successfully run Rust solutions on bare-metal hardware without relying on an operating system.
- Rewrite problem solutions to work without heap allocation, adapting algorithms to work efficiently with limited stack space.
- Document challenges and solutions encountered during the migration, to help others who might attempt something similar.
This post will detail that journey: the technical hurdles, lessons learned, and ultimately whether this experiment was worth the effort.
Why Rust?
Experience, Compiles to Native
Rust has been my language of choice for Advent of Code due to its strong type safety, powerful pattern matching, and high-performance execution. Rust compiles directly to native machine code, which means it can run efficiently without requiring a runtime environment. This is particularly useful for computationally heavy problems that involve recursion, graph traversal, or large-scale data processing.
Additionally, Rust’s strict borrow checker helps catch potential memory safety issues at compile time, making it a great fit for complex problem-solving where correctness is crucial. Given my prior experience with Rust in a standard development environment, I wanted to see how well it would translate to a completely different domain: bare-metal embedded development.
Embedded: Supported, Active Community
Rust has rapidly gained traction in the embedded systems world, thanks to its no_std support and an active community working on microcontroller-friendly libraries. The Rust Embedded Working Group maintains key crates like:
embedded-hal– A common interface for hardware abstraction layersrp2040-hal– A Rust HAL (Hardware Abstraction Layer) for the Raspberry Pi RP2040defmt– A lightweight logging framework optimized for embedded environments
With strong community support, evolving tooling, and increasing adoption in industry, Rust seemed like the right choice for an embedded experiment like this.
Characteristics of the Raspberry Pi Pico
Small RAM
As mentioned before, one of the biggest limitations of the Raspberry Pi Pico is its comparatively small RAM size—only 264 KB, which is a drastic step down from the gigabytes of RAM typically available in a desktop environment. Many Advent of Code problems involve working with large datasets, such as parsing long input files or storing intermediate results in complex data structures. Managing memory efficiently (without the safety net of dynamic allocation) will prove to be a key challenge.
Application Code and Constants in Flash
Unlike a traditional computer where the OS loads an application into RAM, the Pi Pico executes code directly from external flash memory. This means:
- Code and constants reside in flash, leaving RAM primarily for stack and heap usage.
- Flash memory is slower than RAM, so excessive access can impact performance.
- Flash has a limited number of write cycles, making it unsuitable for frequent modifications at runtime.
This required careful consideration of where data was stored, ensuring that large immutable structures could be placed in flash while keeping frequently modified data in RAM.
Challenges From My Coding Style
Heavily Based on Containers
Switching from std to no_std changes how you think about programming. Gone are the days of freely allocating memory, using high-level debugging tools, or relying on OS abstractions. Instead, every byte matters, and careful planning is required to make the most of limited resources.
In a normal Rust development environment, I tend to rely heavily on collections like Vec, HashSet, and HashMap to store and process data. These structures provide flexibility, dynamic resizing, and convenient API methods for common operations. However, in a no_std environment, these standard collections are unavailable because they rely on heap allocation.
When transitioning from std to no_std, several commonly used features disappear. These include the following:
Panics and Error Handling
The default panic behavior in std (in modules std::panic and std::error) assumes access to println! or stderr, which don’t exist in no_std. Instead, panics must be handled with custom handlers, which usually rely on hardware support or peripherals. For example, they can halt or reset the device, or set a connected LED to blinking.
Standard Debugging Tools
Without a console or terminal, println! doesn’t work, so debugging requires alternatives. In my case I use a Raspberry PI Debug Probe (connected to the pico via SWD Debug connection, and to the host over USB), which permits use of lightweight logging (defmt), with logging materialised on a host with log display capacity.

Standard Containers
As the standard containers are dependent on alloc, I replace them with stack-allocated size-bounded alternatives:
- Instead of Vec, I use arrayvec::ArrayVec.
- Instead of HashSet, I use scapegoat::SgSet.
Setting Up the Development Environment
Now that I’ve clarified the constraints and challenges we’ll be operating within, I’ll detail the practicalities of how I addressed them, starting with the basics - setting up the development environment.
Toolchain Setup for no_std on the Pi Pico
To compile Rust for the Raspberry Pi Pico, we need a toolchain that supports no_std and targets the RP2040’s ARM Cortex-M0+ architecture.
The first step is to set up Rust to build for the hardware. Since the RP2040 is an ARM-based microcontroller, we need the appropriate Rust target:
rustup target add thumbv6m-none-eabi
This tells Rust to support compilation for the thumbv6m-none-eabi target, which is suitable for the Cortex-M0+ CPU.
The next setup to perform is to install probe-rs, which is a modern tool for flashing and debugging Rust programs on embedded devices:
cargo install probe-rs cargo-embed
For no_std, we don’t use the standard Rust runtime (std), so our Cargo.toml must include the following:
[dependencies]
cortex-m = "0.7"
cortex-m-rt = "0.7"
embassy-embedded-hal = "0.1.0"
embedded-hal = "0.2"
panic-probe = "0.3"
cortex-mprovides low-level access to Cortex-M processorscortex-m-rtprovides the startup runtime, ensuring correct entry points.embedded-halsupplies a Hardware Abstraction Layer for embedded systems.embassy-embedded-halprovides utilities to useembedded-halwith Embassy.panic-probeimplements a panic handler that exits aprobe-runwith an error code.
Lastly, we need to configure Cargo to build for the ARM/Cortex-M target by default, by adding a .cargo/config.toml file:
[build]
target = "thumbv6m-none-eabi"
Now, running cargo build will automatically compile for the RP2040.
Setup for Experiments (Windows vs Pico Runner)
As the process for migrating existing Advent of Code solutions from a std environment is challenging, I decided to setup two no_std execution environments:
Windows
- Used for minimising development time, as no need to flash memory and runs on high speed CPU
- Has access to full system memory which means that solutions which complete successfully could still run out of memory on microcontroller
- Solutions adapted to run without dynamic memory
- Ran test cases and verified correctness before porting to embedded.
- Cargo command line to run:
cargo run --target=x86_64-pc-windows-msvc --bin winmain --features log
Raspberry Pi Pico
- Used for final testing of the migration process and performance analysis.
- Used logging over the debug probe (as described above), instead of
println!for debugging. - Measured execution speed to compare embedded performance vs. PC.
- Cargo command line to flash, and run (with debug probe connected):
cargo run --bin embassy_runner --features defmt
This dual setup allowed me to test the no_std migration on Windows before evaluating performance on the target microcontroller.
Import of the Problem Data
Before the solution migration can be evaluated, the problem input data must be read. On a standard OS, I simply read this from a file. However, in an embedded no_std environment, there’s no filesystem, so I had to explore alternative methods.
Hardcoding the Data as a Rust String (&str)
Store the problem input directly in the Rust source code as a string constant:
const INPUT: &str = "123\n456\n789\n...";
Pros
- Simple, easy to use.
Cons
- The Rust compiler stores &str in read-only memory (Flash), but it’s UTF-8 encoded, which might introduce unnecessary overhead.
- Large inputs can clutter the source file.
Embedding the Data as a Byte Array (include_bytes!)
Use Rust’s compile-time macro to embed the file as a byte array:
const INPUT: &[u8] = include_bytes!("input.txt");
Pros
- Efficiently stores data in Flash without modification.
- No need to manually escape special characters (unlike hardcoded &str).
- Avoids unnecessary UTF-8 validation overhead.
- Does not clutter the source file with literal data.
Cons
- The data is in raw bytes, so I would have to convert it to a string if needed.
Storing Data in an Allocated Buffer in RAM
Data could be manually copied into a statically allocated buffer at runtime (from either of the above flash-based initial options):
static mut INPUT_BUFFER: [u8; 1024] = [0; 1024];
Pros
- Allows runtime modification of data.
Cons
- Wastes RAM, which is extremely limited on the RP2040.
- Needs unsafe code to mutate the static buffer.
Ultimately, I chose include_bytes! because it provided a balance of efficiency and simplicity:
- Stores data directly in Flash, preserving RAM for computation.
- Avoids the need for manual encoding/escaping that a &str constant would require.
- Works seamlessly in no_std without requiring additional crates or allocators.
- I didn’t anticipate needing to work with the data as a string, so that potential concern wasn’t an issue.
Parsing the Input
Once the problem data was embedded using include_bytes!, the next step was parsing it into a usable format. In a standard Rust setup, I tend to drive parsing from a tokenizer which is based on regex::Regex. However, in a no_std environment, I found it impossible to get to work in the absence of alloc, so I investigated other options.
Given that the input was stored as a byte array (&[u8]) in Flash, I considered several approaches for parsing.
Manually parsing into an arrayvec::ArrayVec
- As discussed earlier, we can use fixed-capacity collections, like
arrayvec::ArrayVec, which act likeVecbut without heap allocation:
use arrayvec::ArrayVec;
let mut numbers: ArrayVec<u32, 100> = ArrayVec::new();
for line in input_str.split(|&c| c == b'\n') {
if let Ok(num) = core::str::from_utf8(line).unwrap().parse::<u32>() {
numbers.push(num).ok(); // .ok() ignores push errors when full
}
}
Pros
- Allows flexibility in input size while remaining
no_std.
Cons
- Needs to define an upper limit (
100in this case). - Involves manual parsing logic, which can get convoluted for complex inputs.
Using nom for Robust Parsing (Final Selection)
nomis a parser combinator library that works inno_std, allowing parsing to be expressed in a declarative, reusable manner.- Example for extracting numbers from input:
use nom::{
bytes::complete::take_until,
character::complete::u32,
multi::separated_list1,
combinator::all_consuming,
IResult,
};
fn parse_numbers(input: &[u8]) -> IResult<&[u8], heapless::Vec<u32, 100>> {
let (input, numbers) = separated_list1(take_until("\n"), u32)(input)?;
Ok((input, arrayvec::ArrayVec::from(&numbers).unwrap()))
}
Pros
- Declarative and reusable – makes parsing logic more readable.
- Optimized and memory-safe – doesn’t require unnecessary allocations.
- Works well with
arrayvec::ArrayVec– efficiently manages parsed data in RAM.
Cons
- Slightly larger code size than manual parsing.
- Still need to define an upper limit on collections (
100in this case). - Large Learning curve if unfamiliar with parser combinators.
In the end, I chose nom because it provided the best trade-off between:
- Readability - Parsing logic is clear and modular.
- Efficiency - Works in
no_stdwithheapless::Vec. - Scalability - Easily adaptable to more complex AoC problems.
While arrayvec::ArrayVec was useful for dynamic storage, nom handled the actual parsing logic in a way that was both memory-efficient and expressive.
Challenges Faced in the Migration
Dependencies incompatible with no_std
As described above I encountered difficulties with regex::Regex working in the absence of alloc which led to replacing it with a more no-std-friendly crate.
In addition, many of the Advent of Code problems rely on graph algorithms to solve which I tend to use algorithm implementations from the pathfinding crate. These rely on alloc and the std collections and hence are not available for execution in a heapless environment. Fortunately, the algorithms are well documented online, and so I resorted to implementation of these from available pseudo-code.
Memory Challenges
The primary issue I found in running on the microcontroller (after code was proven working on the no_std Windows runner) related to memory pressure, of which the trickiest issue I (repeatedly) ran into was stack overflows. The RP2040 has only 264KB of RAM, and each function call consumes stack space. Problems arose when:
Using Deep Recursion
- Many AoC problems use recursion, but deep recursion can quickly overflow the stack.
- Solution: Convert recursive functions to iterative versions using a stack data structure.
Example: Changing a recursive DFS to an explicit stack-based loop:
let mut stack = heapless::Vec::<u32, 100>::new();
stack.push(start).unwrap();
while let Some(node) = stack.pop() {
// Process node
}
Allocating Large Buffers on the Stack
- Declaring a large local array inside a function caused stack overflows.
- Solution: Use
staticmemory instead of stack allocation:
static BUFFER: StaticCell<[u8; 1024]> = StaticCell::new(); // Stored in global memory
.
.
.
fn analyse() {
let buffer = BUFFER.init_with(|| [0; 1024]);
// Usage of buffer
}
Results: Comparative performance
Table of results for each day (windows vs pico)
| Problem | Windows Runtime | Pico Runtime | Proportional Runtime |
|---|---|---|---|
| 1 | 0 s | 2.65 s | 1:3000 |
| 2 | 0 s | 0.13 s | 1:125 |
| 3 | 0.01 s | 0.05 s | 1:4 |
| 4 | 0 s | 0.08 s | 1:85 |
| 5 | 0.01 s | 4.65 s | 1:275 |
| 6 | 0.08 s | 37.23 s | 1:470 |
| 7 | 0.80 s | 186.18 s | 1:225 |
| 8 | 0.02 s | 3.46 s | 1:200 |
| 9 | 0.17 s | 23.95 s | 1:145 |
| 10 | 0 s | 1.19 s | 1:600 |
| Overall | 1.12 s | 259.56 s | 1:250 |
The performance differences between the Raspberry Pi Pico and a Windows PC can be attributed to several factors. The Cortex-M processor on the Pico runs at 133 MHz, while the Windows PC operates at 3 GHz, resulting in a speed ratio of approximately 1:23. However, the residual variance, roughly 1:10, suggests additional contributing factors. These may include differences in memory speed, the use of Flash versus RAM, and the word length of the processors (32-bit for the Pico versus 64-bit for the Windows PC).
Conclusion and Next Steps
I found Rust a natural fit for embedded projects. While the support crates are still in active development, they are mature enough to perform meaningful development. Compilation to native code and flashing to on-board flash is a painless process once the one-time setup is in-place.
Despite a microcontroller being a hugely more constrained environment than we typically address, the lessons learned are applicable as:
- When implemented in a language / runtime which uses a garbage collector, efficient memory management reduces garbage collection (GC) pauses, leading to better responsiveness and throughput.
- Optimized memory usage allows systems to scale better, handling more users or requests without needing additional hardware.
- Memory usage directly impacts costs for applications which are run in cloud environments (e.g., AWS, GCP).
If I were to migrate equivalent code to run on a microcontroller in future, I would look into using an embedded allocator, for example:
alloc-cortex-m– Provides a heap allocator for Cortex-M chips like the RP2040.linked_list_allocator– A simple,no_std-friendly allocator.
In future, I would like to expand my embedded experience with projects where microcontrollers more naturally have a role to play, for example control of peripherals (lights, motors, …)
If you are interested in viewing the code associated with this blog, my original solutions to Advent of Code (all days) are available here. The migrated solutions are here.
