
It is quite common for blogs, or news / content distribution websites, to organise their content around categories of tags. The hope is that a visitor might enjoy the article they are currently reading, be encouraged to locate similar articles and read those next. This sounds good in practice, however, through website analytics, I discovered that in our case only 0.5% of visitors, who finished reading a given article, actually proceeded to navigate to another one.
I decided to try an alternative approach, using OpenAI embeddings to find similar articles, giving a much more tailored ‘read next’ experience. As a result, I found the number of people who read a subsequent article increased by a factor of x4. This article explores the challenge of organising blog content, the topic of word embeddings, some funky t-SNE visualisations of the blog and how a simple recommendation system boosted engagement.
Categories or tags? How to structure a blog
The Scott Logic blog (where this article is published) has around 1,000 articles. Our analytics show that the vast majority of visitors arrive on this site via organic Google search. It is our hope that by structuring the blog content in some way, a visitor might enjoy the first article that they read and continue to read something else.
We’ve tried various ‘standard’ techniques for organising the articles into some sort of logical structure, including:
- Categories - where articles are grouped into a small number of ‘top level’ categories. This seems simple in practice, but has a few challenges. Some articles seem to belong in multiple categories, some categories are too big and others too small. We found ourselves constantly re-categorising and evolving this structure - and recently we pretty much gave up, categorising everything as simply “Tech”.
- Tagging - articles are given a number of free-form tags by the author. Again, sounds simple, however it lacks consistency with different authors creating their own taxonomies. Also, presenting the user with a vast array of tags can be overwhelming - you could of course use a tag cloud, if you like the retro feel!
We never put much stock in either of this approaches, primarily because you are making the end user do all the work, they have to actively choose a tag or category, then find something that piques their interest.
Our preferred approach was to provide ‘read more’ suggestions at the end of each article, based on a couple of principles; first, don’t hassle the visitor until they have read the article that they initially landed on - no point in distracting them before they are genuinely engaged. Second, select a couple of targeted articles that are closely related to the one they have just read and present these as a ‘read more’ section. In theory, this is less work for the user.
Unfortunately, we didn’t have a good mechanism for determining which articles were closely related, so instead just presented a couple of articles from the same category.
Measure, measure, measure
Once I learn about embeddings I immediately got excited about the idea of using this to make more targeted recommendations. However, before implementing this funky new AI-driven feature, I decided to measure the effectiveness of the current approach. I don’t want to just make recommendations that I feel are better, I want to make a measurable difference.
Our standard blog template, when viewed on desktop, has a list of categories on the right-hand side, and recommends two ‘read more’ articles at the end of the article. I set up a few events within Google Analytics, and discovered the following:
- Only 0.04% of visitors clicked on a category link
- On average 35% of visitors read to the end of and article
- And of these, 0.5% will navigate to one of the two recommended ‘read more’ articles
The first result really surprised me. While I don’t think blog categories are a terribly useful tool for increasing engagement, I wasn’t expecting quite so few clicks. Perhaps we should get rid of categories altogether?!
Finding out that 35% of article visits result in the visitor reading to the end was a fantastic result, I’ve looked at industry metrics elsewhere and this appears to be quite a high number. There are some articles on the blog that far exceed this figure, for example, a recent article on Performance Testing with J-Meter has a 65% read rate.
Finally, 0.5% (of visitors who have read an article) click on a subsequent article and keep reading. Not a terribly impressive result.
In brief, the vast majority of visitors to this blog discover an article via organic search, a decent number will read that article in its entirely, then most will leave the blog immediately after.
Back to the task at hand, our preferred approach to increasing engagement is to provide targeted and relevant ‘read more’ recommendations. My goal was to use OpenAI embeddings to improve the relevance of these recommendations and ‘push up’ this 0.5%.
Word embeddings
Neural networks are a popular tool for building recommendation systems and a popular choice for text-based data is Word2Vec, which is a relatively simple network that is useful for understanding what embeddings (or word vectorisation as it is sometimes called) are.
Word2vec model is a simple neural network model with a single hidden layer. The primary purpose of this model is text generation, predicting the next few words for a given sentence. However, in this instance, we’re not interested in the model output, instead we are interested in the data encoded in the hidden layer. Once trained, this hidden layer can be used to encode a word as a vector, a process termed word embedding.
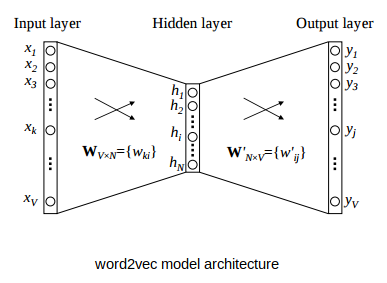
Image from Analytics Vidhya
An important feature of this embedding is that words which are close to each other in vector space have similar meanings (e.g. mum and mother), i.e. it is not just some arbitrary encoding. For a really good primer on Word2Vec I’d recommend this article.
## OpenAI Embeddings
OpenAI was made famous for GPT-3, a new and advanced language model. It is notable for its versatility, rather than train for a specific task, you simply ‘show it’ the task and it ‘learns’ immediately, as an example see my previous post on using GPT-3 to create narrative dashboards.
A few weeks ago OpenAI announced an embeddings API (https://openai.com/blog/introducing-text-and-code-embeddings/), which uses a descendant of GPT-3 to map text to a high-dimensional vector space, providing an embedding for an entire passage of text. Again, it exhibits the same properties as word embeddings, passages of text that concern similar topics are clustered.
With the most advanced GPT-3 model, DaVinci, each vector has 12,288 dimensions!
Providing recommendations via GPT-3 embeddings
Using this API to provide recommendations was really quite straightforward. The first step was to feed the ~1,000 articles into the API, in order to fetch the 12k dimensional embedding vector for each. Then, for each article, I found its two closest neighbours, via cosine similarity. Simple!
An interesting byproduct of computing the embeddings for each article is that it is possible to visualise the blog content. There isn’t an easy way to visualise such a high-dimensional vector space, so some technique needs to be used to reduce the number of dimensions down to something more manageable, typically two or three. A popular approach for this is t-distributed stochastic neighbor embedding, or t-SNE for short. This technique reduces dimension, whilst maintaining structure and proximity. If you’ve not used t-SNE before, I’d recommend this article which shares lots of practical examples and advice.
Here are all the posts on the blog, coloured by category …
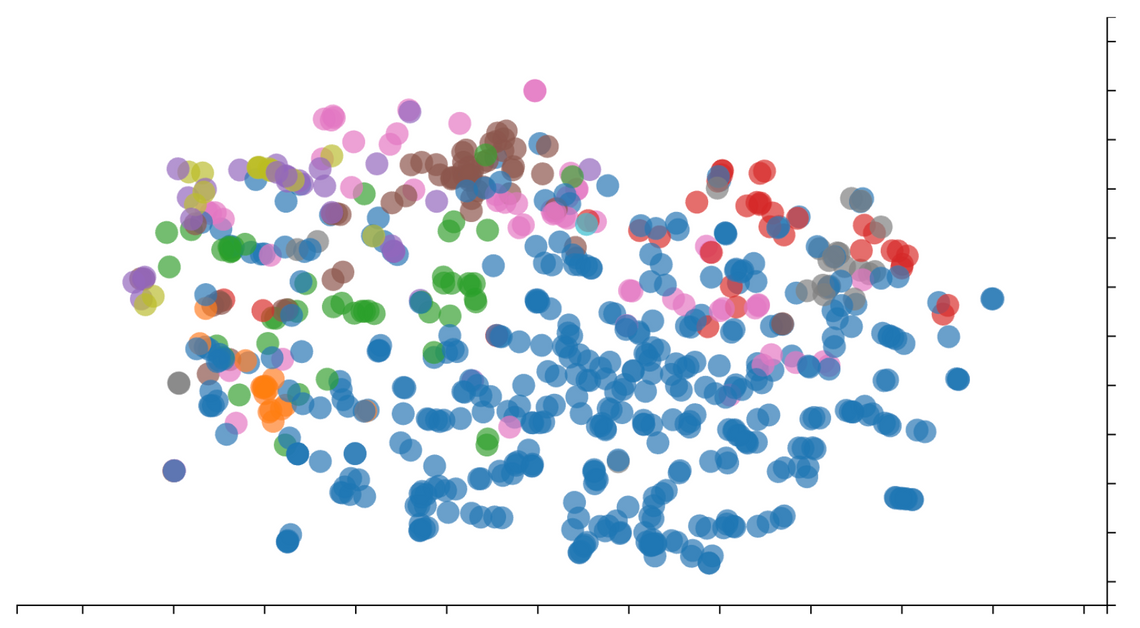
The red dots in the top right are articles within our data engineering category, these overlap quite a bit with the grey dots which represent articles in the cloud category (no great surprised, the topics are very closely related). Elsewhere in this “cloud”, brown at the top are from the delivery category, and the great big block of blue is the somewhat ambiguous Tech category which we tend to use for pretty much everything!
If we zoom in a little closer …
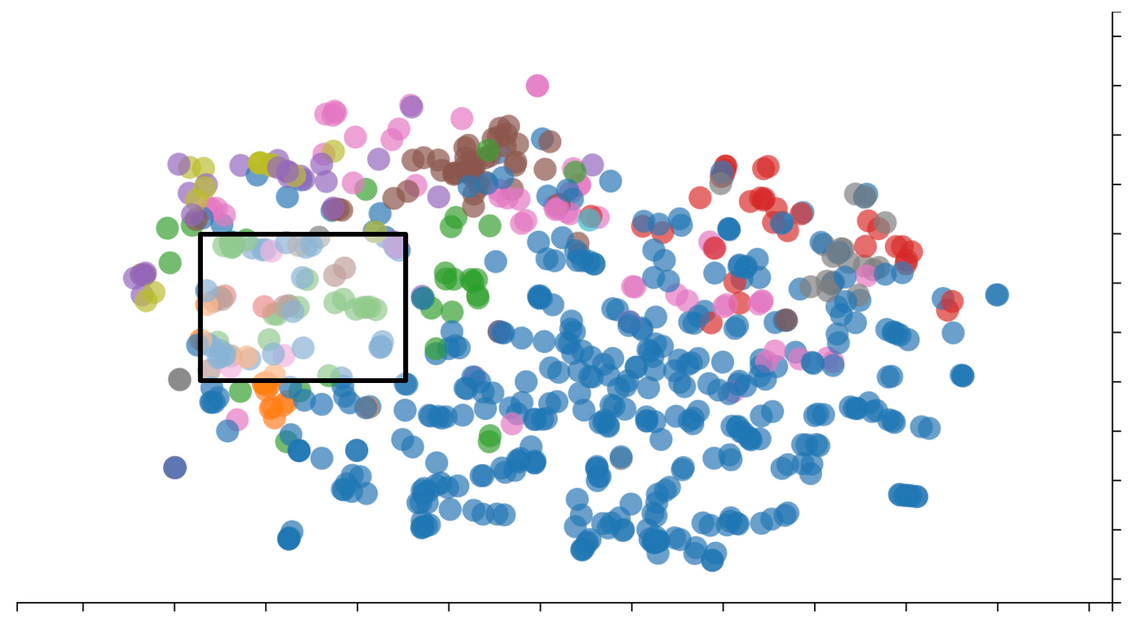
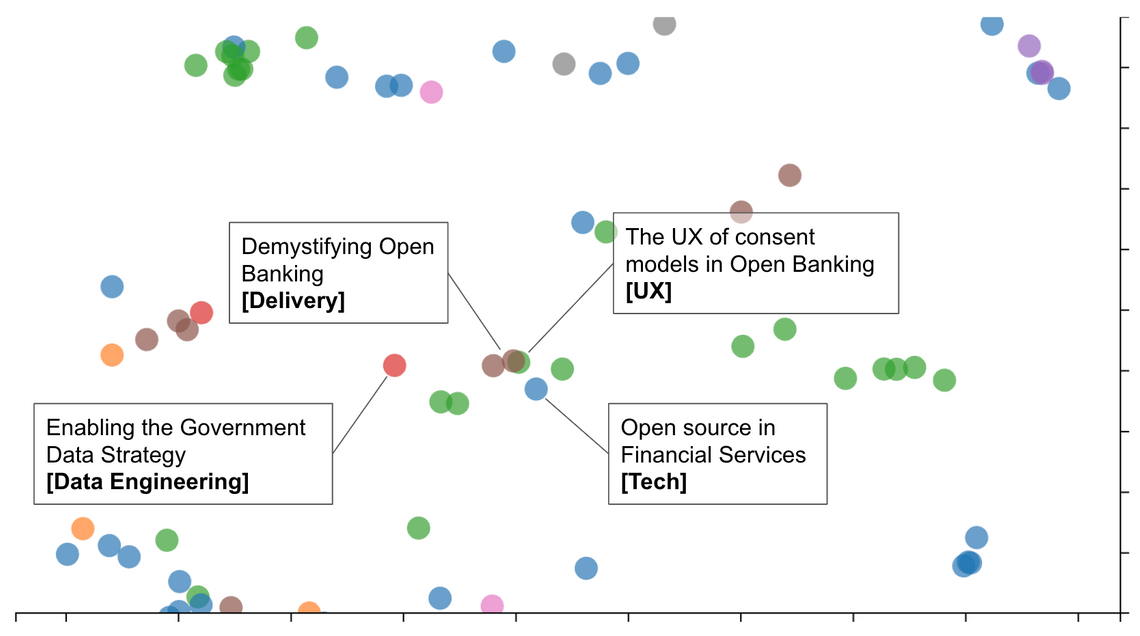
Here we can see a cluster of a few articles, which belong to different categories, yet explore similar themes. This demonstrates the power of embeddings to identify similar content.
Also, from navigating this “cloud” of articles I found a number that were clearly mis-categorised. I could potentially use this tool to improve our categorisation, however, as observed above, very few people click the category links anyway 🤷♀️
Conclusions
With this new system in place, using embeddings to provide more targeted recommendations, I continued to measure how many visitors clicked on one of the ‘read more’ links. After one week I observed a four-fold (x4) increase in clicks. A pretty good result!
The new OpenAI embeddings API is a fantastic tool, and makes tasks such as this so much easier - no need to host and train your own model. There is so much you can potentially do with these embeddings, recommendations, auto-categorisation, I’m sure it would do a fantastic job of detecting plagiarised text too - the technique of copying an essay and changing the odd word isn’t going to do much to disguise the inherent similarity.
Anyhow, for now, I’ll leave you to explore the next post on this blog - no doubt another interesting article on AI 😉