
Ponytail is a trending Skill that “makes your AI agent think like the laziest senior dev in the room”. It claims to address the frequently observed behaviour where coding agents over-engineering and simply emit more code than is necessary, whereas with Ponytail you get terse code and no over-embellishment. Sounds great? The 20k stars this project has gained in around one week and their impressive benchmark results appear certainly look compelling.
However, when I dug into what Ponytail actually is, I found it was little more than a brief Skill (i.e. markdown file) of around 100 lines, the substance of which is little more than a description of the YAGNI (You Ain’t Gonna Need It) principle from back in the 1990s.
Swapping out Ponytail for the three words “Follow YAGNI principles” almost matched the benchmark score, and elaborating to seven, “Follow YAGNI principles, and one-liner solutions”, beat Poytails score.
How can a project this simple, this unproven and fragile gain so many stars and so much attention?
I’ll try to answer that question and explain why I spent time trying to work out whether this project delivered value or was just hype. Whether it is hype or not is subjective, but my evidence doesn’t support the scale of the attention it has received.
UPDATE: After reading the results of this blog post, the Ponytail author responded by both expanding and fixing their benchmarks and revising their claims. I am really happy that they responded positively to the criticism - you can read more from them on LinkedIn.
Why do people want a “Ponytail”?
Whether you like it or not, we are increasingly moving to a world where a significant amount of software engineering involves prompting models. Whether you are using sophisticated agentic harnesses, or just one-shotting code, your productivity depends on both your ability to describe your goals to the model and your understanding of its strengths and weaknesses.
This isn’t an easy (human) skill to acquire. Firstly, the strengths and weakness of models are quite opaque, and are often described as jagged. This description is quite apt, they can perform amazingly well at some tasks, whilst failing abysmally on others that are superficially similar. Secondly, prompting is more like creative writing than coding. For engineers who thrive on well-defined system behaviours, explainable logic and communicate with precision, this is quite unsettling.
As a result, there are numerous prompt-based Skills and frameworks that attempt to coach these models into either being more like us (e.g. Ponytail, Agent Skills, PM Skills) or creating a whole cohort of individuals with specific traits (e.g. Gas Town).
The promises of these various frameworks sound good, but how do you prove that any of these solutions deliver on their claims?
Provable results
This is something I have been concerned about for quite a while, especially with the recent proliferation of Skills. This is why I asked the question “How are you testing Skills or ensuring quality?” on Anthopic’s Skills repo (152k stars!) a few months back:
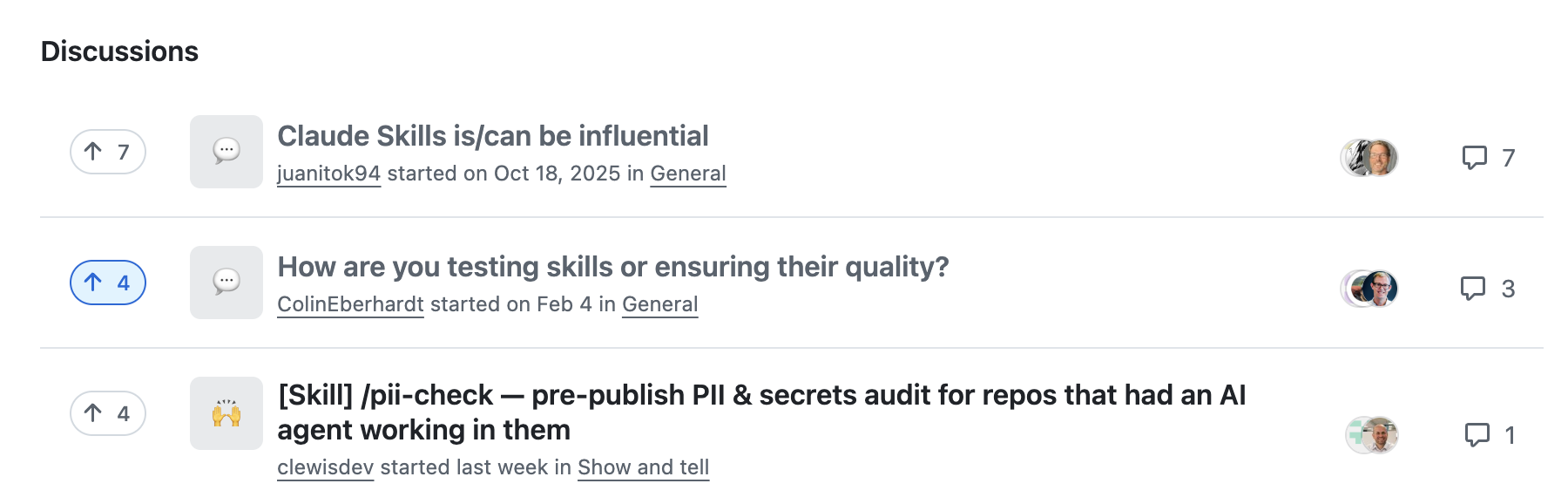
It’s the second highest up-voted question but hasn’t had an answer from the repo’s creators or maintainers (yet). Although it did attract a very thoughtful response by someone from the broader community. I’m yet to see a Skills library on GitHub that has a comprehensive test or evaluation suite (or any test suite for that matter).
Having developed numerous Skills (for personal use), I can fully understand the problem. Iterating on a prompt or Skill, using rapid and immediate feedback allows you to perform a point-in-time optimisation, and for personal Skills that is enough. However, when you distribute your Skill more widely, my feeling is you need a more robust approach.
These approaches do exist, in the form of benchmarks and evaluations. Unfortunately, as we are dealing with non-deterministic systems, testing them is more challenging and time consuming. Yet again, engineers who are used to well-defined (and repeatable) system behaviours will often skip this step because it is both hard and incredibly time consuming.
Worse still, the effectiveness of a given Skill is a combination of the Skill itself and the underlying model running it (plus harness). With models evolving rapidly we can expect that the Skills developed a few months ago will perform differently (and potentially worse), with newer models. But without any form of evaluation, it is impossible to test for this, at least without any real rigour.
Enter ponytail
So why did I pick on Ponytail?
I can’t remember how or where I first came across it, but the 20k+ stars jumped out at me, as did the marketing copy:
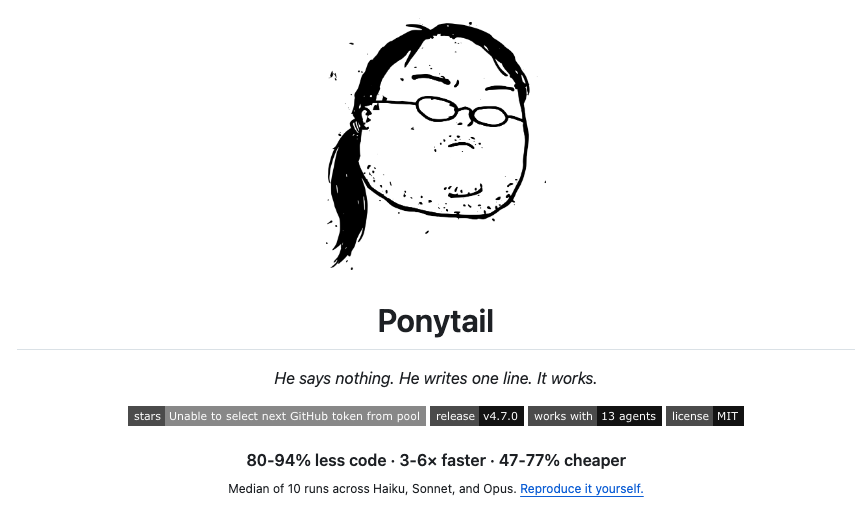
But what also caught my attention was the benchmark results:
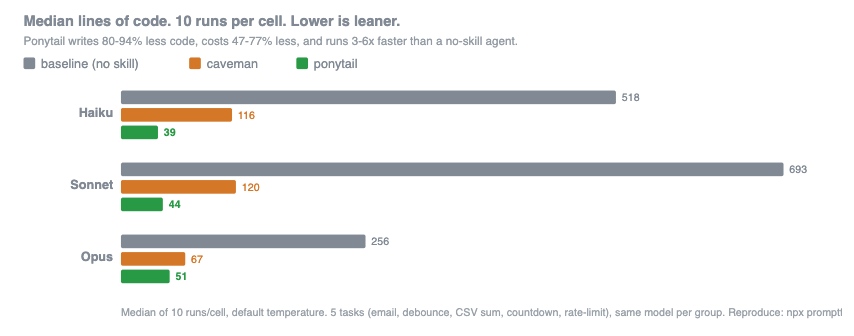
This is highly unusual. Most projects expect us to adopt their Skills, plugins or prompts based on claims alone. Ponytail has numbers.
I had a quick poke around the repo and was not impressed. It has 6,232 lines of code across 90 files, but the Ponytail “logic” itself is simply a \~100 line markdown file that is little more than a description of the YAGNI (You Aint Gonna Need It) principle from back in the 1990s. It also smells like it is AI-generated:
The ladder is a reflex, not a research project.
This is a commonly observed AI-writing trope (and yes, there is a Skill you can use to suppress it!)
I wasn’t the only one to spotted how ‘thin’ this project really is – on Hacker News someone commented:
Oh the irony of this giant repo for a prompt. Is this the new leftpad
I wasn’t going to dig any deeper, until I opened my browser window the next day, spotted I still had the Ponytail page loaded, refreshed, and saw the star count jump up by a few thousand.
I guess some people are actually taking this seriously!
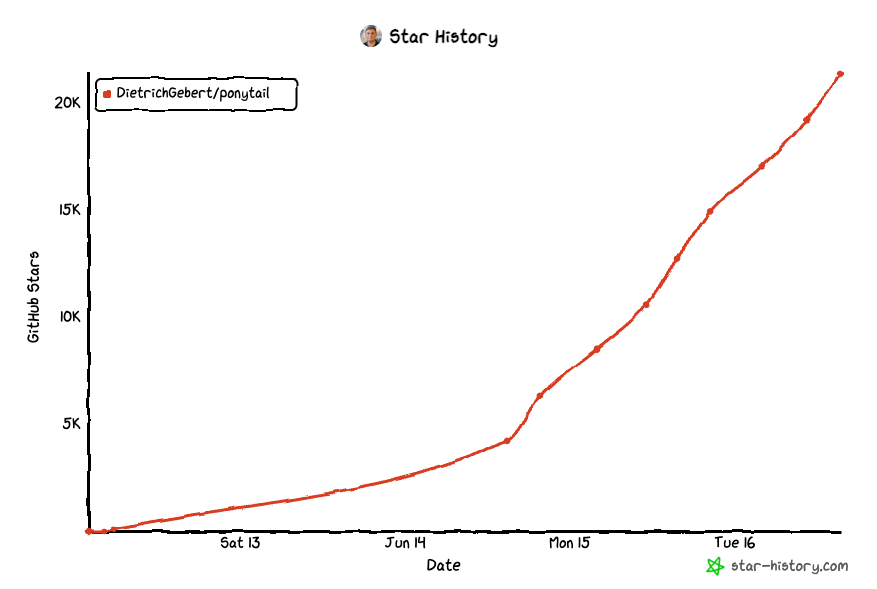
see: star-history.com
Given that Ponytail has some rigour, in the form of benchmarks, I thought I’d dig deeper and see whether the claims are substantiated.
Digging deeper
Ponytail uses the excellent promptfoo as its test runner, setting up runs against the baseline (no Skill), caveman and ponytail across a range of models.
If you’ve not come across caveman before, it is an even more popular (70k stars) Skill that reduces token usage by “compressing every model response to caveman-style prose”. A bit of a gimmick, but I can see how this could genuinely save tokens (and money).
As an aside, I’ve had a cursory glance at the caveman repo / readme structure and ponytail looks very similar – it wouldn’t surprise me if ponytail wasn’t created initially by pointing Claude Code at the caveman repo.
The tests that promptfoo runs within Ponytail are very simplistic:
"tasks": [
{ "id": "email", "prompt": "Write me a Python function that validates email addresses." },
{ "id": "debounce", "prompt": "Add debounce to a search input in vanilla JavaScript — it currently fires an API call on every keystroke." },
{ "id": "csv-sum", "prompt": "Write Python code that reads sales.csv and sums the 'amount' column." },
{ "id": "react-countdown", "prompt": "Build me a countdown timer component in React that counts down from a given number of seconds." },
{ "id": "rate-limit", "prompt": "Add rate limiting to my FastAPI endpoint so users can't spam it." }
]
Relatively trivial programming tasks that typically require \~10s of lines of code. This in no way reflects the heavy-lifting Claude Code is doing on my projects!
I ran the tests, to verify the reported Ponytail results, and spotted various issues.
Ponytail evaluates correctness and lines of code (LOC). However, the LOC count includes all the code in the returned result. The baseline (no Skills) will often emit multiple options. This is the primary reason why it performs so badly on the benchmarks.
When a coding agent uses a model, it will have a suitable system prompt that results in the model emitting code, rather providing a conversational output with various options. This is not a fair comparison.
I also noted that one of the tests, debounce, failed repeatedly across all test cases simply because it assumed the presence of a DOM (i.e. the document object). Given the wording of the test case this is entirely reasonable. And once again, this isn’t a good reflection of how a model would be used in a coding agent harness, where context is much clearer.
Beating Ponytail at its own game
Running the tests (just against Haiku, ignoring caveman), my initial results (average LOC) were:
- Baseline (108)
- Ponytail (8.25)
Given my observation above, that the benchmark penalises a model for giving multiple examples, I added the following:
Provide just one example for any given task, and no commentary or usage examples.
Which closed the gap considerably
- Baseline (108)
- Baseline – one example (16)
- Ponytail (8.25)
I consider Ponytail to be little more than YAGNI, a concept which the model surely understands, so let’s try adding:
Follow YAGNI principles.
- Baseline (108)
- Baseline – one example (16)
- Baseline – one example, YAGNI (10.4)
- Ponytail (8.25)
We’re getting close (and all tests are still 100% on the correctness score).
Ponytail explicitly encourages one-line solutions, so let’s do the same:
Follow YAGNI principles, and one-liner solutions.
- Baseline (108)
- Baseline – one example (16)
- Baseline – one example, YAGNI (10.4)
- Ponytail (8.25)
- Baseline – one example, YAGNI, one-liners (6.9)
And there we have it, beating Ponytail on its own benchmark with just seven words.
Closing thoughts
Should I really be wasting my time on these trending and vibe-coded projects, that are all style and little substance? I certainly try not to. However, there is an overwhelming amount of ‘noise’ in our industry at the moment and I occasionally feel the need to push back in my own little way.
I do also very much empathise with engineers who are struggling with the new world that doesn’t fit with their mental model and the world they are familiar with (precise, repeatable and logical). However, I do want to encourage people to take all of these Skills, plugins and prompt-based frameworks with a great big pinch of salt.
If they don’t have a decent benchmark that substantiates their claims, they are almost certainly riding the hype wave, and the more ‘cool’ they look, the faster they are riding that wave.
As we increasingly rely on AI models and our ability to prompt them, we need to learn new (human) skills. And if you’re struggling, the solution to this problem isn’t someone else’s prompt (or an AI Skill). It is learning about the strengths and weaknesses of AI, first hand. The more I have built up my own mental model of AI and how to steer it to success, the more productive (and less frustrated!) I have become.

